
統計
- ロードバランサーへの148,084,883 HTTPリクエスト
- 36,095,312のうち真のページ読み込み
- 833,992,982,627バイト(776 GB)HTTPトラフィック送信
- 286,574,644,032バイト(267 GB)の受信トラフィック
- 送信されたトラフィックの1,125,992,557,312バイト(1,048 GB)
- HTTPクエリの334,572,103 SQLクエリ
- Redisサーバーへの412,865,051リクエスト
- タグハンドラーへの3,603,418リクエスト(個別のサービス)
- 558,224,585ミリ秒(155時間)がSQLクエリの処理に費やされました
- 99,346,916ミリ秒(27時間)Redisサーバーからの応答を待機するのにかかった
- タグによるリクエスト処理で132,384,059ミリ秒(36時間)が経過しました
- 2,728,177,045 ms(757時間)ASP.Netスクリプトが機能しました
これらの数値を取得する方法については必ず投稿する必要がありますが、これらの統計(トラフィックを除く)はHTTPログのおかげでのみ計算されます。 一日に何時間もかかったのですか? 魔法と呼んでいます。 ほとんどの人は「マルチコアプロセッサを備えた複数のサーバー」と呼んでいますが、私たちはそれを魔法に帰します。 Stack Exchangeは、次のハードウェアで実行されます。
- 4 MS SQLサーバー
- 11 IIS Webサーバー
- 2台のRedisサーバー
- タグ処理に関与する3台のサーバー(たとえば、リクエスト/質問/タグ付き/ c ++など、タグに関連するすべてのもの)
- 3つのElasticSearchサーバー
- 2つのロードバランサー( HAProxy実装)
- 2台のスイッチ(それぞれNexus 5596 + Fabric Extendersに基づく)
- 2 Cisco 5525-X ASAファイアウォール
- 2台のCisco 3945ルーター
この美しさがどのように見えるかは、最初の写真(上記)で見ることができます。
私たちは単にサイトをホストしているだけではありません。 最も近いラックは、仮想化(vmware)および補助インフラストラクチャ用のサーバーです。これらは、展開マシン、ドメインコントローラー、監視、管理者用の追加データベースなど、サービスの動作に直接影響しません。 上記の2つのSQLサーバーは最近までバックアップサーバーでしたが、読み取り専用のクエリに使用されるようになったため、長期間データベースの負荷を考慮することなく拡張を続けることができます。 このリストの2つのWebサーバーは、開発および周辺タスク用に設計されているため、トラフィックをほとんど消費しません。
設備について
現時点で何かが発生し、インフラストラクチャのすべての冗長性がなくなったと想像すると、スタックエクスチェンジ全体がパフォーマンスを低下させることなく次の機器で動作できます。
- 2台のSQLサーバー
- 2台のWebサーバー(おそらく3台ですが、2台で十分だと思います)
- 1台のRedisサーバー
- タグ処理用の1台のサーバー
- 1個のElasticSearchサーバー
- 1つのロードバランサー
- 1スイッチ
- 1 ASAブランドマウアー
- 1台のルーター
実際に検証するために、いくつかのサーバーの切断を試行する必要があります。 :)
以下は、平均的なハードウェア構成です。
- SQL Serverは384 GBのRAMと1.8 TBのファイルストレージ(SSD)で実行されます
- Redisサーバーは、96 GBのRAMを搭載したマシンで実行されます
- ElasticSearchサーバー-196 GB RAM
- タグ処理サーバーには、購入可能な最速のプロセッサーが必要です。
- スイッチ-ポートあたり10 GB。
- Webサーバーにも違いはありません-32 GBのRAM、2つのクアッドコアプロセッサ、およびそれぞれに300 GBのSSDストレージ。
- 2x10 Gbit / sネットワーク(SQLなど)を持たないサーバーは、4つの1 Gbit / s接続で接続されます。
20Gbpsは多すぎるように見えますか? はい、たとえば、ピーク時のSQLサーバーは100-200 Mbit / sを超えるネットワークをロードしませんが、バックアップ、トポロジの再構築を忘れないでください-これはいつでも必要になる可能性があり、その後ネットワークは完全に使用されます。 このような量のメモリとSSDは、このチャネルを完全にダウンロードできます。
保管
現在、SQLには約2 TBのデータがあります(18個のSSDの最初のクラスターで1.06 / 1.16 TB、2番目のクラスターで0.889 / 1.45 TB、4つのSSDで構成されています)。 クラウドについて考える価値はあるかもしれませんが、現在はSSDを使用しており、データベースへの書き込み時間は文字通り0ミリ秒です。 メモリー内にデータベースがあり、その前に2つのキャッシュレベルがある場合、Stack Overflowの読み取り/書き込み比率は40〜60です。はい、そうです、データベースの時間の60%を書き込みます。
Webサーバーは、RAID1で320 GB SSDを使用します。
ElasticSearchサーバーには300 GB SSDも付属しています。 上書きとインデックス作成が頻繁に行われるため、これは重要です。
SANについても言及しませんでした。 これは、24個のSAS 10Kディスクと2x10 Gb / s接続を備えたDELL Equal Logic PS6110Xです。 VmWare仮想サーバーのストレージとしてクラウドとして使用され、サイト自体には接続されていません。 このサーバーがクラッシュした場合、サイトはしばらくの間それについても知りません。
次は?
これで何をしますか? より多くのパフォーマンスが必要です-これは私たちにとって非常に重要です。 11月12日、ページは平均28ミリ秒でロードされました。 ダウンロード速度を50ミリ秒以下に維持しようとしています。 その日の人気のあるページの平均負荷統計は次のとおりです。
- 回答のある質問ページ-28ミリ秒(2970万リクエスト)
- ユーザープロファイル-39ミリ秒(1.7ミリ秒のリクエスト)
- 質問リスト-78ミリ秒(110万リクエスト)
- ホームページは65ミリ秒(100万リクエスト)で、非常に遅いです。 すぐに修正します。
タイミングを記録することにより、ダウンロード速度を監視します。 これにより、非常に視覚的なスケジュールを作成できます。
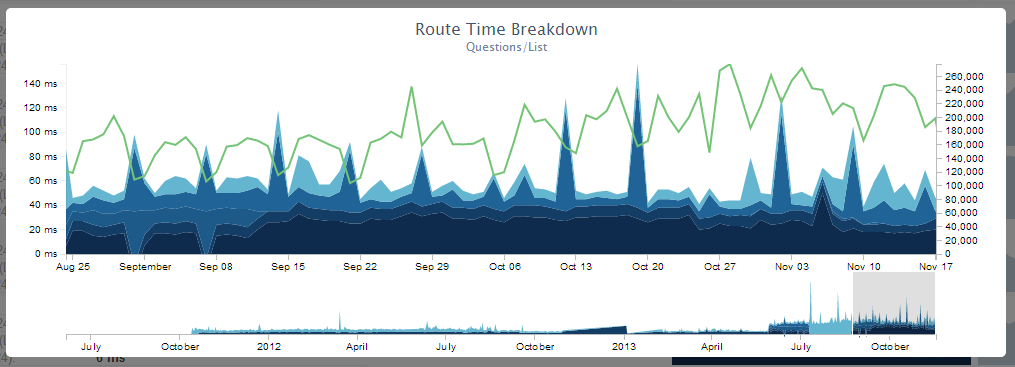
将来のスケーラビリティ
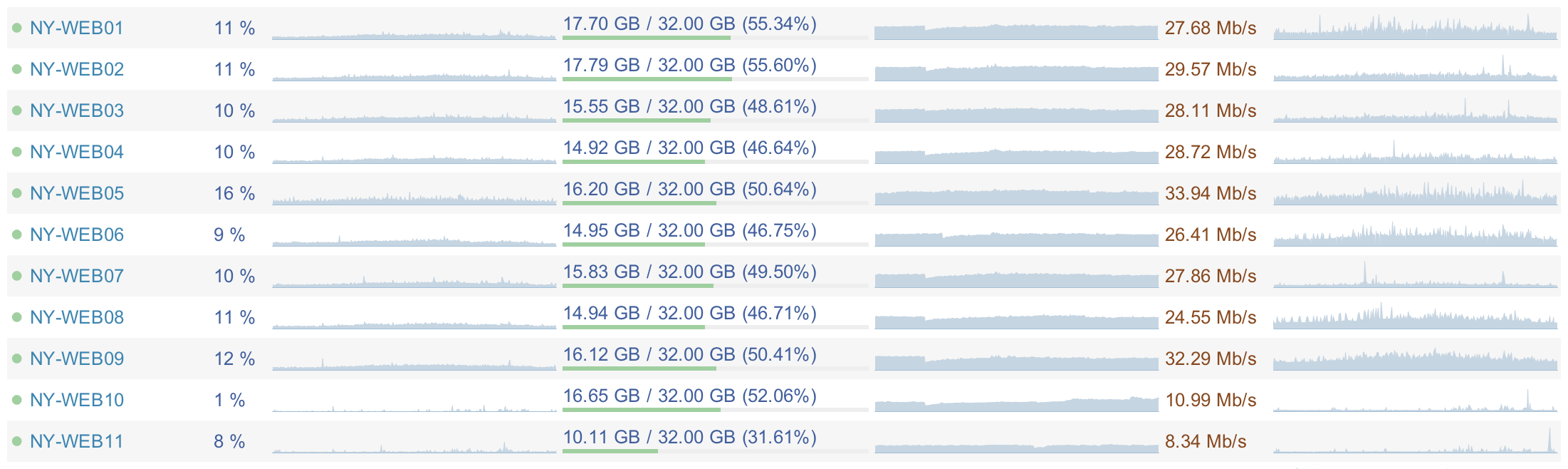
明らかに、すべてのサービスが低負荷で動作するようになりました。 Webサーバーは、プロセッサの平均5〜15%、15.5 GBのRAM、および20〜40 Mbpsのネットワーク帯域幅を消費します。 データベースサーバーの平均プロセッサ負荷は5〜10%、RAMは365 GB、ネットワーク帯域幅は100〜200 Mb / sです。 これにより、完全に開発することができ、非常に重要なことは、負荷の増加(コードのエラーまたはその他の障害)が発生した場合に落下しないようにします。
Opserverのスクリーンショットを次に示します。
負荷が非常に低い主な理由は、コードの効率です。 この投稿は別の記事に捧げられていますが、効果的なコードは、将来のハードウェアのスケーリングにとって重要な場所です。 あなたがしたことはしたが、すべきではなかったすべてのことは、あなたがそれをまったくやらなかった場合よりも多くの費用がかかります-同様のルールが非効率的なコードに適用されます。 コストは次のように理解されます:電力消費、ハードウェアのコスト(より多くのサーバーが必要、またはより強力でなければならないため)、より複雑なコードを実現しようとしている開発者(ただし、率直に言って、最適化されたコードは必ずしも容易ではない)ページ-別のページをロードするのを待たないユーザーの反応で表現されていること...または、もうあなたに来ません。 効率の悪いコードの価格は、思っているよりもはるかに高くなる可能性があります。
そのため、今日、Stack Overflowが現在のハードウェアでどのように機能するかを知りました。 次回は、なぜ急いでクラウドに移行しないのかを学びます。