
スクリプトや非ネイティブ言語(JavaやHTML5など)のみで記述されたAndroidアプリケーションでも、最終的にはランタイムの基本コンポーネントを使用するため、最適化する必要があります。 最適化のアプローチとニーズを説明する良い例は、以下で説明するマルチメディアおよび拡張現実技術を使用するアプリケーションです。 Androidプラットフォーム(スマートフォンおよびタブレット)の場合、IntelはさまざまなタイプのAtomプロセッサーとSSSE3レベルのベクトル化を使用し、通常はハイパートレッドを備えた2つのコアを使用します。 iOnRoad -iOnRoad。
問題の声明
iOnRoadは、安全運転を支援する拡張現実スマートフォンアプリです。 GPS、センサー、スマートフォンのビデオカメラ、および最新のコンピュータービジョンアルゴリズムを使用して、アプリケーションはドライバーに車線を離れるだけでなく、他の車や障害物との衝突の可能性について警告します。 このアプリケーションは非常に人気があり(100万回以上ダウンロードされています!)、さまざまな賞を受賞しましたが、2つの欠点しかありませんでした。1.隣の車の酔っぱらい運転手や美しい女の子、およびあなたの車が続くときに道路に投票する他の興味深い仲間の旅行者については警告しません。
2.スマートフォンを30分から40分以上電源に接続しないと元のバージョンを使用できなかったため、バッテリーが完全に消耗したため、電力消費を含む最適化が必要です。
現時点では、欠点は1つだけです。 最初の
そのため、アプリケーションはリアルタイムで動作し、YUV420 / NV21形式の各ソースフレームをスマートフォンのカメラからRGB形式に変換してから、さらに処理します。
 当初、この変換を実装する関数はプロセッサリソースの最大40%を使用していたため、さらなる画像処理の可能性が制限されていました。 したがって、最適化の必要性は緊急のように思われました。
当初、この変換を実装する関数はプロセッサリソースの最大40%を使用していたため、さらなる画像処理の可能性が制限されていました。 したがって、最適化の必要性は緊急のように思われました。
既存の最適化された唯一の関数は、IPPパッケージ( Intel Integrated Performance Primitivesライブラリ )のYUV420ToRGB関数ですが、iOnRoadでサポートされる入力形式と出力形式の必要な組み合わせはありません。 さらに、マルチスレッドではありません。
したがって、必要な変換を実装する新しい最適化されたコードを記述することが決定されました。
YUV420 / NV21からRGBへの変換
YUV420 / NV21形式には、3つの8ビットコンポーネント-輝度Y(白黒)と2つのカラーコンポーネントUおよびVが含まれます。
標準のRGB形式で4つのピクセルを取得するには(各ピクセルに3つの色成分を使用)、Yの各4つの成分には、対応する成分UとVのペアが1つだけ必要です。
上の図では、対応する4倍線Yとそれらに対応するUとVのペアが同じ色でマークされています。 この形式(一般にYUVと呼ばれます)は、RGBを2倍に圧縮します。
YUVからRGBへの変換-テーブル(ルックアップテーブル、LUT)を使用した整数アプローチ
YUVからRGBへの変換は、単純な線形式に従って実行されます。 浮動小数点数への変換を回避するために、iOnRoadは次の有名な整数近似を使用しました。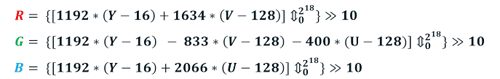
2 16を超えるこの式を使用した計算の中間結果は、ベクトル化をさらに議論するための重要なポイントです。
いわゆるルックアップテーブル(LUT)がiOnRoadのスカラー計算に使用されました:すべてのコンポーネントY、U、およびVは8ビットであるため、上記の式の乗算は事前に計算でき、32ビットの結果は5つに格納されます256入力のテーブル。
YUVからRGBへの変換-SSE固定小数点コンピューティングを使用する一般的な考え方
SSEには、LUTを操作するためのベクター収集命令がありません。 16ビットのパック数値のベクトル乗算の使用は、スカラーLUT操作と後続のパッケージングの組み合わせよりも高速に思えます。 ただし、予想される中間結果は2 16を超える可能性があるため、単純な16ビットSSE乗算(PMULLW)は使用できません。 SSEには、完全な16ビット乗算と32ビット中間結果の右シフトを必要な16ビット丸めに結合するPMULHRSW命令があります。 この命令を使用するには、オペランドを前に左にシフトして、最終結果の有効ビットの最大数を指定する必要があります(特定のケースでは、13ビットの最終結果を取得できます)。手動のSSEコードを記述する手段としての組み込み関数(組み込み関数)
アセンブラを使用して手動のSSEコードを記述しないようにするため、既知のすべてのC / C ++コンパイラ(MS、GNU、Intel)には、組み込み関数と呼ばれる特別なAPIのセットがあります。プログラマーの観点から見ると、組み込み関数は通常のC / C ++関数のように見え、動作します。 実際、SSEの1つのアセンブラー命令のラッパーであり、ほとんどの場合、この命令としてのみコンパイルされます。 組み込み関数を使用すると、同じパフォーマンスインジケーターでアセンブリコードをすべての複雑さで記述する必要がなくなります。
たとえば、上記のPMULHRSW命令を呼び出すには、Cコードで組み込み関数_mm_mulhrs_epi16()を使用しました。
各SSE命令には対応する組み込み関数があるため、組み込み関数を使用して必要なSSEコードを完全に記述することができます。
YUVからRGBへの変換-SSE固定小数点コンピューティングの実装
このプロセスは、16個の8ビットYと8個の8ビットペア(U、V)の2つのサービングをロードすることから始まります。その結果、このデータは16の32ビットRGBピクセルに変換されます(上位バイトが0xffに設定されている場合はFRGBの形式で)。
16の8ビットYから飽和した8ビット減算の操作を使用して16が減算されるため、ネガティブの結果を確認する必要はありません。
8ペア(U、V)は、Yの値が16の2行を「提供」します。
入力データをアンパックするには、シャッフル操作が使用されます。この場合、次の2つのサービングが使用されます。
- 8 x 16ビットYの2 xセット。
- 4つの16ビットダブルUの最初のセット。
- 4つの16ビットダブルVの最初のセット。
以下は、一部の製造の詳細図です。
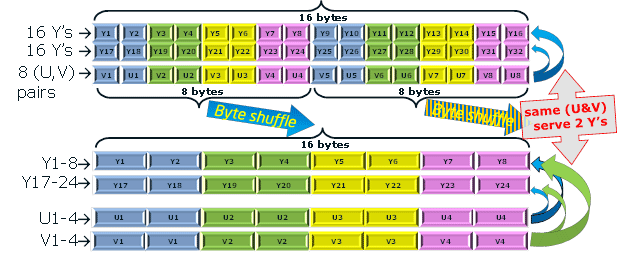
UとVを使用する前に、16ビット_mm_sub_epi16()命令を使用して、それらから128が減算されます。
減算後、Y、U、Vの8つの16ビット値はすべて、_mm_mulhrs_epi16()に最適に適合するように左にシフトされます。 この命令は、適切にパックされたオッズで使用されます。
注:上記のこれらの準備手順(減算とシフト)は、スカラーアルゴリズムのLUT操作の代わりに使用されます。
_mm_min_epi16()および_mm_max_epi16()を使用して、0〜2 13 -1(8191)に制限された最終16ビット値を取得するために、乗算結果が要約されます。
すべての計算が完了すると、R、G、Bの個別にパックされた16ビット値の形式で結果が得られます。
それらをFRGB形式(FはiOnRoadの要件に応じたユニットで満たされたアルファチャネル)に再パックすることは、2つのステップで実行されます。
最初のステップでは、16ビット<0xff00>で埋められた追加のレジスタを使用して、R、G、およびBの16ビットの個別の値を16ビットFRおよびGBに再パッケージ化します。 この再パッケージ化フェーズは、図に示すように、論理的な左シフトと右シフト、および論理OR / AND演算を使用して実行されます。

2番目のステップでは、中間結果FRおよびGBが、アンパック命令_mm_unpacklo_epi16()および_mm_unpackhi_epi16()を使用して最終的にFRGBにパッケージ化されます。
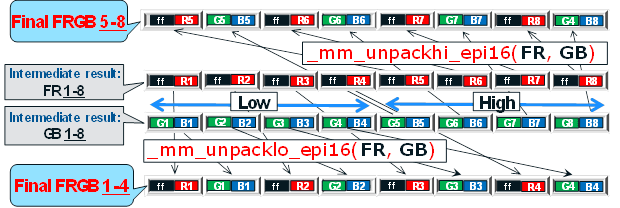
SSEの組み込みベクトル関数を使用してYUVからRGBへの変換を実装する上記のコードは、事前計算テーブル(LUT)を使用した元のスカラーコードと比較して4倍の加速を提供します。
並列化にCILK +を使用する:簡単
スマートフォンとタブレットで使用されるAtomプロセッサのすべてのバージョンには、少なくとも2つのコア(少なくとも論理コア-HT)があり、将来はさらに多くのコアが搭載されるため、アルゴリズムの並列化は非常に重要です。並列化への最も単純なアプローチは、CおよびC ++のインテルコンパイラーのCILK +拡張機能で実装されています(有名なTBBはC ++でのみ動作します!) 最も単純な並列化演算子cilk_for(標準のC / C ++言語ではなく、YUVからRGBへの外部変換に使用)は、デュアルコアClover Trail +プロセッサーのパフォーマンスを2倍に向上させます。
CILK +並列化と組み合わせてSSEの内部ベクトル化機能を使用すると、全体で8倍の加速が得られます。
ベクトル化のためのCILK +の使用:配列表記、関数マッピング、および削減
CILK +には、配列表記と呼ばれる非常に重要な拡張機能が含まれています。これにより、ベクトル化の効率が大幅に向上すると同時に、コードの可読性が向上します。配列表記はプラットフォームのスケーラビリティを提供します。128ビットAtom、256ビットHaswell、および512ビットMIC / Skylakeの両方で同じコードを最適にベクトル化できます-内部SSE / AVX関数に基づくコードとは異なります:特定のプラットフォームごとに手動で書き換える必要があります。 配列表記を使用すると、配列のいわゆるセクションを関数の引数(関数マッピング)として使用したり、縮小(合計、最大/最小検索など)したりできます。
CILK +配列表記の例
2つのコードスニペットを見てください。複雑な定義と開発を伴うソースコード(実際のアプリケーションから取得):

そして、配列表記法、関数のマッピングとリダクションのセクションで構成されるCILK +要素との単一行の組み合わせ:

これらの2つのオプションは機能的な観点からはまったく同じですが、CILK +バージョンは6倍高速に動作します!
結論と開発者への呼びかけ
内部SSE機能(SSSE3レベル)は、Atom / Intelデバイスのアプリケーションパフォーマンスを大幅に向上させます。CILK + Array Notation(Intelコンパイラに組み込まれている)を使用すると、自動ベクトル化の大きな機会が得られます。
CILK +は、Atom / Intelデバイス上のアプリケーションを並列化する優れた方法です。
新しい「アンドロイド」の世界のAtom / Android開発者への推奨事項:SSEとCILK +を使用してマルチメディアアプリケーションとゲームを最適化することをためらわないでください-これらの実績のあるツールは生産性の大きな飛躍をもたらします!
Intelイスラエル、シニアアプライドソリューションエンジニア、Grigory Danovichが執筆。