
私にとって、Getpocket、Readability、およびVkontakteがどのようにページへのリンクを解析し、広告、サイドバー、メニューなしで閲覧できる既製の記事を提供するかは、常に魔法のようなものでした。 しかし、それらはほとんど間違えられません。 そして最近、私たちのプロジェクトで同様のタスクが成熟したので、もう少し掘り下げることにしました。 これは「ホワイト」解析であり、ウェブマスター自身が自発的にサービスを使用しているとすぐに言わなければなりません。
理想的な世界では、ページ上のすべての情報を意味的にマークアウトする必要があります。 賢い人たちは、Microdata、OpenGraph、Article、Nav ...などのタグのような多くの便利なものを考え出しましたが、セマンティクスの観点からウェブマスターの意識に頼るのは急いではいません。 人気サイトのページのコードを自分で見るだけで十分です。 ちなみに、Open Graphは最も人気のある形式であり、ソーシャルネットワークで誰もが美しく見えることを望んでいます。 ネットワーク
タイトルは通常、タイトルまたはogから取得されるため、記事のタイトルと写真の分離は私の投稿の範囲を超えています。また、og:imageから取得されない場合、写真は別のストーリーです。
最も興味深いこと-記事の本文を分離します。
(Googleの従業員からのものを含む)この問題に焦点を当てた非常に科学的な論文があることが判明しました。 さらに、データを抽出するためのテストページのセットを使用したCleanEval競争があり、アルゴリズムは誰がデータをより正確にするかを競います。
次のアプローチが区別されます。
- htmlドキュメントのみを使用したデータ抽出(DOMおよびテキストレベル)。 この手法については、以下で説明します。
- コンピュータービジョンを使用してレンダリングされたドキュメントを使用してデータを抽出します。 これは非常に正確なアルゴリズムですが、最も複雑で大食いです。 たとえば、 www.diffbot.com (Stanfordの男性によるプロジェクト)で、その仕組みを確認できます。
- 全体としてサイトレベルでデータを抽出し、同じ種類のページを比較し、それらの間の違いを見つけます(異なるブロックは基本的に正しいコンテンツです)。 大きな検索エンジンがこれを行っています。
現在、手元にあるHTMLドキュメントが1つだけの記事を抽出する方法に興味があります。 並行して、ページ区切りの記事のリストを含むページを定義する問題を解決できます。 この記事では、最終的なアルゴリズムではなく、方法とアプローチについて説明しています。
ページを解析しますhttp://habrahabr.ru/post/198982/
記事になる候補者のリスト
ページ構造のすべてのマークアップ要素(簡単にするためにdiv )とそれらに含まれるテキスト(ある場合)を取得します。 私たちのタスクは、 div要素のフラットリスト->その中のテキストを取得することです
たとえば、Habréのメニューブロック:
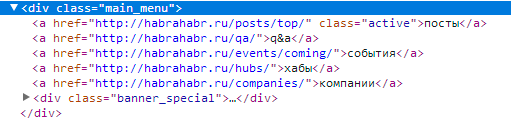
「会社のハブのイベントとイベントを投稿」というテキストを含む要素を提供します
ネストされたdiv要素がある場合、その内容は破棄されます。 子divは順番に処理されます。 例:
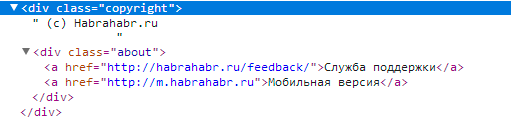
1つのテキスト©habrahabr.ru 、および2番目のサポートサービスモバイルバージョンで 2つの要素を受け取ります
21世紀には、構造(div)をマークアップするために意味的に意図された要素は、テキスト内の段落をマークアップするために使用されず、これはトップ100のニュースサイトに当てはまります。
その結果、平らな木材が得られます。

そのため、記事を分類するセットがあります。 さらに、各要素にさまざまな非常に単純なアルゴリズムを使用して、その中に記事が存在する確率係数を増減します。
DOMツリーは破棄しません。アルゴリズムで必要になります。
繰り返しパターンを見つけます。
DOMツリーのすべての要素で、属性(クラス、id ..)に繰り返しパターンを持つ要素があります。 たとえば、コメントをよく見ると:

繰り返しパターンが何であるかが明らかになります。
- 要素の同じクラスのセット
- idに同じテキスト部分文字列
これらすべての要素とその「子」を悲観します。つまり、見つかった繰り返しの数に応じて特定の低下係数を設定します。
「子供」について話すとき、すべてのネストされた要素(分類セットに分類された要素を含む)が悲観化されることを意味します。 たとえば、コメントテキストを含む要素も分布に該当します。
要素内のプレーンテキストへのリンクの比率。
アイデアは明確です-メニューと列にはしっかりしたリンクがありますが、これは明らかに記事のようなものではありません。 セットの要素を調べて、それぞれの係数を記録します。
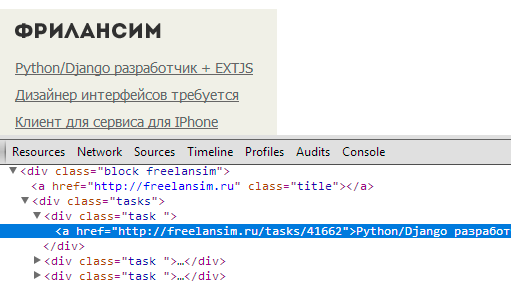
たとえば、Freelanceブロックの要素のテキスト(繰り返しクラスで既にマイナスになっています)、キャッチに対する1に等しいリンクとテキストのugい比率のマイナスを取得します。 この係数が小さいほど、テキストが意味のある記事のように見えることは明らかです。
テキスト要素に対するテキストマークアップの比率
マークアップ(リスト、ハイフネーション、スパン...)のブロックが多いほど、この記事の可能性は低くなります。 たとえば、おそらく尊敬されているSEO企業の広告は、完全なリストであるため、記事にあまり似ていません。 マークアップ対テキストの比率が低いほど優れています。

テキスト内のポイント(文)の数。
ここで、私たちは数値言語学の領域にほとんど入り込みました。 実際には、ヘッダーとメニューには実際にはドットが配置されていません。 しかし、記事の本文にはそれらの多くがあります。
サイト上の新しい素材の一部のメニューとリストが以前のフィルターを介してまだクロールされている場合は、ポイントをカウントして終了できます。 ブロック内のそれらの多くは最高ではありません:

より多くのポイント、より良い、そして私たちはこの要素が記事の誇らしげなタイトルを受け取るチャンスを増やします
同じ長さのテキストを持つブロックの数
同じ長さのテキストを持つ多くのブロックは、特にテキストが短い場合、悪い兆候です。 このようなブロックを悲観しています。 このアイデアは、同様のレイアウトでうまく機能します。
この例では、Habrではなく、このアルゴリズムはより厳密なグリッドでより適切に機能するためです。 たとえば、Habréについてのコメントでは、うまくいきません。
要素内のテキストの長さ。
直接的な相関関係があります-要素内のテキストが長いほど、この記事が表示される可能性が高くなります。

さらに、要素の最終グレードに対するこのパラメーターの寄与は非常に重要です。 記事の構文解析のケースの90%は、この方法だけで解決できます。 以前のすべての調査では、この可能性が95%に上昇しますが、同時にプロセッサ時間の大部分を消費します。
しかし、想像してください:コメントは記事自体のサイズです。 単にテキストの長さで記事を決定すると、混乱が生じます。 しかし、要素がidまたはclassの繰り返しパターンに対して悲観的になるため、以前のアルゴリズムがグラフコメンテーターの翼をわずかに削減する可能性が高くなります。
または別の場合-を使用して作成された重いドロップダウンメニュー
"boilerplate algorithm", "readability algorithm"