
特別な読み取り専用ファイルシステムは、他のすべてが同等であるため、一般的な目的で次の理由で利点があるという意見があります。
- 空き容量を管理する必要はありません。
- ジャーナリングにお金を費やす必要はありません。
- 断片化を心配してファイルを継続的に保存することはできません。
- すべてのメタ情報を1か所に収集し、効果的にキャッシュすることができます。
- 1つのヒープにあるため、メタ情報を圧縮しないことは罪です。
この記事では、目的関数が最小のコストで最大のパフォーマンスを発揮するようにファイルシステムを編成する方法を理解します。
挑戦する
- 1億個の小さなファイル(それぞれ8K以下)。
- 3レベルの階層-100個のトップレベルディレクトリ。各ディレクトリには100個の中間レベルディレクトリがあり、各ディレクトリには100個の下位ディレクトリがあり、各ディレクトリには100個のファイルがあります。
- ランダムファイルのビルド時間と平均読み取り時間を最適化します。
鉄
まず、ディスク:すべての実験は専用の1 Tb Seagate Barracuda ST31000340NSで実行されます。
オペレーティングシステムはWindows XPです。
プロセッサー:AMD Athlon II X3 445 3 GHz。
メモリー:4 GB。
ディスク仕様
実質的な作業を開始する前に、ディスクから何が期待できるかを理解したいと思います。 したがって、ランダムな位置決めとディスクからの読み取り値の一連の測定が行われました。
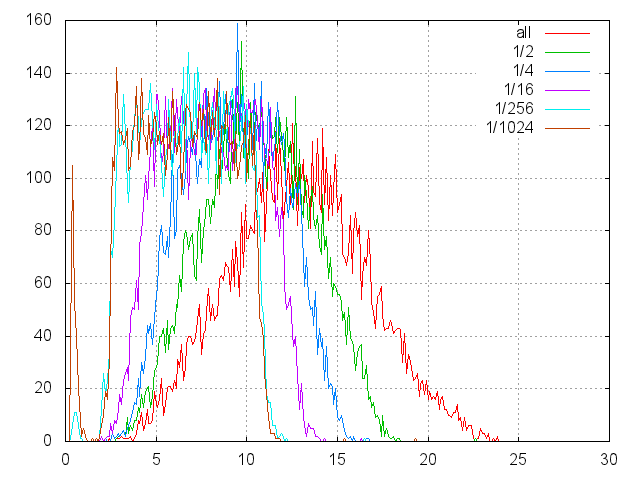
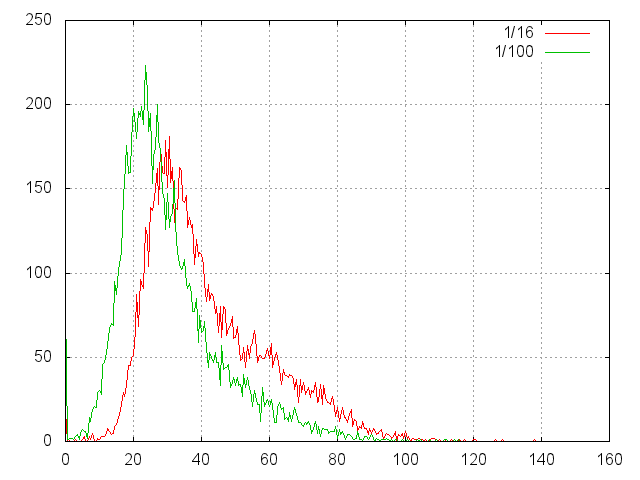
以下のグラフは、任意の位置でのディスクからの読み取り時間のヒストグラムを示しています。 横軸は、位置決めと読み取りの期間を示します。 y軸上-バスケット内のヒット数0.1ミリ秒。
ディスクアクセスは通常の方法で行われました。
- CreateFileを開いて( "\\\\。\\ PhysicalDrive1" ...);
- SetFilePointerによる位置決め。
- ReadFileを介して読み取ります。
一連の測定が行われ、各シリーズで10,000が行われました。 各シリーズはその色でマークされています:
- all-位置決めはディスク全体に行き渡ります。
- ½-下半分のみなど
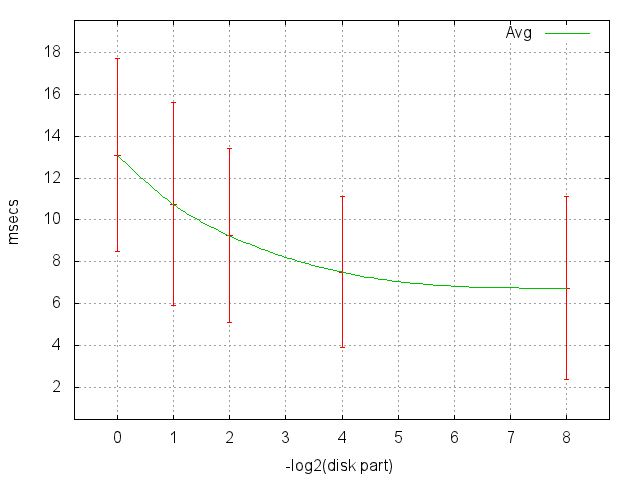
そして、ここにマットが示されています。 前のグラフからの期待値と誤差、対数目盛の横軸、たとえば1/16は4(1/2 1/2)に対応します。
どのような結論を導き出すことができますか?
- 最悪の場合(ランダム検索)、1回の読み取りの期待値は13ミリ秒です。 つまり、このディスクから1秒あたり80を超えるランダム読み取りを行うことはできません。
- 1/256では、最初にキャッシュにヒットがあります。
- 1/1024で、具体的な読み取り数〜1%がキャッシュに入り始めます。
- 1/256以上は1/1024と違いはありません。頭の動きはすでに小さすぎます。加速と(大部分)落ち着きが見られるだけです。
- スケーリングする能力があります。つまり、部分的に満たされたディスクで実験を行い、結果を自信を持って推定することができます。
NTFS
ディスクのサイズのファイルを作成して、それを操作する時間特性を取得してみましょう。 これを行うには、ファイルシステムのサイズに見合ったファイルを作成し、通常の_fseeki64 / freadを使用してランダムな場所で読み取ります。
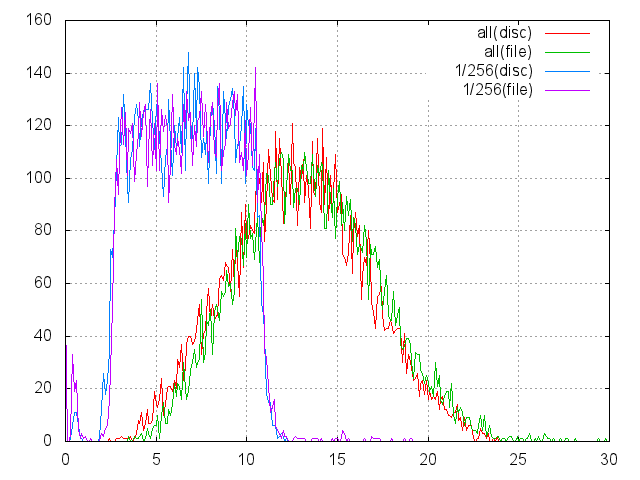
このグラフは、以前に提示されたヒストグラムに似ています。 そして、(ディスク)としてマークされたそれらのうちの2つは、前のチャートから取られています。 (file)とマークされたペアのヒストグラムは、ファイルの読み取り値の測定に基づいて取得されました。 注意できること:
- 時が近づいています。
- ファイルはファイルシステムの90%(9xE11バイト)ですが、フルサイズでの読み取りは平均でほぼ1ミリ秒遅くなります。
- ファイルのディスクキャッシュは、ディスクの場合よりも適切に機能します。
- 約6ミリ秒でテールがありましたが、完全な読み取りの最悪の時間は約24ミリ秒でしたが、現在はほぼ30ミリまで伸びています。同様に、1/256 どうやら、メタデータがキャッシュから外れたため、追加で読み取る必要があります。
- ただし、一般に、大きなファイルからの読み取りは、ベアディスクでの作業と非常によく似ており、場合によっては置換またはエミュレートできます。 これは、NTFSの名誉です。 たとえば、ext2 / ext3構造では、ファイルの4 KBデータブロックごとに4バイト以上が必要です。
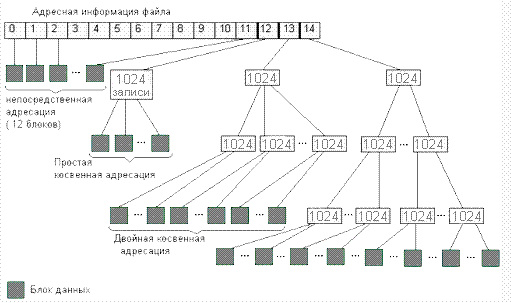
つまり、データのキロバイトごとに追加のバイトを費やす必要があり、テラバイトごとにギガバイトが出てきます。ギガバイトのキャッシングはそれほど単純ではありません。 ただし、ext4では、このような問題は明らかにないか、エクステントでマスクされています。
階層を持つNTFS
ファイルシステムを使用して、テストの問題を思い出し、正面から解決してみましょう。 すぐに判明しました:
- これにはかなりの時間がかかり、100万個のファイルから1つのブランチを作成するのに約30分かかります。最初のスケジュールに従ってディスクがいっぱいになると、徐々に遅くなる傾向があります。
- したがって、1億個のファイルをすべて作成するには、50時間以上かかります。
- そのため、700万ファイル(〜1/16)で測定を行い、タスク全体に拡大します。
- 戦闘に近い条件で測定を試みた結果、NTFSは映画「Death to her face」の主人公とほぼ同じ診断で約1200万のファイルでクラッシュしたという事実に至りました。頸椎は非常に、非常に悪い兆候です!」
最初に、ミリ秒単位のヒストグラムを検討します。
したがって、ここにランダムファイルの読み取り時間のヒストグラムがあります。
- 2つのシリーズ-タスクの1/16として700万、キャリブレーションのために100万。
- 一連の10000測定で、バスケット内で0.5ミリ秒。
- 1/16テストの合計時間は7'13 ''、つまり、予想は43ミリ秒です。
- 1/100テストの合計時間は5'20 ''、つまり、期待値は32ミリ秒です。
次に、条件付きシークの単位で同じことを見てみましょう。
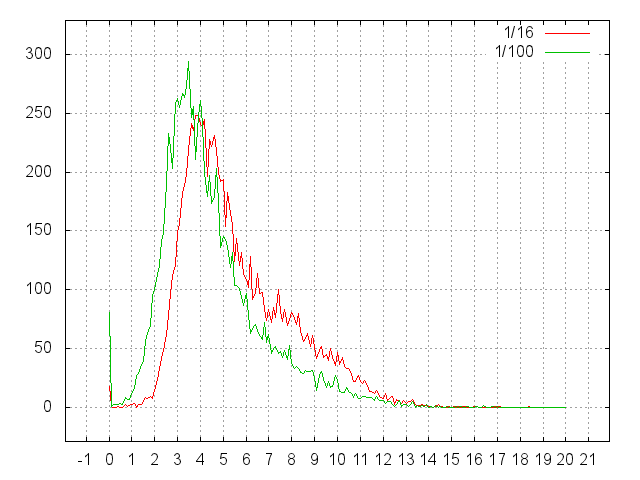
- その1/16、その1/100は大きすぎてキャッシュできない。 また、ファイルは断片化するには小さすぎます。
- したがって、1シーク、実際のデータの読み取りに料金を支払う必要があります。 それ以外はすべてファイルシステムの内部問題です。
- 最大値は、3.5(1/100の場合)および4(1/16の場合)シークで発生します。
- また、期待値は通常4〜5.です。
- つまり、ファイルの保存場所に関する情報を取得するには、ファイルシステム(NTFS)が3〜4回の読み取りを行う必要があります。 そして時々10以上。
- 完全なタスクの場合、おそらく状況は改善しません。
試作機
読み取り専用ファイルシステムのプロトタイプを作成しましょう。
- データとメタデータの2つのファイルで構成されます。
- データファイル-行に書き込まれたすべてのファイル。
- メタデータファイル-キーを持つツリー-ファイル識別子。 値は、データファイル内のアドレスとそのサイズです。
- ファイル識別子は、エンコードされたパスです。 データは3レベルのディレクトリシステムにあり、各レベルは0〜100の数字でエンコードされていることを思い出してください。ファイル自体は似ています。 この構造全体が整数にパックされます。
- ツリーは4Kページの形式で記述され、プリミティブ圧縮が適用されます。
- 断片化を回避するには、これらのファイルを異なるファイルシステムで作成する必要があります。
- ファイルの最後にデータを追加するだけでは効率的ではありません。 ファイルが大きいほど、ファイルシステム(NTFS、WinXP)の拡張子は高価になります。 この非線形性を回避するには、最初に目的のサイズ(900 GB)のファイルを作成する必要があります。
- この予備作成には2時間以上かかりますが、セキュリティ上の理由から、このファイルをすべてゼロで埋めるのに時間がかかります。
- このファイルにデータを入力するには、同じ時間がかかります。
- インデックスの作成には約2分かかります。
- 各サイズが約8Kの合計1億個のファイルを思い出してください。
- インデックスファイルは521 MBを占有します。 または、ファイルごとに約5バイト。 または、データのキロバイトあたり約5ビット。
- より複雑な圧縮(ハフマンコード)を使用したインデックスのバリアントもテストされました。 このインデックスは325 MBを占有します。 または、データのキロバイトあたり3ビット。
以下は、このデータで取得された時間のヒストグラムです。
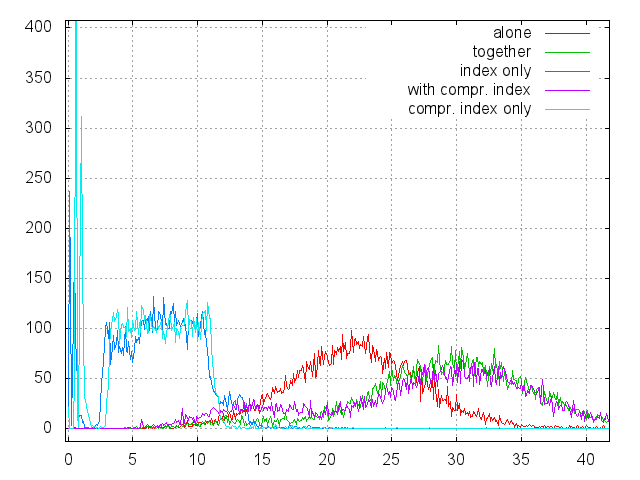
- 「単独」-このラベルの下には、別の物理ディスク上のインデックスファイルとは別に配置されたデータファイルがあります。
- 「一緒」-データファイルとインデックスの両方が同じ物理ディスク上の同じファイルシステム内にあります。
- 「インデックスのみ」-実際のデータを読み取らずに、インデックス内のファイルに関する情報のみを検索します。
- 「Compr。 インデックス「-一緒に」と「」、ただし圧縮インデックス付き。
- 「比較 インデックスのみ「-インデックスのみ」と同じですが、インデックスは圧縮されています。
- 合計10,000回の読み取り、0.1ミリ秒のヒストグラムステップ。
結論:
- インデックスの圧縮品質は、作業の速度にほとんど影響しません。 ページの圧縮にはCPU時間を要しますが、ページキャッシュの方が優れています。
- インデックスの読み取りは、適切なサイズのファイルからの読み取りのように見えます(最初のグラフを参照)。 512 MBはディスクの1/2000であるため、平均シーク時間は約6.5ミリ秒に加えて、ディスクから直接ではなくファイルから読み取るものにプレミアムを追加する必要があります。 どうやら、これで終わりです。 インデックスツリーは3レベルで、上位2レベルは非常に迅速にキャッシュされ、下位レベルのページをキャッシュしても意味がありません。 その結果、ツリー内の検索は、リーフページの単一の読み取りに縮退します。
- データファイルとインデックスファイルが同じ物理ディスクにある場合、合計検索時間は、全距離の2回のランダムシークに等しくなります。 1つはデータを読み取り、もう1つはディスクの最初または最後にあるインデックスファイルに移動します。
- ファイルが異なるデバイスに分散されている場合、データを読み取るための完全なシークと、インデックス内での検索のための短いシークがあります。 インデックスファイルが比較的小さいことを考えると、自然な解決策が示唆されます-数(10)テラバイトのストレージが必要な場合、インデックス(SSD)用の専用ドライブとデータ用の複数のドライブを準備する必要があります。 JBODとしてスタイル設定でき、通常のファイルシステムのように見えます。
- このスキームには重要な機能があります。応答時間の保証は、リアルタイムシステムでの使用など、従来のファイルシステムでは達成が困難です。
質問する時が来ました-まあ、まあ、私たちは定期的に配置されたファイルシステム(名前が固定された3つのレベル)の非常に特別なケースを作りました。 しかし、通常のデータ、通常のパスと名前はどうでしょうか?
答えは、根本的に何も変わらないということです。 メインインデックスはまだ1つあります。 しかし、それは少し異なって配置されます。
上記では、ファイル識別子(インデックスキー)がエンコードされたパスでした。 したがって、キーはファイルへの文字列フルパスです。 意味の他のすべて-サイズ、位置、所有者、グループ、権利...
おそらく多くの組み合わせ(所有者、グループ、権利)がなく、それらをグローバルな組み合わせテーブルを指すハフマンコードで保存することは有益です。 しかし、これらは詳細です。 基本的に、状況は既にテストした状況と変わりません。
ファイルを見つけるには、フルパスを指定する必要があります。 ディレクトリの内容を表示するには、ディレクトリパスを指定し、プレフィックスに一致するすべてを選択する必要があります。 階層を上に移動するには、パスの一部を噛み砕いて、プレフィックスで再度検索します。
しかし、ファイルパスは多くのスペースを占有しますか? はい。ただし、同じディレクトリ内のファイルには、1回しか保存できない共通のプレフィックスがあります。 共通の接尾辞も一般的です。 保存する必要があるデータの量を理解するために、ファイルシステムパスを使用して一連の実験を行い、bzip2(BWT +サフィックスソート+ハフマン)を使用して平均10倍で圧縮されることを示しました。 これにより、ファイルごとに5〜6バイトが残ります。
合計で、ファイルごとに10〜16バイト、またはデータのキロバイトごとに最大2バイトをカウントできます(平均ファイルが8Kの場合)。 1テラバイトのファイルには2ギガバイトのインデックスが必要です。通常の64ギガバイトのSSDドライブは32テラバイトのデータを提供できます。
アナログ
完全なアナログを提示することは困難です。
たとえば、圧縮なしのSquashFSは、同様の方法で使用できます。 ただし、このシステムは従来の構造を繰り返し、単純にファイル、iノード、ディレクトリを圧縮します。 したがって、私たちが熱心に避けようとしたのは、これらすべてのボトルネックに内在しています。
おおよその類似は、データストレージにDBMSを使用することです。 実際、ファイルのコンテンツをBLOBとして、メタデータをテーブル属性として保存します。 シンプルでエレガント。 DBMS自体が、使用可能なディスク領域にファイルをより効率的に配置する方法を処理します。 必要なすべてのインデックス自体を作成および維持します。 さらに素晴らしいボーナス-制限なしにデータを変更できます。
ただし:
- 最終的に、DBMSは直接またはファイルシステムを介してディスクにアクセスします。 そして、これは危険に満ちている、それは見落とす価値があります-バン! 動作時間が大幅に遅くなりました。 しかし、これが起こらない理想的なDBMSがあるとしましょう。
- DBMSは、読み取り専用モード向けに設計されていないため、プレフィックスを単純に効率的に圧縮することはできません。
- メタデータについても同じことが言えます。DBMSでより多くのスペースを占有します。
- より多くのスペース-より多くのディスク読み取り-より遅い作業。
- ファイルパスからハッシュコードを使用しても問題は解決しません。 パスとハッシュコードの一致は、ディレクトリの内容を表示する機能を提供するためだけにどこかに保存する必要があります。 すべての結果として、DBMSを使用してファイルシステムの構造を再現する必要があります。
- ページよりも大きいファイルは強制的にDBMSの部分に分割され、ファイルサイズの対数時間の間、それらへのランダムアクセスが最大限に実行されます。
- DBMSの場合、すべてのメタデータを専用のSSDに置くことができれば、はるかに困難になります。
- 保証された応答時間を忘れることができます。
トランザクション
明らかに、誰もワンタイムファイルシステムを必要としません。 ファイルシステムを数テラバイトのサイズで満たすには、数十時間かかる場合があります。 この間、新しい変更が蓄積される可能性があるため、完全な更新とは異なるデータを変更する方法が必要です。 作業を停止しないことをお勧めします。 さて、このトピックは別の話に値するものであり、時間をかけて私たちはそれについて話すつもりです。
合計
そこで、 プロトタイプの読み取り専用ファイルシステムを紹介します。これは、シンプルで柔軟性があり、テストの問題を解決すると同時に以下を実現します。
- 割り当てられたハードウェアで可能な最大パフォーマンスを示します。
- そのアーキテクチャは、データ量に客観的な制限を課しません。
- 特定のタスクのために作られた趣味ではなく、汎用ファイルシステムを取得するために何をすべきかを明確にします
- ファイルシステムを段階的に変更可能にするために、移動する価値がある方法を明確にします。