
ロックフリーデータ構造の構築は、アトミック操作とメモリへのアクセスを整理する方法という2つの柱に基づいています。 この記事では、原子性と原子プリミティブに焦点を当てます。
お知らせ 。 暖かい歓迎をありがとう! ロックフリーのテーマはhabrasocietyにとって興味深いものであり、私を幸せにします。 libcdsのコードでテキストを説明する方法に沿って、基本からアルゴリズムにスムーズに移行し、学術的にサイクルを構築することを計画しました。 しかし、一部の読者は、特にピクルスなしで、ライブラリの使用方法を示すために干渉することなく
それまでの間、私は必死に外部からの始まりを準備します- 基本の最初の部分です。 この記事の大部分は、C ++についてではなく(それについてでもあります)、ロックフリー(アトミックロックフリーがないとアルゴリズムは動作しませんが)についてでもなく、現代のプロセッサでのアトミックプリミティブの実装と、そのようなプリミティブを使用するときに生じる基本的な問題についてです。
原子性は、
アトミック操作は、単純な操作-読み取りと書き込み-およびアトミック変更操作(読み取り-変更-書き込み、RMW)に分かれています。 アトミック操作は、分割できない操作として定義できます。それは、すでに発生しているか、まだ発生していないかのいずれかです。 実装の中間段階は見られず、部分的な影響はありません。 この意味で、単純な読み取り/書き込み操作であっても、原則としてアトミックではない場合があります。 たとえば、アライメントされていないデータの読み取りは非アトミックです。x86アーキテクチャでは、このような読み取りにより内部例外が発生し、プロセッサが他のアーキテクチャ(Sparc、Intel Itanium)でデータを部分的に読み取るように強制されます-致命的なエラー(セグメンテーションフォールト)処理されますが、ここでは原子性についての話はできません。 最新のプロセッサは、整数型とポインタ型の整数型のみを読み書きする原子性を保証します。 最新のコンパイラは、基本型の変数の正しいアライメントを保証しますが、アライメントされていない呼び出しの例を全体に記述することは難しくありません。 構造(サイズ4〜8バイトに収まる)をアトミックに処理する場合は、コンパイラーディレクティブ(属性)を使用して適切なアライメントを自分で行う必要があります(各コンパイラーは、データ/型アライメントを指定する独自の独自の方法をサポートしています)。 ところで、 libcdsライブラリには、アライメントされたデータを宣言するときにコンパイラに依存する部分を隠す一連の補助型とマクロが含まれています。
比較と交換
読み取り/書き込みのみを使用するロックフリーコンテナーアルゴリズムを考え出すことは、可能な場合は非常に困難です(任意の数のスレッドに対するこのようなデータ構造はわかりません)。 そのため、プロセッサアーキテクチャの開発者は、アラインされたメモリセルをアトミックに読み書きできるRMW操作を実装しています:比較とスワップ(CAS)、フェッチと追加(FAA)、テストとセット(TAS)など。アカデミック環境では、比較とスワップ(CAS)操作は基本と見なされます。 彼女の擬似コードは簡単です:
bool CAS( int * pAddr, int nExpected, int nNew ) atomically { if ( *pAddr == nExpected ) { *pAddr = nNew ; return true ; } else return false ; }
つまり、
pAddr
の変数の現在の値が期待される
pAddr
と等しい場合、変数を
nNew
設定して
true
を返し、そうでない場合は
false
返し
false
。変数の値は変更されません。 これはすべてアトミックに実行されます。つまり、分割不可能で、目に見える部分的な効果はありません。 CASを使用すると、他のすべてのRMW操作を表現できます。たとえば、フェッチアンドアドは次のようになります。
int FAA( int * pAddr, int nIncr ) { int ncur ; do { ncur = *pAddr ; } while ( !CAS( pAddr, ncur, ncur + nIncr ) ; return ncur ; }
CASの「アカデミック」バージョンは、実際には常に便利であるとは限りません。CASに障害が発生した場合、セル内の現在の値に関心があることが多いためです。 したがって、このようなCASのバリアントは、多くの場合考慮されます(いわゆる値のCASもアトミックに実行されます)。
int CAS( int * pAddr, int nExpected, int nNew ) atomically { if ( *pAddr == nExpected ) { *pAddr = nNew ; return nExpected ; } else return *pAddr }
C ++ 11では、
compare_exchange
関数(厳密に言えば、C ++ 11にはそのような関数はありません。その種類は
compare_exchange_strong
と
compare_exchange_weak
ですが、後で説明します)は、これらのオプションの両方をカバーします。
bool compare_exchange( int volatile * pAddr, int& nExpected, int nNew );
nExpected
引数
nExpected
参照によって渡され、入力には
pAddr
の変数の期待値が含まれ、出力には変更前の値が含まれます。 関数は成功のサインを返します:アドレスに値
nExpected
が含まれている場合は
nExpected
(この場合は
nNew
に変更され
nNew
)、失敗した場合は
false
です(
nExpected
にはアドレス
pAddr
変数の現在の値が含まれます)。 CAS操作のこのような普遍的な構造は、CASの「アカデミック」定義の両方のバージョンをカバーしますが、実際には、
nExpected
引数
nExpected
参照によって渡され、変更できることを覚えておく必要があるため、
compare_exchange
エラー
compare_exchange
伴います。
compare_exchange
を
compare_exchange
フェッチアンドアドプリミティブは次のように記述できます。
int FAA( int * pAddr, int nIncr ) { int ncur = *pAddr; do {} while ( !compare_exchange( pAddr, ncur, ncur + nIncr ) ; return ncur ; }
ABAの問題
CASプリミティブはすべての人に適していますが、適用されると、 ABA問題と呼ばれる深刻な問題が発生する可能性があります。 それを説明するには、CAS操作を使用する典型的なパターンを考慮する必要があります。
int nCur = *pAddr ; while (true) { int nNew = if ( compare_exchange( pAddr, nCur, nNew )) break; }
実際、CASが機能するまでループで「バング」します。 ループが必要です。なぜなら、
pAddr
で変数の現在の値を読み取ってから新しい値
nNew
を計算する
nNew
変数は別のスレッドによって変更できるからです。
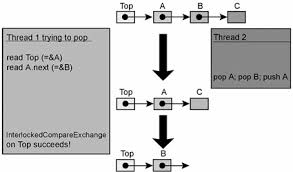
ABAの問題は次のように説明されます。スレッドXが、データへのポインターを含む共有セルからAの値を読み取るとします。 次に、別のスレッドYがこのセルの値をBに変更し、再びAに変更しますが、ポインターAは他のデータを指します。 スレッドXがCASプリミティブを使用してセル値を変更しようとすると、ポインターをAの以前の(読み取り)値と比較して成功し、CASの結果は成功しますが、Aは完全に異なるデータを指します! その結果、フローはオブジェクトの内部接続を混乱させる可能性があります(その結果、崩壊する可能性があります)。
ABAの問題が発生しやすいロックフリースタックの実装を次に示します[Mic04]:
// Shared variables static NodeType * Top = NULL; // Initially null Push(NodeType * node) { do { /*Push1*/ NodeType * t = Top; /*Push2*/ node->Next = t; /*Push3*/ } while ( !CAS(&Top,t,node) ); } NodeType * Pop() { Node * next ; do { /*Pop1*/ NodeType * t = Top; /*Pop2*/ if ( t == null ) /*Pop3*/ return null; /*Pop4*/ next = t->Next; /*Pop5*/ } while ( !CAS(&Top,t,next) ); /*Pop6*/ return t; }
次の一連のアクションは、スタック構造の違反につながります(ABAの問題を示すのはこのシーケンスだけではないことに注意してください)。
| スレッドx | スレッドy |
Pop()
呼び出します。 完了ライン Pop4
、 変数値: t == A
next == A->next
| |
NodeType * pTop = Pop()
pTop
==スタックの最上部、つまりA Pop()
Push( pTop )
スタックの一番上は再びAです A->next
が変更されていることに注意してください | |
ラインはPop5
。 CASは成功しましたが、 Top->next
フィールド 値を割り当てた スタック上に存在しない スレッドYがプッシュされたため スタックAおよび A->next
から そしてローカル変数 next
古い値を保存します A->next
|
ABAの問題は、CASプリミティブに基づくすべてのロックフリーコンテナーの惨事です。 これは、コンテナから要素Aを削除し、別の(B)に置き換え、その後再びA(したがって「 ABA問題」という名前)に置き換えるため、マルチスレッドコードでのみ発生しますが、別のスレッドは削除する要素へのポインタを保持します。 スレッドが物理的にAを削除し(
delete A
)、次に
new
を呼び出して新しい要素を作成した場合でも、アロケーターがアドレスAを返さないという保証はありません(適切なアロケーターはそれを行うだけです)。 多くの場合、上記よりも洗練された方法で現れ、2つではなく、より多くのフローに影響します(この意味で、十分な想像力がある限り、ABCBA問題、ABABA問題などについて話すことができます)、そしてその識別は常に重要なタスクです。 ABAの問題に対処する方法は、 遅延割り当て解除 、または削除された要素へのローカルまたはグローバル参照を誰も(競合するスレッドが)いないことを完全に保証した時点での要素の安全なメモリ再生です 。
したがって、ロックフリー構造から要素を削除することは2段階です。
- 最初のフェーズは、ロックフリーコンテナからの要素の除外です。
- 2番目のフェーズ(据え置き)は、要素への参照がない場合の要素の物理的な削除です。
次のいずれかの記事で、さまざまな遅延削除スキームについて説明します。
ロードリンク/ストア条件付き
おそらく、CASの使用時にABAの問題が存在するため、プロセッサ設計者はABAの問題の影響を受けない他のRMW操作を探すようになりました。 そして、そのような操作が見つかりました- ロードリンク/ストア条件付きのペア(LL / SC)。 これらの操作は非常に簡単です-擬似コードは次のとおりです。
word LL( word * pAddr ) { return *pAddr ; } bool SC( word * pAddr, word New ) { if ( pAddr LL) { *pAddr = New ; return true ; } else return false ; }
LL / SCペアは、演算子ブラケットとして機能します。 ロードリンク (LL)操作は、単に変数の現在値を
pAddr
ます。 ストア条件付き (SC)操作は、
pAddr
のデータが読み取られてから変更され
pAddr
いない場合にのみ、以前に読み取られたLL操作アドレス
pAddr
保存されます。 この場合、変更とは、
pAddr
アドレスが
pAddr
キャッシュラインの変更を指します。 LL / SCペアを実装するには、プロセッサ開発者はキャッシュ構造を変更する必要がありました。おおよそ、各キャッシュラインには追加のステータスビットが必要です。 LL操作によって読み取られると、このビットが設定(リンク)され、キャッシュラインへの書き込み(またはキャッシュからのプッシュ)によりビットがクリアされ、保存前のSC操作により、このビットがキャッシュラインに設定されているかどうかが確認されます:ビット= 1の場合、キャッシュラインを変更した人はいません
pAddr
の値は新しいものに変更され、SC操作は成功します。それ以外の場合、操作は失敗し、
pAddr
の値は変更されません。
CASプリミティブは、次のようにLL / SCペアを使用して実装できます。
bool CAS( word * pAddr, word nExpected, word nNew ) { if ( LL( pAddr ) == nExpected ) return SC( pAddr, nNew ) ; return false ; }
このコードのマルチステップの性質にもかかわらず、それはアトミックCASを実行することに注意してください。ターゲットメモリセルの内容は変化しないか、 アトミックに変化します。 CASプリミティブのみをサポートするアーキテクチャでLL / SCペアを実装することは可能ですが、それほどプリミティブではありません。 ここでは検討しません;興味のある方は記事[Mic04]を参照してください。
最新のプロセッサアーキテクチャは、2つの大きなキャンプに分かれています-コマンドシステムでCASプリミティブをサポートするものと、LL / SCのペアをサポートするものがあります。 CASは、x86、Intel Itanium、Sparcアーキテクチャに実装されています。 プリミティブはIBM System 370アーキテクチャーで初めて登場し、LL / SCペアはPowerPC、MIPS、Alpha、ARMアーキテクチャーです。 DECによって最初に提案されました。 LL / SCプリミティブが最も理想的な方法で最新のアーキテクチャに実装されていないことに注意する価値があります:たとえば、異なるアドレスでネストされたLL / SC呼び出しを行うことはできません、リンクフラグの誤ったリセットが可能です(いわゆる偽共有、以下を参照)、フラグ検証プリミティブはありませんLL / SCペア内でリンクされています。
C ++の観点から、C ++ 11標準はLL / SCペアを考慮せず、アトミックプリミティブ
compare_exchange
(CAS)とそれから派生したアトミックプリミティブ
fetch_add
、
fetch_sub
、
exchange
などのみを記述します。標準はLLを使用してCASを実装することを意味します/ SCは非常に単純ですが、逆の実装(CASを介したLL / SC)は非常に重要です。 したがって、標準C ++ライブラリの開発者の生活を複雑にしないために、C ++で導入された標準化委員会は、原則としてロックフリーアルゴリズムを実装するのに十分な
compare_exchange
のみを導入しました。
偽りの共有
最新のプロセッサでは、Lキャッシュ(キャッシュライン)のライン長は64〜128バイトであり、新しいモデルでは増加する傾向があります。 メインメモリとキャッシュ間のデータ交換は、Lバイトのブロックで実行されます(通常、Lは2のべき乗です)。 キャッシュラインの少なくとも1バイトが変更されると、ライン全体が無効と見なされ、メインメモリとの同期が必要になります。 これは、マルチプロセッサ/マルチコアアーキテクチャのキャッシュコヒーレンシサポートプロトコルによって制御されます。
MESIキャッシュコヒーレンスサポートプロトコル
たとえば([Cha05])、IntelプロセッサのプロセッサコヒーレンスをサポートするMESIプロトコル(変更-排他-共有-無効)は、共有ラインへの書き込みごとにキャッシュラインを無効としてマークし、集中的なメモリ交換につながります。 キャッシュラインに最初にデータがロードされると、MESIはこのラインをE(排他的)としてマークします。これにより、プロセッサーはキャッシュラインへのデータの読み取り/書き込みを無制限に行うことができます。 別のプロセッサがこの他のプロセッサのキャッシュにある同じデータにアクセスする必要がある場合、MESIはキャッシュラインをS(共有)としてマークします。 現在、任意のキャッシュ内のそのようなラインに書き込む命令は、ラインをM(変更済み)としてマークし、その結果、他のプロセッサーのキャッシュ内でこのラインをI(無効化)としてマークし、その結果、メインメモリからデータをロードします。 次のメモの1つで、最新のプロセッサの内部組織に関するすばらしい記事の翻訳を提供する予定なので、MESIプロトコルについて詳しくは説明しません。

異なる共有データが1つのキャッシュラインに分類された場合(つまり、隣接するアドレスにある場合)、データの1つを、プロセッサの観点から、同じキャッシュラインにある他の無効化に変更します。 この状況は、 偽共有と呼ばれます 。 LL / SCプリミティブの場合、これらのプリミティブの実装はキャッシュラインの観点から行われるため、偽共有は悲惨です。ロードリンク操作はキャッシュライン(リンク)をマークし、書き込み前のストア条件操作はこのラインのリンクフラグがクリアされているかどうかをチェックします; フラグがクリアされている場合、エントリは作成されず、SCはfalseを返します。 Lラインの長さが非常に長いため 、SCプリミティブの誤った障害 (リンクフラグのリセット)は、ターゲットデータに関連しないキャッシュラインの変更で発生します。 その結果、 livelockを取得できます。 これは、プロセッサ/コアが100%ビジーですが、進捗がない状況です。
偽共有との戦いは非常に単純ですが(無駄です)、各共有変数はキャッシュライン全体を占有する必要があります。 これには、通常、パディングが使用されます。
struct Foo { int volatile nShared1; char _padding1[64]; // padding for cache line=64 byte int volatile nShared2; char _padding2[64]; // padding for cache line=64 byte };
キャッシュの物理構造は、LL / SCプリミティブだけでなく、すべての操作(CASを含む)に影響することに注意してください。 一部の研究では、キャッシュ構造を考慮して(主にキャッシュラインの長さを考慮して)特別に構築されたデータ構造を調査しています。 データ構造を適切に(「キャッシュの下に」)構築すると、生産性が大幅に向上します。
CASの種類
CASダブル幅 (ダブルワードCAS、dwCAS)とダブルCAS (DCAS)という2つの有用なアトミックプリミティブについて簡単に説明します。
ダブル幅CASは通常のCASに似ていますが、32ビットアーキテクチャの場合は64ビット、64ビットの場合は128ビット(正確には少なくとも96ビット)の2倍のサイズのメモリセルで動作します。 CASの代わりにLL / SCペアを提供するアーキテクチャの場合、LL / SCは倍長ワードでも動作する必要があります。 私が知っているアーキテクチャのうち、x86のみがdwCASをサポートしています。 なぜこのプリミティブはとても便利なのですか? ABA問題タグ付きポインターを解決するための最初のスキームの1つを整理できます。 このスキームは、ABAの問題を解決するためだけにIBMによって提案されたもので、各タグポインターを整数と一致させることにあります。 タグ付きポインターは、次の構造で記述できます。
template <typename T> struct tagged_pointer { T * ptr ; uintptr_t tag ; tagged_pointer() : ptr( new T ) , tag( 1 ) {} };
アトミック性を確保するには、このタイプの変数を二重に整列させる必要があります。32ビットアーキテクチャでは8バイト、64ビットでは16バイトです。 タグには、
ptr
指すデータの「バージョン番号」が含まれます。 タグ付きポインターについては、安全なメモリ再生(SMR)に関する次のいずれかの記事で詳しく説明しますが、ここでは、タグ付きポインターがT型のデータ(および対応する
tagged_pointer
)に割り当てられたメモリを意味するという事実にのみ注意します物理的に削除(
delete
)するのではなく、フリーリスト(各タイプTに個別)に配置する必要があります。これから、将来、タグをインクリメントしてデータが再配布されます。 これがABA問題の解決策を提供するものです。実際、ポインターは複合であり、タグにバージョン番号(ディストリビューションのシリアル番号)が含まれています。 この場合、tagged_pointer型の引数に等しいポインターがあり、タグ値が異なる場合、dwCASは成功しません。
2番目のアトミックプリミティブであるダブルCAS (DCAS)は、現在は純粋に仮想的なものであり、最新のプロセッサアーキテクチャには実装されていません。 DCAS擬似コードは次のとおりです。
bool DCAS( int * pAddr1, int nExpected1, int nNew1, int * pAddr2, int nExpected2, int nNew2 ) atomically { if ( *pAddr1 == nExpected1 && *pAddr2 == nExpected2 ) { *pAddr1 = nNew1 ; *pAddr2 = nNew2 ; return true ; } else return false }
DCASは、2つの任意に整列されたメモリセルで動作し、現在の値が期待値と一致する場合、両方の値を変更します。
なぜこのプリミティブはとても興味深いのですか? 事実、その助けを借りれば、ロックフリーの二重リンクリスト(deque、double-linkedリスト)を簡単に作成でき、そのようなデータ構造は多くの興味深いアルゴリズムの基礎になっています。 DCASベースのデータ構造に関する多数の学術論文があります。 このプリミティブは「ハードウェアで」実装されていませんが、通常のCASに基づいてDCAS(および一般に複数の
pAddr1
...
pAddrN
アドレス
pAddr1
pAddrN
マルチCAS)を構築するためのアルゴリズムを説明する作品(たとえば[Fra03]-それらの中で最も有名)
性能

アトミックプリミティブのパフォーマンスはどうですか?
現代のプロセッサは非常に複雑で予測不可能であるため、製造元は、内部同期、プロセッサバス上の信号などが関与する特定の命令、特にアトミック命令の持続時間について明確な保証を与えていません。プロセッサ命令の期間を測定します。 [McKen05]から測定を行います。 この作業では、著者は、とりわけ、アトミックインクリメントおよびCASプリミティブの期間を
nop
(no-operation)操作の期間と比較します。 したがって、Intel Xeon 3.06 GHz(2005サンプル)の場合、アトミックインクリメントの期間は400 nop、CAS-850-1000 nopです。 IBM Power4プロセッサー1.45 GHz:アトミックインクリメントの場合は180 nop、CASの場合は250 nop。 測定値はかなり古い(2005年)で、過去数年間、プロセッサアーキテクチャはさらにいくつかのステップを踏みましたが、数字の順序は同じままであると思います。
ご覧のとおり、アトミックプリミティブはかなり重いです。 したがって、それらをどこにでも適用するのはかなり費用がかかります。たとえば、バイナリツリー検索アルゴリズムがCASを使用して現在のツリーノードを読み取る場合、そのようなアルゴリズムに良いものは期待できません(そのようなアルゴリズムを見てきました)。 公平に言えば、Intel Coreアーキテクチャの新世代ごとに、CASプリミティブが高速化しているように感じますが、Intelのエンジニアはマイクロアーキテクチャの改善に多大な努力を注いでいるようです。
揮発性と原子性
C ++には、不可解な
volatile
キーワードがあります。 時々、
volatile
原子性と順序付けに関連付けられます-これは間違っていますが、いくつかの歴史的な理由があります。
実際、
volatile
は、コンパイラーがレジスターに値をキャッシュしないことを保証するだけです(最適化コンパイラーはこれを行うのが大好きです。レジスターが多いほど、キャッシュが増えます)。 つまり、揮発性変数の読み取りは常にメモリからの読み取りを意味し、揮発性変数の書き込みは常にメモリへの書き込みを意味します。 したがって、誰かが揮発性データを並行して変更した場合、すぐにそれがわかります。
実際、表示されません。 メモリバリアが不足しているため。 一部の言語(Java、C#)では、
volatile
魔法のステータス
volatile
割り当てられていますが、C ++ 11ではそうではありません。 また、
volatile
は特別なアライメントを保証するものではなく、データアライメントの正しい条件が原子性に必要な条件であることがわかりました。
したがって、C ++ 11互換コンパイラの場合、アトミック変数に
volatile
を指定する必要はありません。 しかし、古いコンパイラでは、自分で
atomic
実装する場合に必要になることがあります。 そのような広告では:
class atomic_int { int m_nAtomic; //…. };
コンパイラには、
m_nAtomic
呼び出しを「最適化」するすべての権利があります(呼び出しは間接的に
this
を通じて行われ
this
)。 したがって、
int volatile m_nAtomic
を示すと
int volatile m_nAtomic
。
C ++のvolatileメソッド
インターフェイスを調べると、おそらくメソッドの多くに
指定子があることに気付くでしょう。
これは何ですか
ポインターは
ですか(つまり、タイプ
ですか)? 一般に、これは不可能です-
しばしばレジスタで渡され、これはいくつかのABIで指定されます。 実際には、タイプ
です。
メソッドとの類推により、この指定子は、
が揮発性データを指している、つまり、オブジェクトのすべてのメンバーデータがそのようなメソッドで
であると言います。 これにより、コンパイラがメンバーデータへのアクセスを最適化できなくなります。 基本的に、このデータを
として宣言した場合と同じです。
さて、
と
指定子は反対ではなく、一緒に存在できることを思い出させてください。
readメソッドの宣言は次のとおりです。
:
atomic
インターフェイスを調べると、おそらくメソッドの多くに
volatile
指定子があることに気付くでしょう。
void store( T val ) volatile ;
これは何ですか
this
ポインターは
volatile
ですか(つまり、タイプ
T * volatile
ですか)? 一般に、これは不可能です-
this
しばしばレジスタで渡され、これはいくつかのABIで指定されます。 実際には、タイプ
T volatile *
です。
const
メソッドとの類推により、この指定子は、
this
が揮発性データを指している、つまり、オブジェクトのすべてのメンバーデータがそのようなメソッドで
volatile
であると言います。 これにより、コンパイラがメンバーデータへのアクセスを最適化できなくなります。 基本的に、このデータを
volatile
として宣言した場合と同じです。
さて、
const
と
volatile
指定子は反対ではなく、一緒に存在できることを思い出させてください。
atomic<T>
readメソッドの宣言は次のとおりです。
T load() const volatile ;
:
-
const
— - -
volatile
— - - ,
libcds
結論として、libcdsライブラリには何がありますか?また、x86 / amd64、Intel Itanium、およびSparcアーキテクチャ向けのC ++ 11の精神に基づいたアトミックプリミティブの
libcds
独自のアトミックプリミティブの実装を使用します。同時に、通常のアトミック読み取り/書き込みに加えて、ロックフリーデータ構造を構築する際の主要なアトミックプリミティブはCASであり、CASはダブルワード(dwCAS)で使用されることはほとんどありません。DCAS実装(および一般にマルチCAS)
libcds
[今のところ]いいえ、しかし、将来登場する可能性は十分にあります。非常に興味深いデータ構造を構築できます。多くの研究によると、[Fra03]アルゴリズムによるDCASの実装はかなり非効率的であるということを止めるだけです。しかし、ロックのない世界では、有効性の基準は純粋に個々のものであることにすでに注意しました。このハードウェア上で、このタスクで現在無効なものは、別のハードウェア上で、または別のタスクで非常に効果的であることが判明する可能性があります!基礎の
次の記事では、メモリアクセスの順序(メモリの順序)-メモリバリア(メモリフェンス、メモリバリア)について説明します。参照:[Cha05] Dean Chandler は.NETでの偽共有を削減、2005年、Intel Corporation [Fra03] Keir Fraser
Practical Lock Freedom、2004; 技術報告書は提出論文に基づいています 9月、その後ケンブリッジ大学、キングスカレッジに哲学博士の学位によってK.Fraser 2003
[McKen05]トーマス・ハートによるポールMcKenney、ジョナサン・ウォルポールのスケーラブルな同期のための実用的な懸念
マイケルによって[Mic04] Maged 単一単語命令を使用したABA防止、IBM Research Report、2004
ロックフリーのデータ構造