私たちのデータの主なソースは、ロシア語コンテンツを含む国際的な知識ベースです: DBpedia 、 FreebaseおよびWikidata 。 まず第一に、これらは参照データ、言語データ、百科事典データです。 ウィキペディアまたはウィクショナリーの一部を解析するたびに、自分自身を適切につまんで、カテゴリ、情報ボックス、またはテーブルに保存されているすべてのものがすでに解析されており、SPARQLまたはMQLインターフェイスを使用してAPI経由でアクセスできることを覚えておいてください。
Linked Data以外には見られない有用な百科事典データの例をいくつか紹介します。
この記事は、ナレッジベースシリーズの最初の記事です。 お楽しみに。
- パート1-はじめに
- パート2-Freebase:Googleナレッジグラフでクエリを作成する
- パート3-Dbpedia-リンクデータワールドのコア
- パート4-ウィキデータ-セマンティックウィキペディア
都市、国、履歴データ
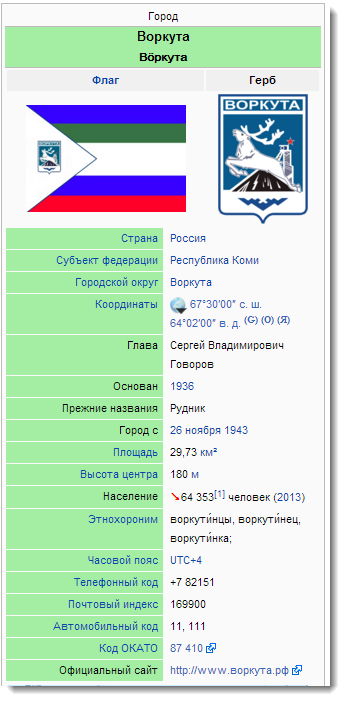 都市や国に興味がある場合、リンクされたデータには、それらの場所に関する情報(正直なところ、他のソースからドラッグする方が良い)だけでなく、
都市や国に興味がある場合、リンクされたデータには、それらの場所に関する情報(正直なところ、他のソースからドラッグする方が良い)だけでなく、
- 宮殿や記念碑などのアトラクション
- 生まれて死んだ有名人
- 毎月の降雨量や日の出時間などの気象統計
- 紋章、旗
- 人口統計
- 関連する歴史的出来事
ここで、たとえば観光地について話すとき、アルファベット順の悲惨な名前のリストを意味するものではないことに注意してください。 すべてのデータはカテゴリに分けられ、時間と場所、建築家の名前、時代、芸術的な方向に結び付けられています。 美術館に出会ったら、その中に展示されている最も重要な展示を引き出すことができます。 もちろん、これらの展示を作成した人に関する情報も利用できます。
セマンティックWebの他の場所と同様に、他のオブジェクトに関連付けられ、時には他のデータベースの代替説明を指すオブジェクトのリストを受け取ります。 ツーリストアプリケーションがすぐに思い浮かびます。ユーザーは「モスクワアベニューの名所を見る」機会を与えられるだけでなく、20世紀の第1四半期の新古典主義に関連するオブジェクトのみを除外することができます。 また、DBPediaのカテゴリツリーを使用している場合でも、ユーザーに関連スタイル(たとえば、近世)を提供できます。
いくつかの地理的ポイントはイベントに関連付けられています-また、それらについて多くを学ぶことができます。 たとえば、 KulikovskayaまたはBorodinoの戦闘でパワーと殺された人数のバランスをとることは非常に簡単です。 もちろん、イベントが関連付けられている人格は忘れられていません。
SELECT DISTINCT?強さ?結果?Longitute?Latitude、Commander WHERE {
dbpedia:Battle_of_Kulikovo dbpprop:強さ?強さ;
dbpprop:result?result;
geo:long?longitute;
geo:緯度?
dbpedia-owl:司令官?司令官
}
制限1000
機関、組織、州の構造に関するデータ
多くの場合、これらのタイプの日付は分析に必要です。 たとえば、ウィキペディアで言及するに値する最もオリガルヒ/科学者/作家を生産している大学を計算するために。
- スタッフ/学生/教授の数、学生用-戦車、マスター、留学生の数
- 年間収入
- 評価に入れる
- 設立日
- 子会社および親会社
- マネージャーに関する情報
作曲家、ミュージシャン、映画
映画に関しては、すべてが強さ以上のものに見えます。Freebase、Dbpedia、およびLinkedmdbには、映画撮影に関する非常に優れたデータセットがあります。
ileriseviye.wordpress.com/2012/07/11/is-semantic-web-and-linked-data-good-enough-sparql-dbpedia-vs-python-imdbpy
どの俳優がどこで、どこで、どの年に映画が公開され、誰が公開されたかを簡単に見ることができるだけでなく、俳優が生まれたときに影響を与えた人物、婚status状況や彼が何かに従事しているかどうかもわかります撮影を除く。
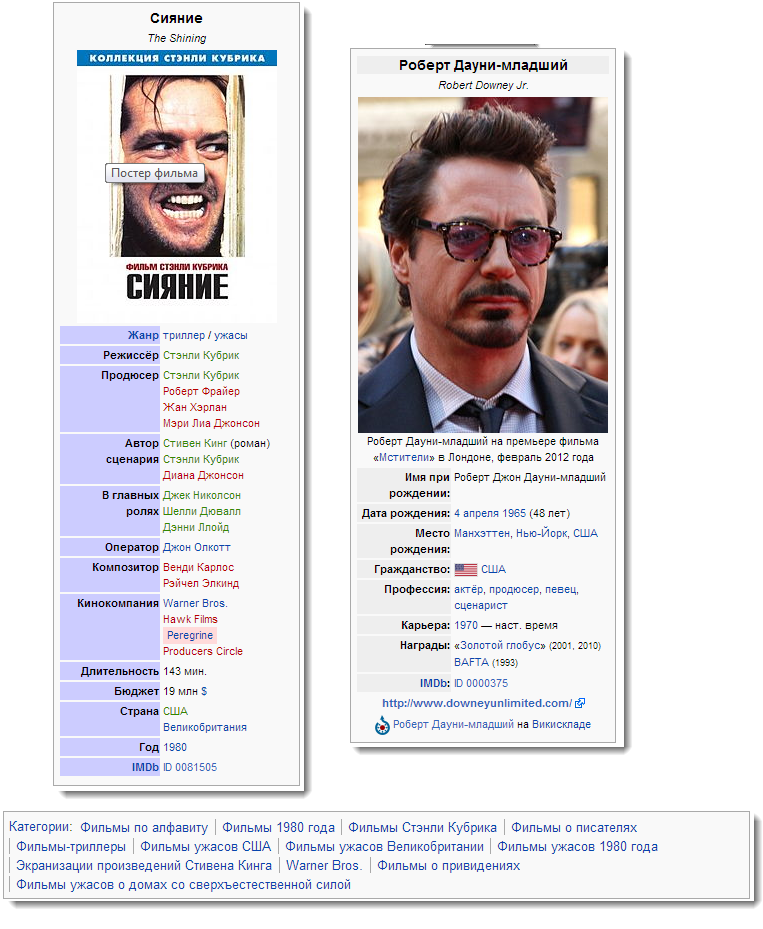
たとえば、Dbpediaへのこのリクエストには、 The ShiningとHoffaの両方で主演したすべての俳優が表示されます。

おそらく音楽の分野で最も注目すべきデータソースはMusicBrainzです。 もちろん、RDFにもあります。もちろん、従来のAPIを使用してそれらにアクセスします。 ただし、ここでもFreebaseとDbpediaが役立ちます。後者には、たとえば、音楽グループのツアーに関する情報が含まれています。 さて、生年月日、影響、スタイル、ジャンル-音楽の百科事典データも存在します。 実際、トレーニング資料では、Freebaseは音楽的な例を使用しています。グループThe Policeに関するデータを取得します。
{
「タイプ」:「/音楽/アルバム」、
「名前」:「同期性」、
「アーティスト」:「警察」、
「トラック」:[{
「名前」:null、
「長さ」:null
}]
}
これをLast.fm APIと組み合わせて使用することはおそらく興味深いでしょう。
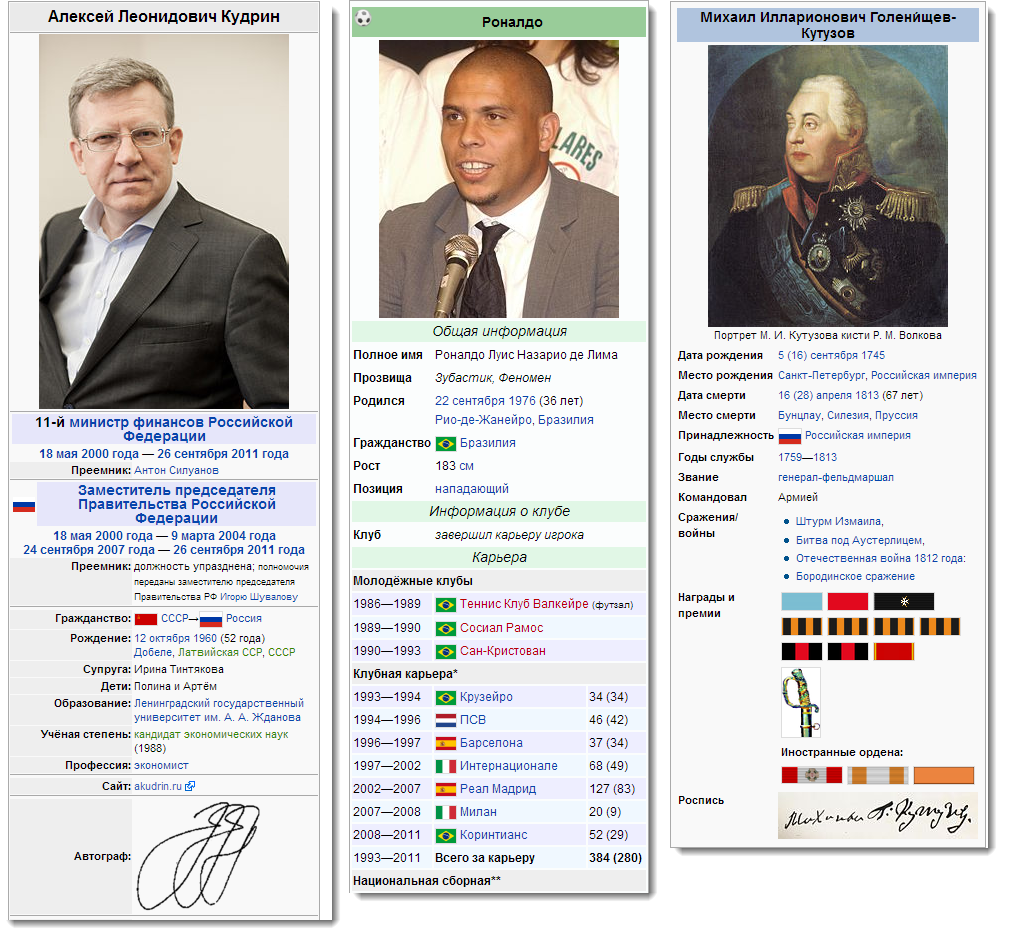
人:政治家、運動選手、歴史上の人物
ウィキペディアでパーソナリティを説明するとき、情報ボックスは非常に集中的に使用されます。これにより、記事の外観が厳密になります。 したがって、あなたが社会活動家であり、政治家に関する情報を含むサイトを書くと、彼がどこで、どんな賞を、どのような役職に就いているかを研究したDbpediaで見つけることができます。 スポーツ関連のアプリケーションでは、アスリートのキャリアデータ、身長、体重、重要な伝記の事実を使用できます。
言語アプリケーション。 カテゴリー階層
分類とクラスタリングのニーズ、および数学言語学のタスクについては、概念の階層が必要になることがよくあります。 たとえば、その指は身体の一部です。 セマンティックWebは支援を急いでおり、ウィキペディアのカテゴリを解析するのではなく、Dbpediaまたはwww.mpi-inf.mpg.de/yago-naga YAGOからそれらを準備することができます。 階層のサイズがその品質よりも重要でない場合は、手動で作成されたオントロジーDbpedia、Cyc、Umbelを見ることができます。
言語アプリケーション。 ウィクショナリーと翻訳
2012年の終わりに、Dbpediaチームはウィクショナリープロジェクトを立ち上げました-データベースとしてのウィクショナリーへのアクセス。 これで、英語、ドイツ語、フランス語、ロシア語、ギリシャ語、ベトナム語の言語をリクエストできます。 ウィクショナリーのSPARQLポイントを介して、いくつかの良いロシア語の翻訳を引き出してみましょう。

セマンティックWebには多くの言語学者がいるため、言語の世界には相互接続されたデータの独自のクラウドがあります。
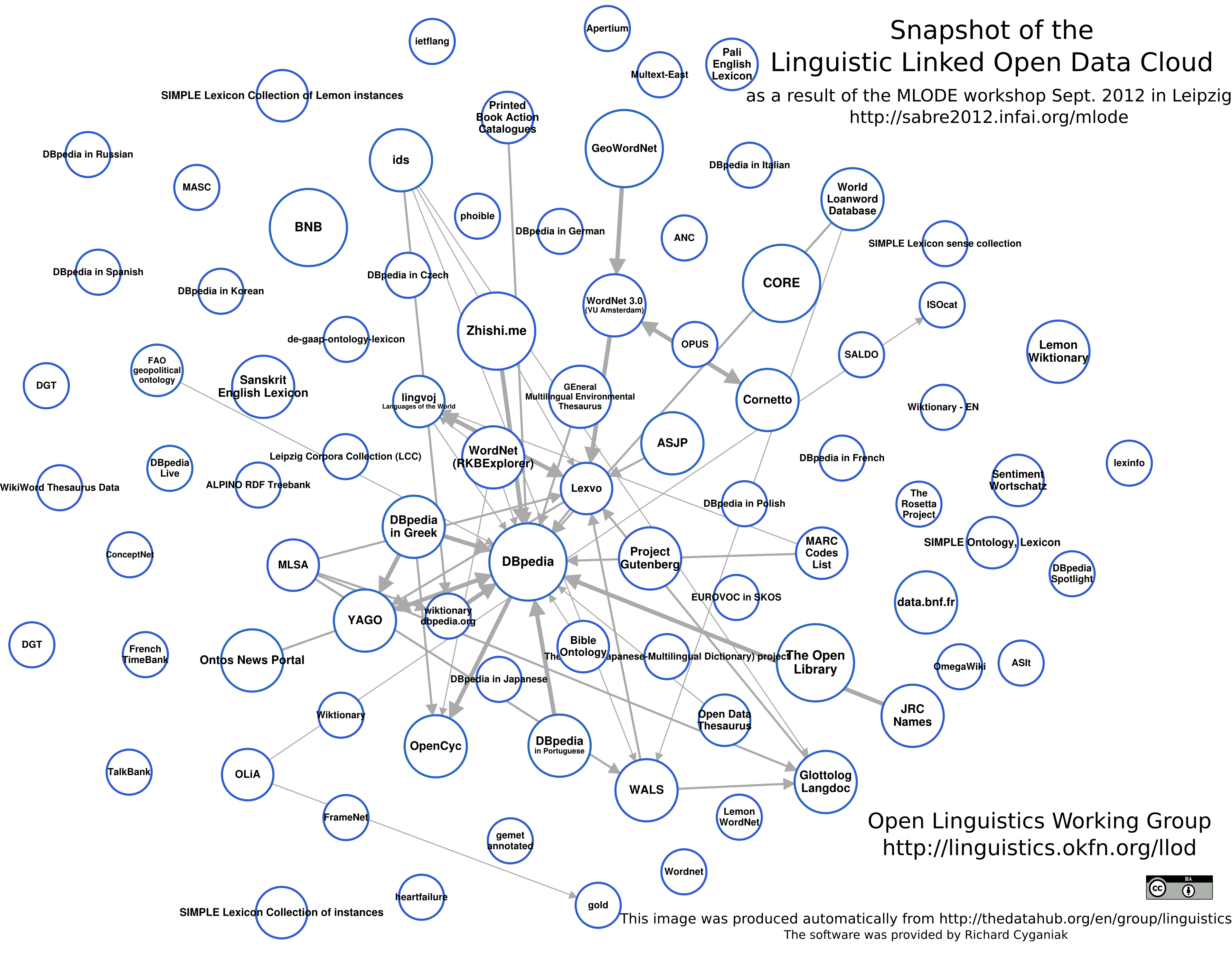
リンクされたデータおよびリンクされていないデータに関する多くの有用な情報は、 Open Knowledge FoundationおよびロシアのNLPubポータルから取得できます 。
良いデータを見つける方法
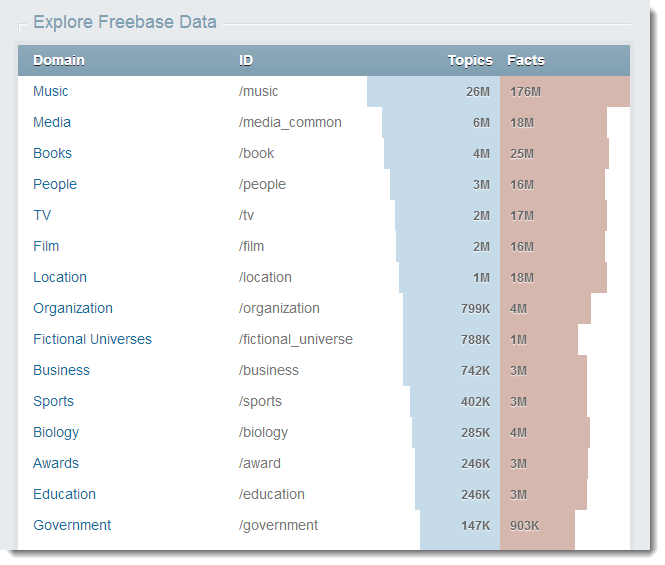
Freebaseの場合、メインページには、どのカテゴリに最も多くのオブジェクトが含まれているかが視覚化されます。
DBPediaには、質の高いデータがどこに隠れているかを理解する簡単な方法があります。 Mappings.DBpediaアプリケーションとその統計概要を参照する必要があります。
マッピングは、DBpediaユーザーがパーサーの動作に影響を与えることができる優れたツールです。 以降の記事でそれらについて詳しく説明しますが、今のところはこのページに限定します。
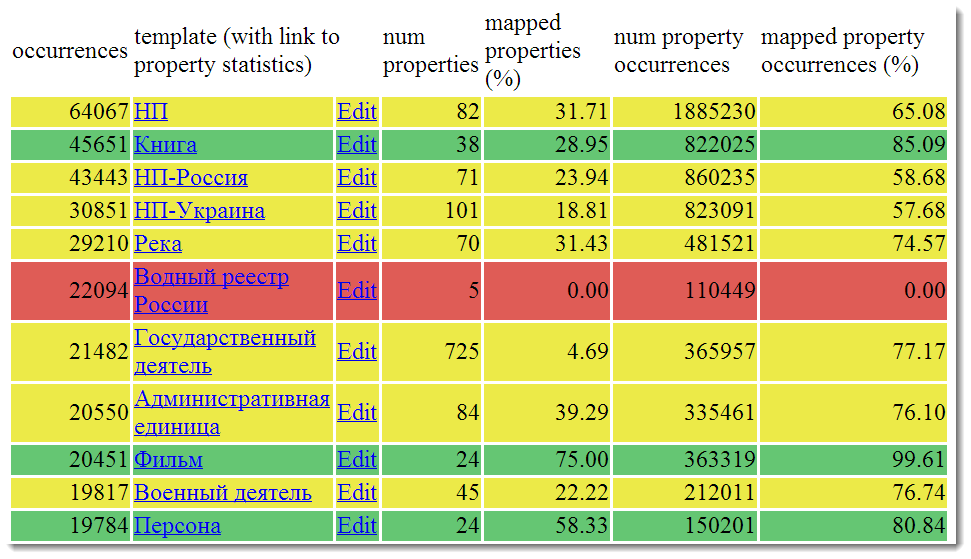
セルには、Wikipediaテンプレートの名前が含まれています。 赤色のセルには完全に自動的に解析されたデータが含まれ、緑色のセルには解析が人の参加で実行されたため、データの品質が高くなるはずです。
検索する
まあ、私が言うことができる、検索は検索です。 エンジンSig.ma 、 Sindice 、 Swoogleを使用します。 これらはすべて、同じデータセット内またはLInkedデータのセット全体を検索できます。
次回は、DbpediaナレッジベースへのSPARQLクエリの作成方法を学習する方法を説明します。