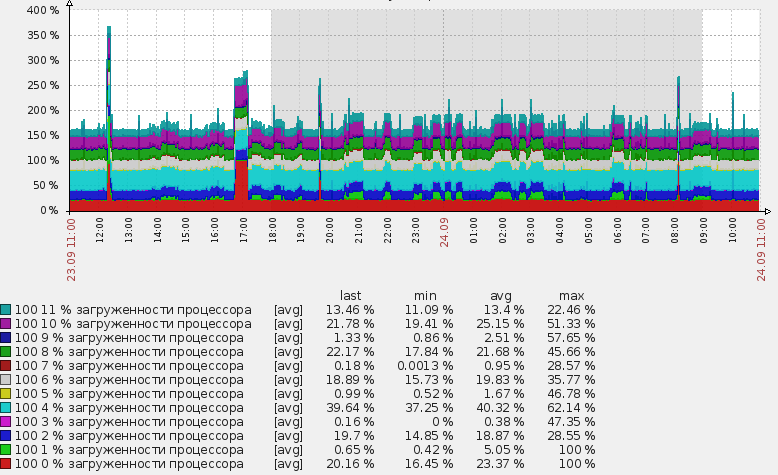
最初は、CPUコアと物理ディスクの負荷に加えて、高度なマウントに興味がありました。 発見が導入される前は、これらのタスクは手動で追加することで部分的に解決されていました。 条件付きディスクをzabbix_agent構成ファイルに追加しましたが、一般にそれを異なった形に変形しました。 その結果、それは非常に不便であり、多くの不快な手作りの作業が追加され、一般的にそれは何らかの形で間違っていました:)
その結果、システム内のカーネルとシステムにインストールされている物理ディスクを自動的に検出し、必要なデータ収集要素を追加する回路ができます。 自宅でこれを実装する方法を学ぶために、猫にようこそ。 CPUの例と、同じことを物理ディスクで行う方法について、多少詳細に説明します。
送信されたデータのタイプ
そもそも、ドキュメントを参照する価値があります。これは 、 LLDが何であり、何が食べられるかを示しています。 標準テンプレートに加えて、JSON検出形式の説明を含む4番目のセクションに興味があります。 つまり、独自の検出方法を作成します。 実際、正しい形式で必要なデータを生成するスクリプトを呼び出すことになります。
スクリプトを作成します。
スクリプトには、powershellを選択しました。 私は彼を他のスクリプト言語よりも少しよく知っています。すべてがWMIサークルで展開されることを考えると、それはVBSで実行できます。
だから、スクリプト。
スクリプトのタスクは、WMIを使用して論理プロセッサの数を決定し、このデータをJSON形式でコンソールに出力することです 。 {#PROCNUM}という名前の変数とその値を渡します。 論理プロセッサの数に応じて、出力形式は次のようになります。
{ "data":[ { "{#PROCNUM}":"0"}, { "{#PROCNUM}":"1"}, { "{#PROCNUM}":"2"}, { "{#PROCNUM}":"3"}, { "{#PROCNUM}":"4"}, { "{#PROCNUM}":"5"}, { "{#PROCNUM}":"6"}, { "{#PROCNUM}":"7"}, { "{#PROCNUM}":"8"}, { "{#PROCNUM}":"9"}, { "{#PROCNUM}":"10"}, { "{#PROCNUM}":"11"} ] }
データ生成スクリプト
スクリプト自体は次のようになります。
$items = Get-WmiObject Win32_PerfFormattedData_PerfOS_Processor | select name |where-object {$_.name -ne '_Total'} write-host "{" write-host " `"data`":[" write-host foreach ($objItem in $Items) { $line = " { `"{#PROCNUM}`":`"" + $objItem.Name + "`"}," write-host $line } write-host write-host " ]" write-host "}" write-host
これで、スクリプトの開始時に、コアの数がわかり、送信用のパッケージが形成されます。
次に何をしますか? 検出ルールを作成する必要があります。
zabbixサーバー設定に低レベル検出を追加
これを行うには、対象のホストに追加されている目的のテンプレートの[ 検出 ]セクションに移動し、[ 検出ルールの作成 ]ボタンをクリックします。

ここで、キーの理解できない値、 PSScript [proc.ps1] fieldを確認します 。 これはUserParameterです。 このアイテムは便宜上作成されたもので、新しいオブジェクトごとに、PSスクリプトの名前の形式でパラメーターを入力するだけで、事前に決められた場所で検索されます。 パラメーター自体はクライアント構成ファイル(通常zabbix_agentd.confと呼ばれます)に書き込まれ、次のようになります。
UserParameter=PSScript[*],powershell -File "C:\Program Files\zabbix agent\script\$1"
カスタムデータコレクションを使用して新しい検出ルールを作成しました。 情報を変更する要求は1時間に設定されます。 おそらく、プロセッサの数などの静的データの場合、これはあまりにも頻繁に:)ですが、誰もが自分の価値を自由に置くことができます。 初期データの収集とデバッグでは、この値を非常に小さな値に減らして、スクリプトの実行に何時間も待たないようにすることをお勧めします。
データプロトタイプのセットアップ
いいね プロセッサの数に関するデータの収集を開始しました。 しかし、結果として、このデータではなく、監視の新しい項目が必要です。 スクリプトではなく、データを収集できるアイテムです。スクリプトは、要素自体を検出してデータを収集するだけです。
そして、LLDに基づいて取得した新しいデータコレクション要素を作成するために、同じDiscoveryセクションで新しいプロトタイプを作成します。 これを行うには、 アイテムプロトタイプに移動し、 アイテムプロトタイプの 作成をクリックします 。 このコレクション要素を作成しました:

データを収集するには、標準のパフォーマンスカウンターを使用します。 Zabbixには、このデータを収集するperf_counterキーがあります。 論理コア番号の代わりに、結果の値をDiscoveryセクションからの変数の形式で挿入します。
これですべて準備完了です。 またはほとんどすべて...
この時点から、 検出スクリプトが論理プロセッサを検出すると、このホスト数に対してこの数のプロセッサ用に作成されたデータ収集要素が作成されます。
そして、低レベルのディスカバリーがすでに機能しているホストのアイテムに進むと、新しい要素が表示されていることがわかります。
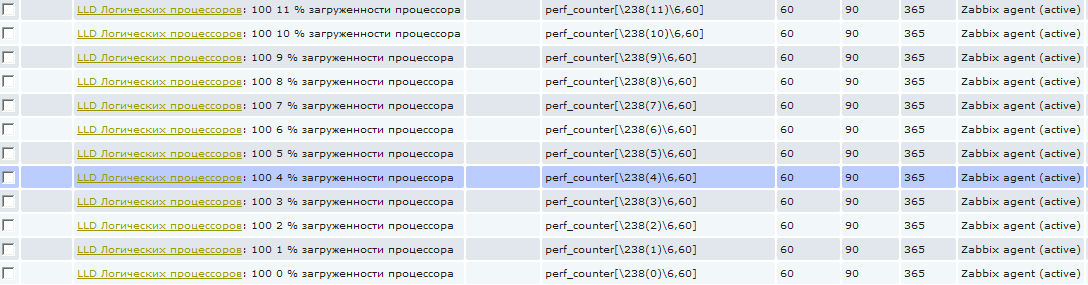
これらのアイテムは、標準的な方法では削除できません。 これらは自動的に作成され、低レベルの検出ルールの名前を持つ特別なプレフィックスで強調表示されます。 スクリーンショットでは、名前にいくつかのゴミが書かれているようです:)実際、すべてが単純で、各名前の3桁のコードを使用してソートします。 つまり、100は単なるソート番号です。 0〜11の次の数字は、論理プロセッサ番号です。 そして、「%CPU使用率」。 そして、最初はこれが0%のプロセッサ負荷であると思われるかもしれませんが、この値を収集しようとしています:)
この方法全体の唯一の欠点は、この投稿のタイトルなどのグラフを低レベルの検出メカニズムを使用して作成できないことです。 つまり、もちろん、 アイテムだけでなく、各論理プロセッサのグラフオブジェクトも作成できますが、検出されたすべての論理プロセッサで1つのサマリーグラフを自動的に作成することはできません。 少なくとも私は、これがどのように行われるかを知りませんでした、zabbixフォーラムで彼らは私に言うことができませんでした。 もちろん、これは特に深刻な欠点ではありませんが、ホストが200台ある場合は問題になる可能性があります:)。 結局のところ、各ホストのスケジュールは手動で作成する必要があります。
システム内の各物理ディスクのパフォーマンスを監視します
上記の方法を理解することをお勧めします。これにより、システム内のオブジェクトを監視するための非常に幅広い可能性が開かれます。
たとえば、サーバーにインストールされている物理ディスクのリソースが不足しているかどうかを判断する必要があることがよくあります。 ほとんどの場合、これらのデータはリアルタイムでキャプチャするのが難しいため、事後的に収集する必要があります。 これを行うために、物理ディスクに関する同様の検出を導入して、物理ディスクに関する広範な統計を収集しました。 そして、プロセッサーやデータ収集要素とは異なり、私はそれらを豊富に作成しました。
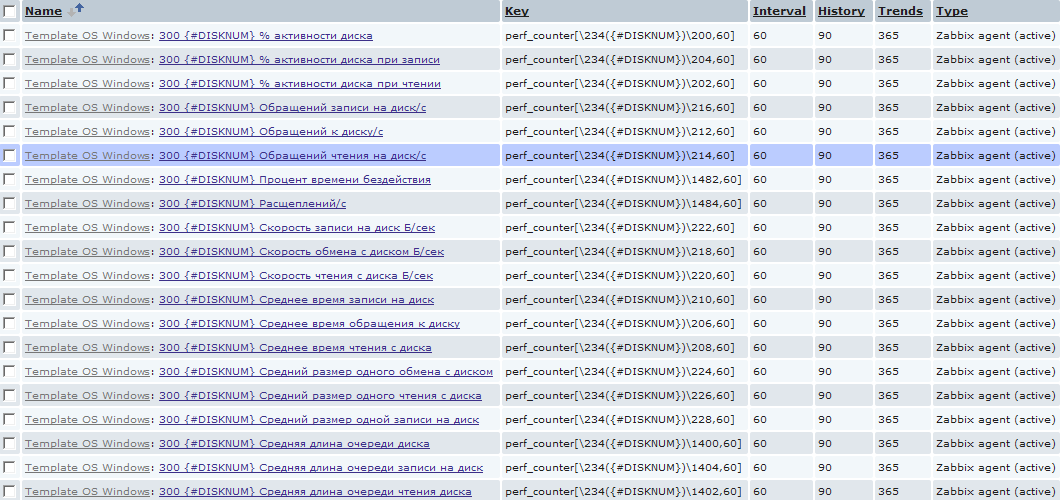
もちろん、ここでは注意する必要があります。古い詰まったコンピューターでmysqlを使用している場合、同様の量でデータベースがすぐに天国に移動します。 なぜなら 上記の例では、各ホストに対して、物理ディスクごとに20個の新しい要素が作成され、1分ごとに1つの新しい値が作成されます。 さまざまなディスクのヒープを持つ数十台のサーバーの規模では、これは多かれ少なかれ大量のデータに変換されます。 しかし、ここでは誰もが自分のサムライパスを自由に選択できます:)
LLD物理ディスクのスクリプトは次のようになります。
$items = Get-WmiObject Win32_PerfRawData_PerfDisk_PhysicalDisk | select name |where-object {$_.name -ne '_Total'} write-host "{" write-host " `"data`":[" write-host foreach ($objItem in $Items) { $line = " { `"{#DISKNUM}`":`"" + $objItem.Name + "`"}," write-host $line } write-host write-host " ]" write-host "}" write-host
CPUに似た新しい検出ルールを追加します。 同様に、 ディスカバリーに必要な要素を作成します。
一般に、もちろん、このメカニズムは監視のためのさまざまな要素を識別するためのかなり大きな機会を提供します。 同様に、たとえば、ネットワークインターフェース、システム内のプロセス、サービス、および名前と数量が事前にわからないその他の要素の監視を追加できます。
この記事がLLDに対処するのに役立つことを願っています ご質問にお答えします。