
そして、 MongoDBであろうとCassandraであろうと、彼らがどんな製品について話しているにせよ、宗教的熱意とa敬の念を、それが何か新しい神聖なものであるかのようにしばしば観察します。
特別なスリルは、いくつかの大陸の「マスターレプリケーションマスター」で動作するデータセンターの輪のように、ネットワーク内で点滅するアーキテクチャの脳を引き裂くスケッチによって引き起こされます。
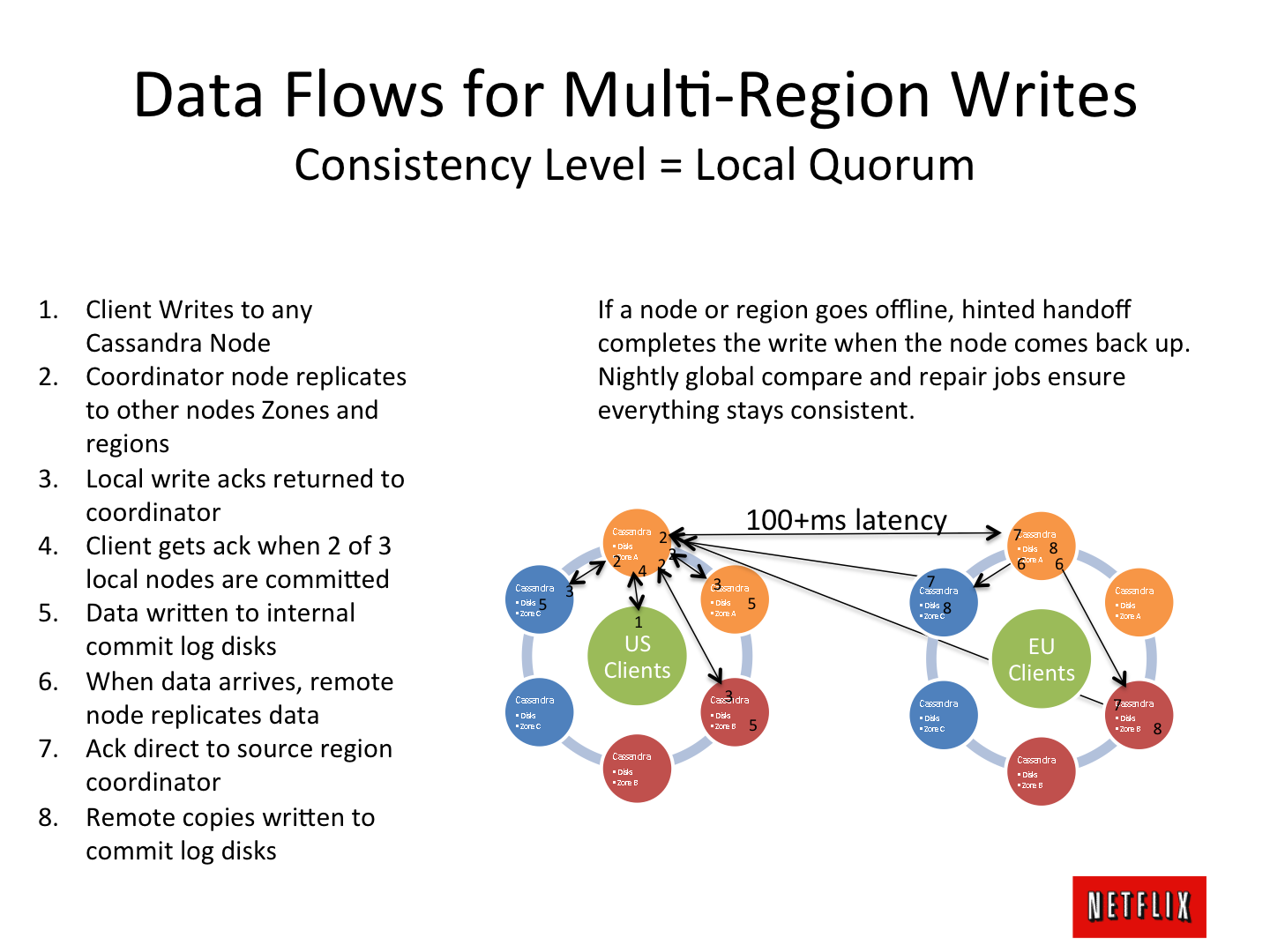
しかし...戦闘プロジェクトで「新しい」技術を真剣に使い始めると、それがどこから来たのか、これらまたはそれらのアーキテクチャ上の決定の理由は何かを理解できます:データセンターのリングや他の神秘主義-実用的でシンプルな「曖昧な」理解が形成されます-私はそれを共有したい建築上の間違いを犯さず、いかだに乗って海を渡らないようにするためです。 これについては、原則として、記事です。

古き良きACIDに合わないものは何ですか?
アトミック性、一貫性、トランザクション分離、コミットの信頼性など、すべてが提供されているようです。 試して、ビルドして、悪用してください。 ISO SQLはトランザクション分離レベルを規定していました-さて、完全な幸福のために他に何が足りなかったのですか?
スタイルで「CAP異端」の出現の原因は何ですか、3つのうち2つだけを選択しますか? :-)
- データの一貫性
- 利用可能
- 分離抵抗

答えは明らかです。ビジネスには新しい「超音速」データウェアハウス機能が必要です。
- ベースは常に書き込みと読み取りに使用できる必要があり、サーバーの再起動などの場合、ネットワークが落ちました-余裕がない
- データ量の集中的な成長と可用性の厳格な要件。 世界的なネットワークの急速な発展により、1つのデータベースに配置されなくなりました
- 世界のさまざまな地域に多くの顧客がいるため、できるだけ早く注文を保存する必要があります。
- Webサービスの急速な成長、モバイルデバイスの出現
「クラシック」データベースクラスターに適さないものは何ですか?
人気から:
- Oracle RAC-明らかに高価で難しく、重く、異なる大陸に分散する方法は?
- MySQLクラスターはクイックマスターですが、メモリにのみデータを保存するなど、多くの落とし穴と制限がありますが、場合によってはうまく機能します
- mysqlのgaleraクラスター -はい、正直なマスター、好きな場所に書き込みます(ただし、正確にどこを知る必要があります)が、「分離への抵抗」はありません。以来使用 データをすべてのコピーに同期転送します。 マスター間のデータシャーディングの有無
また、e-businessには以下が必要です。
- ベースは常に利用可能である必要があり、顧客の注文または彼のバスケットを失うことはできません データベースノード間の同期がなくなっても
- データベースはどこからでもアクセスできる必要があり(ヨーロッパおよび米国)、もちろん、コピー間でデータを同期する必要があります
- ベースは、データ量の増加に応じて無期限にスケーリングする必要があります
- ベースはロードに合わせてスケーリングする必要があります:書き込み、読み取り
この要求の流れがゆっくりだが確実に自殺につながったことは明らかです...
プログラマーが答える-できる!
...しかし、プログラマーに長い間不可能なことをするよう頼むと、彼らはそうするでしょう!

Cが本格的なプログラミングに十分であることを誰もが知っているわけではありませんが、美意識を持つ人々にとっては、C ++で魂を注ぎ出すことができます-いいえ、ビジネスからのプレッシャーの下で:「どのように速くプログラミングでき、誰もができるようになりますか?」-強力なテクノロジーハードウェアはすでに動作しています:C#、java、python、ruby ...
そのため、今世紀の初めに「NoSQL」 製品が登場してから可能になった時間はそれほど多くありません。
- 常にクラスターの任意の要素に書き込みます!
- クラスター要素を異なる大陸に配置し、ローカル大陸から読み取ります!
- クラスターのノードをすべて削除すると、システムが狂わなくなります!
- あなたの心が望むようにクラスターノードを追加してください。これにより、書き込みと読み取りの両方をスケーリングできます!
さらに、明らかに、 AmazonはDynamoDBでおの醸造を開始しました 。
DynamoDBは、大規模な非リレーショナルデータベースとクラウドサービスの分野で15年にわたって学んだ結果です。
そして、アイデアがFacebook Cassandraの形で複製され始めました。
Apache Cassandraは、Avinash Lakshman(AmazonのDynamoの作者の1人)とPrashant MalikによるInbox Search機能を強化するためにFacebookで開発されました。 2008年7月にGoogleコードのオープンソースプロジェクトとしてリリースされました。
そしてもちろん、 Google BigTableはそれなしではできませんでした。
これはどのような「銀の弾丸」ですか?
あなたは7つの帽子を縫いますか? そして、私は7つを縫います...
「NoSQL」製品の詳細な調査で、私が密接に協力した最後の製品はAmazon DynamoDB(Apache Cassandraに非常に似ています)でした。「隠された落とし穴と制限」が現れ始めました。
クラスターの任意のノードに書き込み、読み取り...
そして、デフォルトで、時代遅れの
クラスターノードを異なる大陸に配置できますが、...
しかし、繰り返しますが、情報が時間を要することを知っておく必要があります-それが大陸に広がると、アプリケーションはこれを処理できるはずです(責任の切り替えが見られます...プログラマーに再び... :-))。
クラスターの任意のノードをオフにし、ネットワークケーブルをaで切ることができますが、...
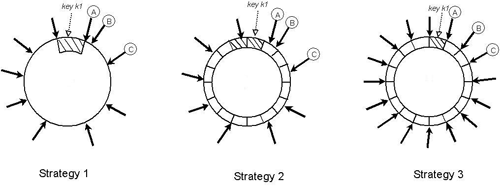
クラスター分割への抵抗は、バージョニングに類似したテクノロジーによって実装されますが、定期的に「マークルツリーを使用したアンチエントロピー」などの不一致の検索を実行する必要があります。
あなたの心が望むクラスターノードを追加します
可能ですが、まだクローバーとはんだごてを使用して、残りのノードを構成する必要があります。
そして、より興味深い。
Amazon DynamoDBの制限
プロジェクトでは、Amazonの主要なNoSQLソリューションであるDynamoDBを使用します。 以下で詳しく見ていきましょう。
データ型-率直に言って
数値、文字列、バイナリデータ。 DATETIMEは忘れてください(タイムスタンプでエミュレートできますが、不快になる場合があります)。
インデックスを追加できるのは、ただ...ただちに
インデックスはすぐに指定する必要があり、テーブルごとに5つ以下にする必要があります。 さらに、既存のテーブルにそれらを追加することはできません。データを削除、再作成、再ロードする必要があります。 建築家に静かな眠りを提供します。
データサイズ
任意の量のデータを保存できますが、...「列」の名前と値を含む1つの「表の行」のサイズは64KBを超えてはなりません。 確かに、「列」の数は制限されていません。
クラスターの1つのノード(メインハッシュキーインデックスの値が1つ)に追加のインデックスがある場合 、10 GBを超える値を格納することはできません 。
どうやら無駄に「列」を書いた。 「NoSQL」では、データスキームの概念が存在しないことが多いため、「テーブルの行」ごとに異なる「列」または「属性」が存在する可能性があります。
リクエスト...
1つのインデックスのみのデータを選択できます (メイン(ハッシュキー)インデックスはまだありますが、範囲選択はできません-定数のみです)。 1つのインデックスのみでソートします。
サブクエリは言うまでもなく、複雑なWHERE、GROUP BYを忘れてください-NoSQLエンジンは単純にそれらをエミュレートし、非常にゆっくり実行できます。
より複雑な選択を実行できますが、フルテーブルスキャンメソッド(悪名高いテーブルスキャン)を使用し、サーバーサイドで結果を要素ごとにフィルタリングします。これは長くて費用がかかります。
トランザクション-それは何ですか?
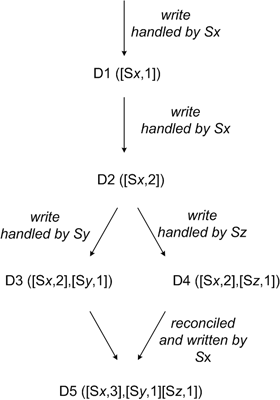
トランザクション...時々必要になります:-)、個々のエンティティのアトミック更新のみが保証されます(1回の操作で増分読み取りを行う本当に素晴らしいバンがあります)。 そのため、トランザクションをエミュレートする必要があります。そうでなければ、データが世界中の20のサーバー/データセンターで「拡散」している場合はどうでしょうか。
属性ダンス
多くの場合、NoSQLでは、 DynamoDBは、リレーショナル 理論の創始者を m笑し始め、次のようなラインで恐怖を生み出します。
user = john blog_post_ $ ts1 = 12 blog_post_ $ ts2 = 33 blog_post_ $ ts3 = 69 ...
$ ts1-3は、ユーザーのブログ投稿のタイムスタンプです。
はい、1回のリクエストで出版物のリストを取得すると便利です。 しかし、プログラマーの仕事は増えています。
結論
1)NoSQLプロジェクトのリポジトリを選択する前
2) ブリューワーの定理をもう一度読み直して、トリックを見つけてください:-)
3)使用する製品のドキュメント、特に制限事項を注意深く見てください。 おそらく、あなたは多くの驚きに出会うでしょう-そしてあなたはそれらに注意深く準備する必要があります。
4)最後にCodduの目を見る

はい、柔軟なレプリケーションスキームをサポートする非常に信頼性が高く、アクセスしやすい最新のソリューションを取得できますが、残念ながら、アプリケーションロジックの最も厳しい非正規化と複雑さ(トランザクションのエミュレート、アプリケーション内の大量のデータのジャグリングなど)を支払う必要があります。 選択はあなた次第です!
皆さんに幸運を!