RabbitMQを知ろう
Habréの翻訳:
RabbitMQチュートリアル1-Hello World
RabbitMQチュートリアル2-タスクキュー
RabbitMQチュートリアル3-発行/購読
すぐにいくつかの欠点を補います。 そして、基本的な用語を簡潔に繰り返します。
rabbitMqを使用したアーキテクチャの仕組み
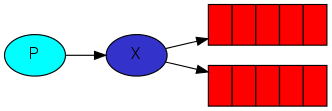
メッセージを生成するアプリケーション(クライアント)があり、メッセージは交換ポイントに到達し、メッセージパラメーターと交換ポイントの設定に応じて、メッセージは1つ以上のキューにコピー(または単に削除)され、その後クライアントはキューからメッセージを取得できます。
キューは、ルーティングキーまたはメッセージヘッダーを使用して交換ポイントに関連付けられます。
ルーティングキー -メッセージが交換ポイントに発行されるときに指定される値は、メッセージが分類されるキューを決定するのに役立ちます。
メッセージヘッダーは、 メッセージに関連付けられたキーと値の引数のセットです。
交換ポイントには4つのタイプがあります。
- direct-この交換ポイントに到達したメッセージは、厳密なルーティングキーを持つ交換ポイントに関連付けられているキューにのみコピーされます。
- topic-ルーティングキーは合成でき、パターンの形式で設定できます。2つの特殊文字があります。 * -1つの単語を示し、 # -1つまたは複数の単語。 単語はピリオドで区切られます。 例:routingKey = "* .database"-2番目の単語がデータベースを意味するキーを持つすべてのメッセージは、パターンによってバインドされたキューにコピーされます。
- ヘッダー -キューはルーティングキーではなく交換ポイントに接続されますが、メッセージヘッダーによって条件が示され、どの引数とその値が期待されるか、交換ポイントが条件からの引数を含むヘッダーを持つメッセージを受信すると、キューはそれを受信します。 例はここにあります 。
- ファンアウト -交換ポイントで受信したメッセージは、ルーティングキーまたはメッセージヘッダーをチェックせずに、接続されているすべてのキューにコピーされます。
各キューには、その動作を定義する4つのフラグがあります。
- auto_delete-キューが空で、アクティブな接続がない場合、キューは自動的に削除されます
- 永続的 -安定したキュー、rabbitMQの再起動(または突然の再起動)、公開時、およびアップロードの終了時まで、メッセージはデータベースに保存されます
- 排他的 -キューは、一度に複数の接続用に設計されていません
- パッシブ -キューがパッシブと宣言されたとき、クライアントがサーバーに接続すると、キューがすでに作成されていると見なされます。 不在の場合は自動的に作成されません。このオプションは、状態を変更せずにサーバーに接続する場合に必要です。 たとえば、キューが存在するかどうかを確認するだけです。 これを行うには、キューをパッシブに宣言します。エラーが発生した場合、キューは存在しません。
開発者が公式ドキュメントに書いているように、ウサギの作業について少し説明します。サービスとしてインストールして開始するとき、デフォルトの設定が使用されます 。これはほとんどのシナリオで十分なはずですが、十分な設定がある実際の製品で状況を見たことはありませんデフォルトで。 動作パラメータは、ユーティリティユーティリティ(\ rabbitmq_server-3.2.0 \ sbinディレクトリにあります)を使用して実行時に変更できますが、この方法で行った変更は、rabbitmqの再起動時(および再起動時)に失われます。 次のトピックに進みます。
RabbitMQの構成
RabbitMQサーバーの操作構成は、 環境変数 (ポートと場所、ファイル名が設定されている)、 構成ファイル (アクセス設定、クラスター、プラグイン)、 ランタイムで指定されている設定 (ポリシー、パフォーマンス設定)の3つの場所にあります 。
Windowsにインストールする場合、構成ファイルは作成されません。\ rabbitmq_server-3.2.0 \ etc \ rabbitmq.config.exampleディレクトリにあるのはその例のみです。 構成ファイルを作成し、rabbitmq.configと呼びます(拡張子は.configで、他には何もありません!)
%% Sample [ {rabbit, [ {tcp_listeners, [5672]}, {log_levels, [{connection, error}]}, {default_vhost, <<"/">>}, {default_user, <<"username">>}, {default_pass, <<"password">>}, {default_permissions, [<<".*">>, <<".*">>, <<".*">>]}, {heartbeat, 60}, {frame_max, 1048576} ]} ].
<< >>のフレーミングは間違いではありません。
設定内のコメントの前には、二重パーセント記号-%%が付いています。
ここで、RabbitMQサーバーがインストールされているルートフォルダーなどの便利な場所にファイルを配置します。たとえば、パスがあるとします。
c:\ rabbitmq \ rabbitmq.config
RabbitMqが構成ファイルを表示するには、その場所で環境変数を作成する必要があります
RABBITMQ_CONFIG_FILE = c:\rabbitmq\rabbitmq
ユーザーの環境とシステム環境の両方で変数を作成する価値があります。
ファイル名へのパスを記述し、拡張子を削除します。 ファイル構成の作成と環境のセットアップは、RabbitMQサーバーをインストールする前、またはインストール後に再インストールするのが最適です。 (環境の変更を有効にするには、サービスを再インストールする必要があります。)単純な再起動は役に立ちません。
これで、 ErlangとRabbitMQサーバーをインストールできます。
クラスターを作成して構成する
ご注意
, RabbitMQ : RabbitMQ\RabbitMQ Server\rabbitmq_server-3.2.1\sbin
rabbitMQのクラスターは、1つ以上のRabbitMQサーバーの相互接続であり、ノードの1つがマスターサーバーとして機能し、残りがスレーブサーバーとして機能し、ウィザードはそれらにスレーブに複製されるクラスター設定を設定します。これらには、アクセス設定とポリシーが含まれます。 マスターが倒れると、スレーブの1人が役割を引き受けてマスターになります。
まず、クラスターを作成する前に、ノードのRabbitMQ Cookieを同期する必要があります。RabbitMQのCookieは、インストール中に生成されたハッシュであり、ノード識別子として使用されます。 クラスターは単一ノードとして機能し、各サーバーでCookieは同一である必要があります。
マスターサーバーでファイルを取得します
%WINDOWS%\.erlang.cookie
途中で交換してコピーします
C:\Users\%CurrentUser%\.erlang.cookie
、その後、指定されたパスの各クラスターノードを置換してコピーします。
クラスタは、各スレーブで次のコマンドを実行して作成されます。
rabbitmqctl stop_app rabbitmqctl join_cluster --ram rabbit@master rabbitmqctl start_app
または、構成ファイルで指定することにより:
{cluster_nodes, {["rabbit@master", "rabbit@host01"], disc}}
この手順は、新しいノードを追加するときに一度だけ実行する必要があります。将来、ノードはクラスターに自動的に接続します(たとえば、ノードが起動されているサーバーを再起動した後)。
クラスターは作成されますが、完全な使用には適していません。現在の段階では、各ノードのキューとメッセージは別々に存在し、同期は実行されません。つまり、2つのクライアントがクラスターに異なるノードに接続し、そのうちの1つがキューにメッセージを投稿すると、2番目のそれについて何も知りません また、ノードの1つがクラッシュすると、そのノードにあったすべてのメッセージが失われます。
同期ポリシー
ツールに移動して、実行時に次のコマンドを実行します。
rabbitmqctl set_policy HA ".*" "{""ha-mode"": ""all""}"
これで、それらのすべてのキューとメッセージが同期されます。 メッセージが公開されると、クライアントはクラスターのすべてのノードにコピーした後にのみ利用可能になります。
1つの問題がありました。ノードの1つがクラッシュすると、それに接続するクライアントがクラッシュの事実を判断し、使用可能なノードに切り替えることができる必要がある、とRabbitMQ開発者は書いています:
クライアントアプリケーションのクラスターに接続します。
クライアントは、クラスター内の任意のノードに接続できます。 クラスターの残りの部分が機能し続けている間にノードが落ちた場合、それに接続するクライアントは、フォールの事実を判断し、クラスター、作業ノードに再接続できる必要があります。 原則として、すべてのクラスターノードの実際のIPをクライアントアプリケーションに追加することはお勧めしません;これは、アプリケーション自体の動作とクラスター構成の両方の柔軟性を妨げます。 代わりに、より抽象的なアプローチを使用することをお勧めします。TTL値が非常に小さいDNSサービス、単純なTCPバランサー、またはモバイルIPなどのテクノロジーを使用できます。 一般に、この側面はRabbitMQの範囲外であり、これらの問題を解決するために開発されたテクノロジーを使用することをお勧めします。
つまり バイクを書くのではなく、既製のソリューションを使用することをお勧めします。私のバージョンでは、Windowsに組み込まれたネイティブソリューションとしてNLBを使用しています。 このステップはあなた次第です。
有用性
コマンドラインからノードにpingを実行します。
rabbitmqctl eval "net_adm:ping(rabbit@hostname)."
ノードが利用可能な場合、回答ポンを取得します
参照資料
www.rabbitmq.com/clustering.html
www.rabbitmq.com/ha.html