今日、Real Time MapReduceテクノロジーについてお話したいと思います。おかげで、これらすべてが可能になりました。 このタスクに必要な大量のデータの転送と処理を提供します。これを行うために、すでに使用したMapReduceのコードを書き換える必要さえありませんでした。

検索結果をパーソナライズするには、ユーザーの興味を判断する必要があります。ユーザーの興味については、検索ページにユーザーの行動に関する情報を保存します。 ユーザーの行動に関するデータはログに記録され、その後、個々のユーザーごとに最も関連性の高い検索結果を収集できる特別なアルゴリズムを使用して処理されます。 最初は、ログ処理が1日に1回開始され、 MapReduce分散コンピューティングテクノロジーが非常に適していました。 彼女は大量のデータの分析に対応しています。
着信データ(この場合、これらはログです)は、いくつかの連続するステップMap(データはキーで分割されます)とReduce(特定の機能に対して計算が実行され、結果が収集されます)を通過します。 この場合、各ステージで発生する計算の結果は、次のステージの入力データになります。 各Reduceステップで特別なアルゴリズムを実行することにより、データ量が削減されます。 その結果、大量の生データから少量の有用なデータを取得します。
ただし、以前の投稿ですでに述べたように、ユーザーには一定の関心だけでなく、瞬間的な関心もあり、文字通り数秒で置き換えることができます。 そして、ここで毎日の処方箋のデータはもはや役に立ちません。 このプロセスを30分に加速できます。一部のログはこのような頻度で処理されますが、タスクには即座に対応する必要があります。 残念ながら、MapReduceを使用する場合、処理の性質により明確に定義された反応性の上限があります。
処理ステージは厳密な順序で実行され(結局、各ステージは次で処理されるデータを生成します)、1つのキーで最終結果を取得するには、すべての処理の終了を待つ必要があります。 入力データにわずかな変更があった場合でも、再カウントせずにこれらの変更の影響を受ける中間結果を特定することは不可能であるため、ステップチェーン全体を再実行する必要があります。 着信データが絶え間なく流れているため(また、検索エンジンからは約200 MB / sの速度のストリームがあります)、そのようなシステムは効果的に動作できず、この方法を使用して数秒でユーザーアクションへの応答を達成することはできません。
しかし、入力データにわずかな変更を加えただけで、最終結果を迅速に変更できるシステムが必要です。 これを行うには、変更の結果としてどのキーが変更されるかを決定し、それらについてのみ再カウントできる必要があります。 したがって、各段階で処理されるデータの量が削減され、同時に処理速度が向上します。
Yandexには、クラシッククラスターアプリケーションを使用するプロジェクトがいくつかあります。データはノードに分割され、その間でメッセージが交換され、完全に再カウントせずに個々のキーの状態を変更できます。 ただし、ログの処理を伴う複雑な計算の場合、メッセージハンドラに過度の負荷がかかるため、このようなモデルは適していません。
さらに、検索の品質を保証する蓄積されたコードのほとんどは、MapReduceで記述されています。 そして、わずかな変更を加えたこのコードのほとんどすべてを再利用して、ユーザーアクションをリアルタイムで処理できます。 そのため、MapReduceインターフェースと同一のAPIを備えたシステムを作成するというアイデアが生まれましたが、同時に受信データの変更の影響を受けるキーを独立して認識できます。
建築
当初、この考え方は非常に単純に思えました。MapReduce関数を計算できるアーキテクチャを作成する必要がありましたが、入力データのわずかな変更で関数の値を増分的かつ効率的に更新することもできました。 最初のRealTime MapReduce(RTMR)プロトタイプは2週間で完成しました。 ただし、テストプロセス中に、弱点が明らかになり始めました。
それとは別に、すべての問題は些細なことのように思えましたが、この規模のシステムでは、すべてを相互にリンクすることはそれほど単純ではありません。 その結果、すべての問題を解消した後、元のプロトタイプには事実上何も残っておらず、コードの量は1桁増加しました。
さらに、必要な動作速度を確保するために、計算に関係するすべてのデータをメモリに保存する必要があることが明らかになりました。そのために特別なアーキテクチャを実装しました。
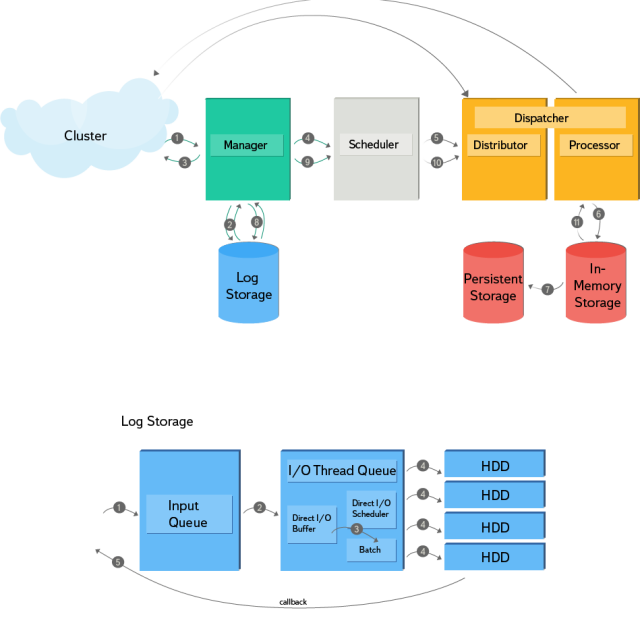
図に表示される一連のアクションをより詳細に分析してみましょう。
- すべては、着信要求ハンドラーがデータを解析し、キーごとに個別のトランザクションを開始するという事実から始まります。
- この場合、トランザクションは、操作の開始の記録(PrepareRecord)がディスクに保存されていることの確認を受け取った後にのみ起動されたと見なされます。
- トランザクションが開始されると、着信要求に対する応答がネットワーク経由で送信され、トランザクションはワークフローによる処理のためにキューに入れられます。
- 次に、ワークフローはトランザクションを取得し、キーの場所に応じて、ネットワークを介して送信して確認を待つか、操作が実行される処理コンテンツを作成します。
- 将来的には、トランザクションは相互に分離して処理されます。開始後、ブランチはシステムの一般的な状態から削除され、処理が完了すると変更が受け入れられます。
- すべてのデータはメモリに保存されます。これは、reduce操作を最適化するために非常に重要です。
- 変更されたキーのデータは、バックアップとして永続ストレージに定期的に保存されます。
- トランザクションの処理後、その結果はディスクに記録され、ログから記録確認を受信すると、完了したと見なされます。
- また、トランザクションは子トランザクションを生成できます。この場合、4番目の段落からすべてが繰り返されます。
- 状態を復元するプロセスでは、データが永続ストレージから取得され、ログによって再現され、不完全なトランザクションが再開されます。 トランザクションを中止する必要がある場合、AbortRecordがログに書き込まれます(状態が復元されたときにこのトランザクションを再起動する必要がないことを示すインジケータ)。
図の2番目の部分は、ログストレージの原理を示しています。 着信キューを使用した非同期記録、および通知のコールバックをサポートしています。 ディスクは、キーでレコードをフィルタリングするための追加専用の構造とインデックスを実装しています。 アダプティブスケジューラは、読み取り操作の統計情報を使用してレコードのサイズを決定し、書き込み速度と開始前の待機時間の最適なバランスを見つけます。 ログストレージは、キーシャーディングを備えたRAIDなしの4台のHDDで構成されます。 ダイレクトI / Oは、データをディスクに書き込むために使用されます。
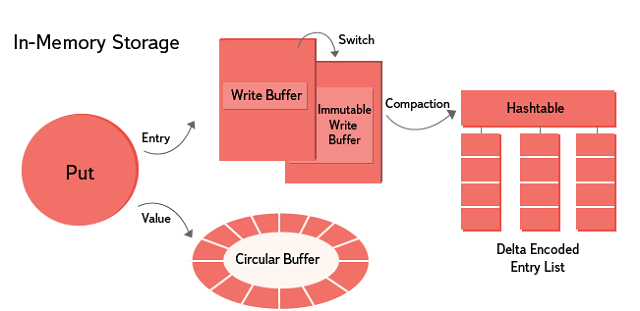
メモリ内ストレージは、順次書き込みおよび並列読み取りのアプローチを実装しています。 シャーディングはキーごとに実行されます。 データは設定で指定された期間保存され、その後新しいデータで上書きできます。 ロックフリーリングバッファーは、値データを格納するために使用されます。 レコード(キー、サブキー、テーブル、タイムスタンプ+追加情報)の場合、追加のみのロックフリースキップリストが使用されます。 スキップリストに入力すると、新しいリストが作成され、古いリストが既存の不変データとマージされます。 キーごとに、エントリがソートされ、デルタエンコードされます。
クラスター内のノードの調整は、Zookeeperを使用して実行されます。 マスター/スレーブの定義は、一貫したハッシュを通じて行われます。 発信トランザクションはウィザードによって処理され、さらにスレーブに保存されます。 スライスは、マスターとスレーブの両方に配置されます。 再シャッフルすると、新しいマスターはクラスターのスライスからデータを収集し、キーの範囲内のログから未処理のトランザクションを収集し、その状態に追いつき、処理に含まれます。
RealTime MapReduceの展望
RTMRの検索をパーソナライズすることに加えて、他のアプリケーションを見つけることができることに注意してください。 ほとんどの場合、検索で使用されるアルゴリズムは、リアルタイムで動作するように再配置できます。 たとえば、最近のドキュメント、メディアやブログでの出版物の検索品質を向上させることができます。 実際、新しいドキュメントのランキングは、クロールとインデックス作成の速度だけでなく、これは最も難しいプロセスではありません。ほとんどの場合、私たちのロボットはこれを数秒でかなり長い間行ってきました。 ただし、ランキングのデータの大部分はドキュメント外部の情報ソースから取得され、MapReduceを使用してこのデータを集約します。 上記のように、バッチ処理方法の制限により、20〜30分よりも速く集計を実行することはできません。 したがって、RTMRがないと、新しいドキュメントの外部信号の一部に遅延が生じます。
検索ヒントのカスタマイズもすぐに実行できます。 その後、ユーザーに提供されるクエリオプションは、数秒前に探していたものに依存します。
私たちのシステムはまだ十分に新しいので、近い将来、MapReduceパラダイムを拡張します。リアルタイムでの作業に特化した新しいインターフェイスを追加します。 たとえば、予備的な不完全な事前集計を実行できる操作。
さらに、MapReduceとRTMR向けに統一されたデータフローと計算のグラフの宣言的な記述を作成する予定です。 MapReduceとは異なり、異なるキーのRTMR計算の段階は順番に機能しません。つまり、コードから段階を順番に開始しても意味がありません。