はじめに
これまで、データセンター向けの機器セグメントでは、ファーウェイからのオファーはありませんでした。 昨年の第3四半期に、ファーウェイは主にパートナー向けに、この新製品に特化したプロモーションプログラム(データセンター用の一連のスイッチ)を開始しました。
ファーウェイが一度にいくつかの目標を設定し、新しい機器ラインを作成したことは間違いありません。
1.市場に出ている会社が提供する機器の範囲のギャップを埋める
2.追いつき、主要な競合他社に先んじる
そして、会社がこれらの目標を達成したことは確かです。
現代のデータセンターの多くのニーズの中には、ますます増加する帯域幅要件があります。 これらの要件は、まず、ネットワークサブシステムによって統合された数万台のサーバーによって決定されます。 サーバーをSPDに接続する主な方法については予測があります。 これに関して、ラインカード上のどのタイプのポートといくつが関連するかを予測することができます。

図 1データセンターで使用されるサーバーインターフェースの種類の予測
帯域幅に加えて、管理上および技術上の重大な問題があります。
-データセンター内または1つの会社のデータセンター間の仮想マシンの移行。
-L2およびL3(OSI)でセグメント化されたネットワークのトラフィック管理。
-スイッチング機器などでこの標準がサポートされていないデータセンターの場所へのストレージネットワークトラフィックの転送。
もちろん、ベンダーVMWareやCiscoなどのソリューションを組み合わせて適用することで、すべての問題が解消されます。 また、Huaweiは、オープンAPIを備えたnCentreシリーズソフトウェア製品から始まり、あらゆる規模のデータセンターのデータ転送サブシステムへのサードパーティベンダーハイパーバイザーとの統合機能を備えた単一ベンダーソリューションを提供します!
それで、CloudEngine。 Huaweiは、ライン全体を2つの大きなセグメントに分割しました。これらはCOREおよびTORデバイスです。 COREデバイスは、データセンターの「中心」として位置付けられ、すべてのデータストリームを通過し、最高のフォールトトレランスを提供します。 TOR(Top-Of-Rack)デバイスは、ラックアグリゲーターとして機能し、サーバー、ディスクアレイ、または効率の低いネットワークデバイスからトラフィックを収集します。 機能区分に基づいて、外部パフォーマンスには基本的な違いがあります。 すべてのTORデバイスは単一ユニット設計であり、COREはさまざまなシャーシに基づいており、図には示されていないCE12816を含む現在までの4つのオプションがあります。 2。

図2-CloudEngineスイッチファミリー
ちなみに、データセンターも属している大規模なエンタープライズレベルのネットワークは、マルチレベルスキームで理想化して記述できます(図3)。 以下は、すべてのタイプのデバイスのCloudEngineファミリーの位置付けです。
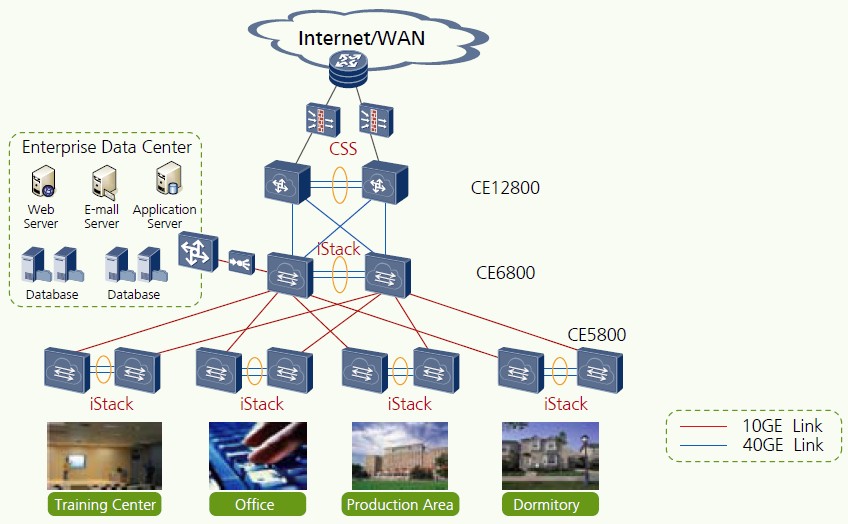
図3-大規模なエンタープライズLANの理想的なネットワーク構造
次に、Huaweiがこの機器の潜在的な所有者に提供する興味深いものを検討します。 新しいスイッチのハードウェアとソフトウェアの利点を考慮してください。
ハードウェアの構造と機能
Huaweiは、COREデバイスで優れた競争力のあるパフォーマンスを実証します。
1.内部スイッチングバスの帯域幅はスロットごとに最大2 Tbit / sで、将来最大4 Tbit / sのソフトウェア拡張の可能性
2.高いポート密度-スロットあたり最大96x10Gおよび24x40Gポート。 CE 12816シャーシの1536x10Gポートの合計ポート密度。
3.データ転送中の超低レイテンシ-フレーム長に関係なく2〜5マイクロ秒
4.シャーシエレメントのホットスワップ機能により、デバイスの可用性が高くなります。
5.エネルギー効率は市場平均より50%高い
競争入札分析
スイッチのCloudEngineラインの主な利点は、まず、他のベンダーのデバイスの同様のインジケーターの制限を大幅に超えるポート密度とデータ転送速度の数値です。 図4の小さな競合比較
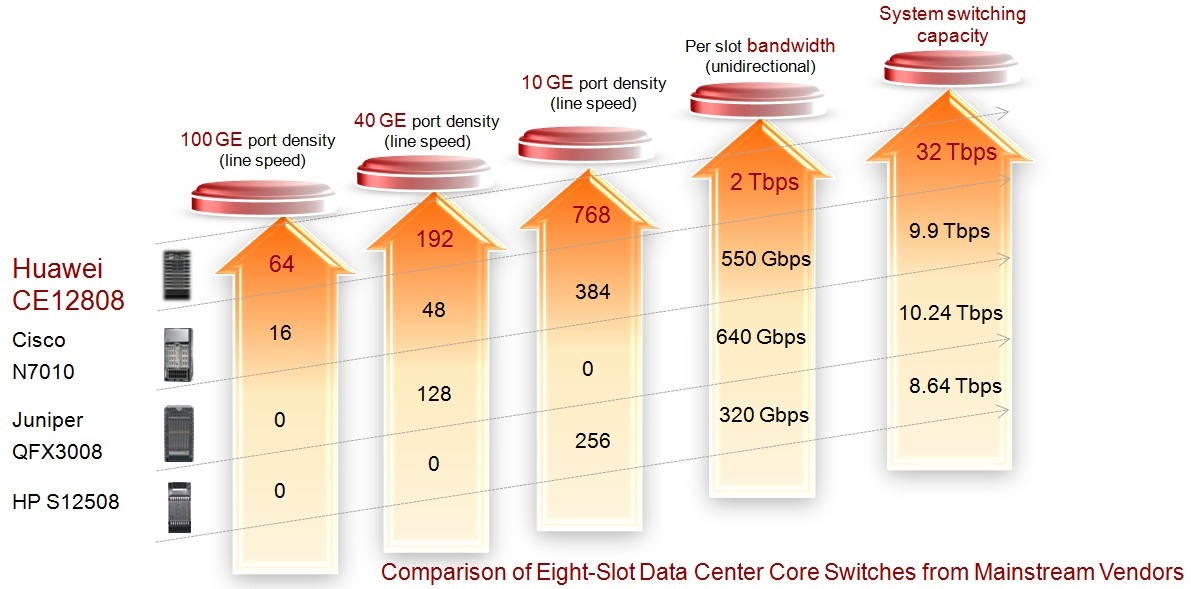
図 4競合比較
このような高いスイッチング速度と低遅延を実現するもの:
-CloudEngine12800シリーズスイッチでは、各ラインカード(LPU-ラインプロセッシングユニット)と各スイッチファクトリ(SFU-スイッチファブリックユニット)の物理的な接続が実装されています。 実際、行列MxNが取得されます(図5)。
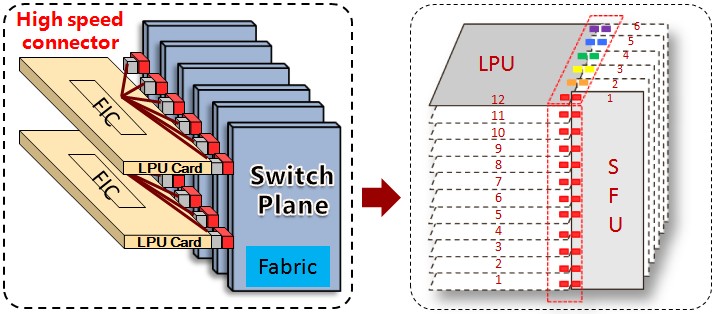
図5 LPUとSFUの内部接続方法
-LPU間でトラフィックを転送する場合、動的なノンブロッキングCLOSアーキテクチャが使用されます (図6)。 アプリケーション内のKloseネットワークの説明を含む資料へのリンク。

図 6ノンブロッキングCLOSアーキテクチャ
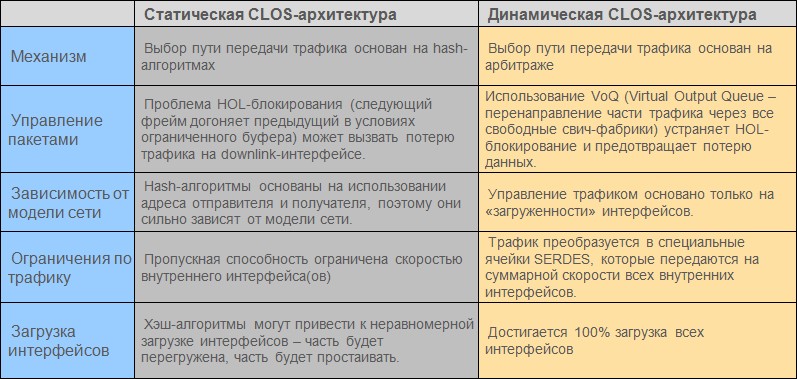
この技術とSPUおよびLPUボードの切り替え方法により、いつでもデバイスのすべてのスイッチファクトリをデータ転送に使用できます。 多くの同様のデバイスで使用される静的CLOSアーキテクチャには、いくつかの欠点があります。 2つの実装の比較を表1に示します。
表1
もちろん、高いポート密度は、バスを介してすべてのトラフィックを転送する能力に依存します。そうしないと、意味がありません。 上記のCloudEngineで示したように、これは問題ではありません。 ポイントは小さいです-LPUの生産的なプラットフォームを選択してください! ちょっとしたトリックを適用してください!
図7は、24個の40Gポートを搭載したCE 12800プラットフォームで最も生産性の高いラインカードを示しています。 したがって、960 Gbit / Cの合計転送速度が達成されます。

図 7-リニアLPUカードCE-L24LQ-EA
ただし、ポートの数を劇的に増やす必要がある場合は、トリッキーなデバイス(「スプリッター」)を使用できます(図8)。
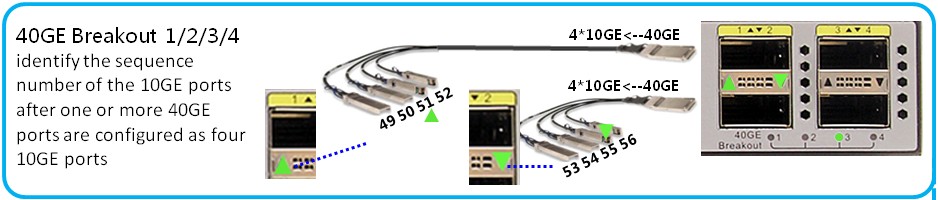
図 8-ディバイダー
実際、特別なQSFPモジュール内には4つの独立したモジュールがあり、それぞれが独自の波長で動作します。 単一の40Gインターフェイスの代わりに、スイッチは4x10Gを定義し、CE-L24LQ-EAボードにはすでに最大24x4x10G = 96Gのインターフェイスがあります! ちなみに、ボードでは40Gと4x10Gのインターフェースを組み合わせることができ、制限はありません。
上記のように、CMU(制御管理ユニット)、LPU、MPU(メインプロセッシングユニット)、SFU、
PMU(電源管理ユニット)、PSU(電源ユニット)およびFAN。 さらに、CE12800ファミリのすべてのデバイスについて、スイッチファクトリを除くすべてのボードは同一です! 図9は、冗長シャーシコンポーネントの方法を示しています。
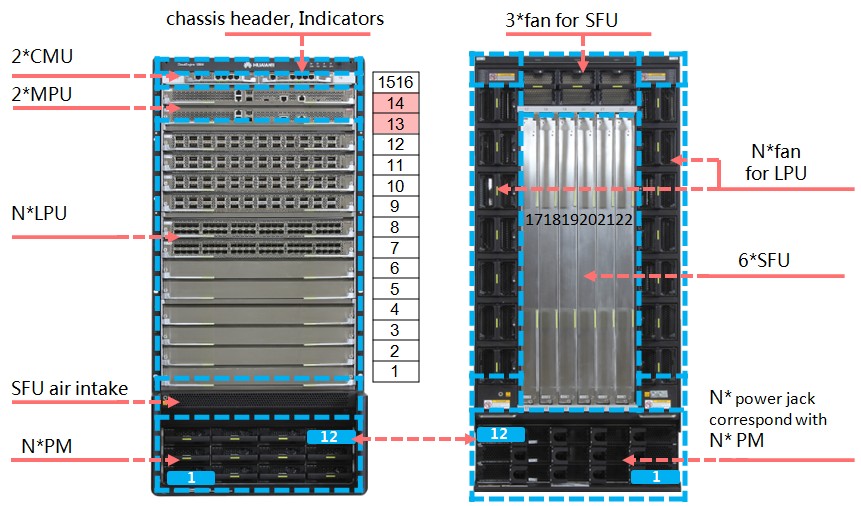
図 9 CE12800シャーシコンポーネントの冗長性
CE12800シリーズ機器のエネルギー効率は、次のソリューションによって達成されます。
-高度に統合されたチップの使用。 つまり ボード上の多数のマイクロ回路を冷却する代わりに、冷却する必要があるのはごくわずかです。
-ほとんどすべてのプロセッサとASICは45 nmテクノロジを使用して作成されており、このようなコンポーネントの消費電力を大幅に削減できます。
-特許取得済みの冷却システム、つまりシャーシの内部構造。 これにより、隣接するラックへの相互の影響を心配することなく、データセンターにCE12800デバイスを配置し、暖かい廊下と冷たい廊下を整理できます。 (図10-11)。
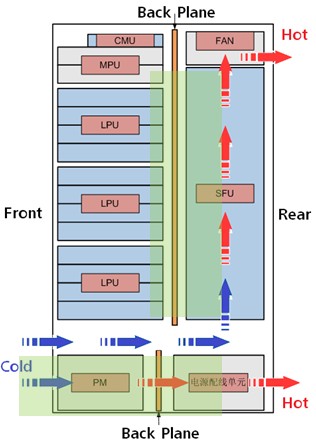 | 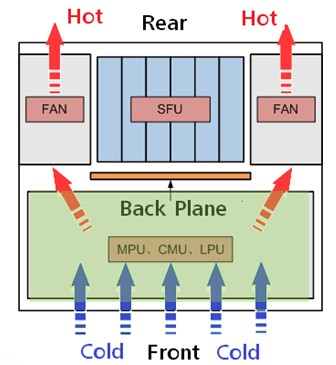 |
| a)右側の側面図 | b)上面図 |
図 10特許取得済み冷却システム
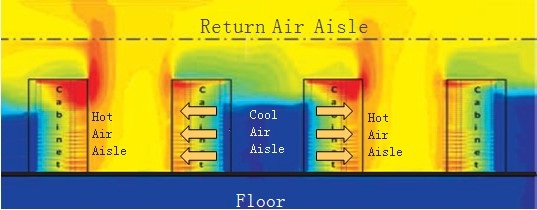
図 11熱い廊下と冷たい廊下の熱分布
プログラムの構造と機能
ファーウェイは、独自のモジュラーオペレーティングシステムVRP(Versatile Routing Platform)を非常に積極的に開発していることに注意する必要があります。 開発の歴史を通じて、VRPはVRP1からVRP5に多くの変更を経てきました。特にCloudEngineの場合、開発者はVRP8をリリースしました。
VRP8の主な機能:
1.仮想サブシステムの仮想化とリソース管理のサポート、
2. CSSクラスタリング(クラスタースイッチシステム)およびDCB(データセンターブリッジング)のサポート
3. TRILLネットワークテクノロジーのサポート(多くのリンクの透過的な相互接続)
4. FCoE(イーサネット経由のファイバーチャネル)をサポート
5.構成管理システムの改善
より詳細に。
仮想化 データセンタークライアント向けの追加サービスとして、ファーウェイはサーバー側だけでなくネットワークの仮想化も検討することを提案しています。 データセンター内で完全に独立し、インフラストラクチャ全体を独立して管理したい人にとっては、CloudEngineをレンタルする機会は完璧です(図12)。
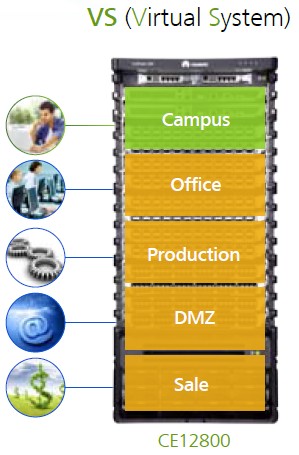
図 12-CE12800に基づいた仮想システムの使用モデル
仮想化は次のおかげで可能です。
-デバイスのマルチコアマルチプロセッサモデルの使用、
-モジュラーオペレーティングシステムの適用
仮想システムには次の機能があります。
-個別管理、転送、管理、およびサービスプレーン、
-仮想システムに個別に割り当てられたラインカードまたはカードポート、
-個別に割り当てられたシステムリソース(I \ O、CPU、Mem)および構成
-他の仮想システムからの完全な分離
クラスタリング ファーウェイのイノベーションは、CE12800のCSSテクノロジーとTORのiStackであり、複数の物理スイッチを1つの論理スイッチに結合して、ネットワーク管理を簡素化し、信頼性を向上させることができます。
CSS(クラスタースイッチシステム)の場合、従来のスタックとの違いは次のとおりです。
-特別なカードとラインカードポートの両方を使用して関連付けが実行されます(最大16ポート)
-クラスタ内のポートとスイッチシャーシ間のインテリジェントな負荷分散
-クラスタコンポーネントは、かなりの距離(最大80 km)離すことができます。
-任意のタイプの12800シャーシをクラスターに結合できます。
CSSのスイッチの最大数は4です。CE6800/ 5800シリーズは、最大16台のスイッチのスタックをサポートします。 図13のCSSの簡単な使用例。

図 13バックツーバックモデル、2つのVLANのトラフィック管理の例。
TRILL 。
-ECMP(Equal Cost Multi Path)、プライマリ接続とバックアップ接続の両方を使用する機能のサポート
-トラフィックのルート選択メカニズムに基づくSPFアルゴリズム、CLOSアーキテクチャのトラフィックモデルの適応
-ユニキャストおよびマルチキャストトラフィック用の単一のコントロールプレーン
-高い収束率
-1つのTRILLドメイン内の多数のデバイスのサポート(500を超えるスイッチ)
TRILLプロトコルのこれらすべての機能により、クラウド内の仮想サーバーとデータセンター内の実際のサーバーを完全に透過的に作成および移動できます。
より多くのTRILLについては、以下の記事で説明します。
FCoE 既に述べたように、HuaweiはCloudEngineデバイスにFCF(FCoE Forwarder)機能を最初に実装しました。 これにより、現代のニーズに合わせて既存のネットワークを導入したり、新しいネットワークを設計したりすることができました。 図 図14は、データ送信装置の機能とデータ記憶システムのトラフィックを組み合わせた結果を示している。
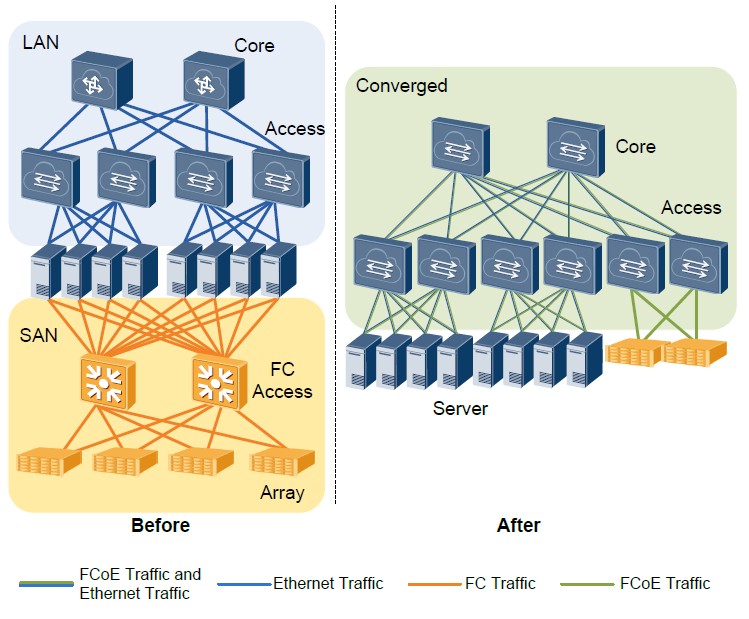
図 14統合ネットワークへの移行
おわりに
この記事では、Huawei機器の新しいライン、およびCloudEngineシリーズ機器に実装された最新のソフトウェアおよびハードウェアテクノロジーに関する情報をインターネットに公開することを試みました。 次の記事で、いくつかの点を詳しく説明し、いくつかの点を詳しく説明します。
この記事では、パブリックドメインではない「公式に使用する」資料を部分的に使用しています。