
サイトの読み込みに費やされるトラフィックはどれくらいですか? ほとんどの場合、これらは写真であり、その「重量」の合計は、マークアップ、スクリプト、およびスタイルの数倍になることがよくあります。 広く普及している画像ファイル形式では、ラスターデータは圧縮形式で保存されます。これは、非圧縮BMPよりもはるかに優れています。 そして、さらに良くしたい場合は? 確かに、かなり大きなプロジェクトでは、各バイトがカウントされます(たとえば、TradingViewでは、これは本当に恥ずかしがり屋です)。
高度に特殊化されたものから全能性の組み合わせまで、グラフィックを圧縮するための多くのユーティリティがあります。 habrはすでにそのようなプログラムの素晴らしい概要を持っています 。そして、どのように写真を絞るのかという問題は詳細に検討されています。
しかし、 そのようなプログラムはどのように機能し、何を改善でき、独自のプログラムを作成するのでしょうか? 画像形式とラスターデータ圧縮アルゴリズムの観光ツアーに招待します。
中世
前世紀の80年代は、ラスターグラフィックスの開発の時代になりました。 グラフィックスは以前から適用されていましたが、今でははるかにアクセスしやすくなり、特にゲーム業界がグラフィックスに影響を与えています。 Atari 2600は、白い長方形よりも洗練されたものを描くことを可能にしました。 また、Commodore 64には実際のピクセルを備えたビデオメモリがあり、「 31415番目のクロックサイクルまでに色を切り替える 」よりも作業が便利でした 。
トリッキーなアルゴリズムを使用して手動でピクセルを設定することにより、画面にモナリザを描くことは困難です。 はい、ビデオメモリからデータを取り出してファイルに保存し、それをファイルから挿入するため、必要ありません。 このようなBASICのメモリダンプは
BSAVE
チームによって作成され、フォーマット自体はBSAVE'dにちなんで命名されました 。 画像の編集ははるかに便利になり、シンプルなグラフィックエディターは、ほとんど互いに見分けがつかず、見事な色に彩られました。
しかし、一部の編集者は幼少期を脱し、非常に便利で便利なツールになりました。 そのため、1984年にPCPaintが登場し、マウスで描画できるようになりました。 明らかなユーザーフレンドリーな機能に加えて、PCPaintは別の利点を提供しました。 実際には、BSAVEダンプには画像サイズ、色深度、およびパレットに関するデータが含まれておらず、ビデオモードがほとんどない場合(およびカラー画像が白黒で表示された場合)、別のPALファイルをパレットに使用する必要がありました。 PCPaintエディターのPIC形式には、パレットとBSAVEダンプの両方が含まれていました。 これはプログラマにとって小さな一歩であり、人類全体にとって大きな飛躍です。 「ただし、MKV形式を考えてみましょう。MKV形式では、字幕を内部に保存できるため、適切なフォルダーに入れる必要はありません」。
しかし、別の問題は未解決のままでした。PCには
BSAVE
あり、Appleには
BSAVE
があり
BSAVE
が、それらは異なる形式のファイルを生成します。 これは驚くことではありません、メモリ内の画像の内部表現は異なっていました。 トランスコーダーはありましたが、長い間、このベンダー依存の混乱は続かないことが明らかになりました。 1984年、TruevisionはTGAとして知られるTARGA形式を導入しました。 そして次の1985年、PCペイントブラシは光を見ました。 PC Paintbrushの売り上げは悪化していましたが、ポータブルでかなりシンプルなPCXフォーマットはPICよりも長持ちしました。
TGAとPCXの両方で、画像サイズとパレットデータは、ハードウェアに強くバインドされることなく、明示的に保存されました。 これが可能になったのは、ピクセルデータが特定のプラットフォームに依存せず、左から右、上から下への単純なスキャンラインであったためです。
しかし、これら2つの形式には別の重要な機能があり、それらのラスターデータは圧縮形式で保存されていました。 適用されたRLEアルゴリズムは効率の最高点ではありませんでしたが、すでに非常に優れていました。
RLE
RLE(ランレングスエンコーディング)はかなり単純なアルゴリズムですが、データ圧縮の仕組みをよく示しています。 ロスレスデータ圧縮とは、それらの冗長性を取り除くことです。 これを行うには、データセットを取得し、その中の繰り返し値のチェーンを見つけて、それらをよりコンパクトなものに置き換えます。
通常、RLEは「シリーズの長さのコーディング」として翻訳され、そのような重複する値は「シリーズ」と呼ばれます。 翻訳は「実行」することを好みますが、私は何もできません。すでに確立された用語です。
ほとんどの場合、すでに使用しています。 「
AAAAAAAAAAAABBBAAAAAAAAA
」という行を見てみましょう。 電話で口述する必要がある場合、「12個の大文字A、3個の大文字B、9個の大文字A」のように聞こえます。 これを書き留めると、「
12
A
3
B
9
A
」が得られ、矛盾がないようになり、「
9
A
3
A
3
B
9
A
」となります。 はるかにコンパクト。
次に、別の行「
0KXQsNCx0YDQsNGF0LDQsdGA
」を
0KXQsNCx0YDQsNGF0LDQsdGA
て、このように圧縮してみます。 「
1
0
1
K
1
X
...」と表示されます。 文字列は元の2倍の長さですが、これは決して圧縮ではありません。 アルゴリズムを変更し、数字に文字を追加します。文字Aは、次の文字が「そのまま」書き込まれることを意味します。 Bの場合は2。 Cの場合は3、というようになります。 「
X
0KXQsNCx0YDQsNGF0LDQsdGA
」が判明しました。 したがって、最良の場合、350%の圧縮率が得られ、最悪の場合、4%しか失われません。
もちろん、実際の条件では、バイトは通常ラテンアルファベットの文字ではなくエンコードされ、シーケンスの長さは0から255の値でエンコードされます。さらに、通常、シリーズの長さの無意味な値は無視されます:この例では、1とAは同じことを行い、一般に0意味がありません。 しかし、これらは詳細であり、本質は同じままです。
エントロピー
理論をどのように避けたいとしても、このことは重要すぎて無視できません。 すべてのシーケンスを圧縮できるわけではないことに気づきましたか? 文字列
AAAAAAAAAAAABBBAAAAAAAAA
と
0KXQsNCx0YDQsNGF0LDQsdGA
同じ長さの24文字ですが、2番目の文字ではこれらの文字はより
0KXQsNCx0YDQsNGF0LDQsdGA
圧縮がより困難です。
このようなランダム性の尺度は情報エントロピーであり、メッセージ内の情報量として定義されます。
 |  |  |
|---|---|---|
| 少しエントロピー | もっと | さらに |
情報エントロピーの単なる存在は、データが特定の長さまでしか圧縮できないことを示唆しています。 さらに、魔法はプロセスに関与していません。 クロード・シャノンによると、映画「クリック」はキロバイトに圧縮されていません。
これを説明するために、一見ITに関連していないという事実に目を向けます。
 | 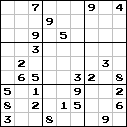 | 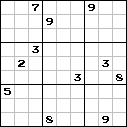 |
|---|
左側の数独には81桁が含まれており、すでに決定されています。 中央の情報には26桁の少ない情報が含まれていますが、それを解決すると、元の81をすべて復元できます。
しかし、右側の数独ではすべてが非常に悪いです-あまりにも多くのデータが削除されており、もはや解決されていません。つまり、元のデータセットを取得できません。
PCX
しかし、PCXに戻って、10年間誰もやったことのないことをして、PCXファイルを作成し、手動でしましょう。 ツールを知る必要があるので、仕様を見て、このフォーマットが何であるかを調べましょう。 主なポイントは次のとおりです。
- 画像は、最大65536×65536の寸法を持つことができます。 最大256色のパレット、またはパレットなしの24ビットカラー。 ヘッダーのサイズは常に128バイトで、画像サイズ、色数、最大16色のパレットが含まれ、チャンネルごとに1バイトです。 当然、256色のパレットはそのようなヘッダーに収まりません。収まる場合は、ファイルの末尾に追加され、サイズは769バイト(1バイトの署名と256×3バイトのデータ)になります。 CGAパレット用のフィールドもありますが、サポートされなくなりました。
- 生データストリームは、スキャンライン(1文字の水平線)で構成されます。 各スキャンライン内には、R、G、B、Aの4つのビットプレーンがあります。すべてのプレーンは
RRRRGGGGBBBBAAAA
順に書き込まれます。 プレーンは厳密に偶数のバイトで構成され、必要に応じて、この条件が満たされるようにプレースホルダーが生データに追加されます。 このようなプレースホルダーデータは、デコード中に無視されます。 - 生のラスターデータは、RLEを使用して行ごとに圧縮されます。 「ラインごと」とは、RLEシリーズがビットプレーンを超えることができないことを意味します。
- RLEでは、192〜255のバイト値は、それぞれ0〜63回の文字繰り返し回数をエンコードします。 残りの値はリテラルです。繰り返しの回数が予想される場所で見つからない場合は、1回繰り返されると考えられます。
実際のPCX
それでは、このテクニカルデータチャットの例を見てみましょう。 たとえば、次の写真(17×8、便宜上8倍に拡大)をご覧ください。

パレットを決定します。 画像には3つの異なる色があるため、4色、16色、および256色のパレットとTruecolorがあります。 4色パレットでは、1バイトに4つの値があります(8バイトビットをパレットの2ビットの数値に分割します)。 16色-バイトあたり2ピクセル。 256色-バイトあたりのピクセル(および769バイトの追加パレット)。 トゥルーカラーのピクセルあたりのバイト数は3バイトです。 選択は明らかで、4色です。
たとえば、次のように色を配置します。
 |  |  |  |
|---|
次に、最上位ビットから始めて、最初の行のビット値を書き出します。 クォータナリシステム、区切り文字-バイト境界のリスト。
0000 0000 0000 0000 0
4.25バイトになります。 小数バイトのRLEは機能せず、5つまで終了します。
0000 0000 0000 0000 0
000
ドキュメントには、スキャンラインには偶数バイトが必要であると書かれています。 することは何もありません、私たちはまだそれを終えています。
0000 0000 0000 0000 0
000 0000
残りの行についても同じことを行います:
0000 0000 0000 0000 0
000 0000
0111 1111 1111 1111 0
000 0000
0121 2121 2121 2121 0
000 0000
0212 1212 1212 1212 0
000 0000
0222 2222 2222 2222 0
000 0000
0202 0202 0202 0202 0
000 0000
0020 2020 2020 2020 0
000 0000
0000 0000 0000 0000 0
000 0000
次に、どの値を圧縮できるかを見てみましょう。 一連の2バイトのエンコードには2バイトかかるため、2バイトより長い同一バイトのシーケンスにのみ注意します。その意味はありません。
0000 0000 0000 0000 0
000 0000
0111
1111 1111 1111
0
000 0000
0121
2121 2121 2121
0
000 0000
0212
1212 1212 1212
0
000 0000
0222
2222 2222 2222
0
000 0000
0202 0202 0202 0202
0
000 0000
0020
2020 2020 2020
0
000 0000
0000 0000 0000 0000 0
000 0000
最後から2番目の行の最後のゼロバイトは最後の行にしがみつくように求められますが、これは機能しませんが、スキャンラインの境界はエッジを越えないことに注意してください。
今、騎士の動き。 仕様では、偶数バイトにスキャンラインするために正確に行う必要があることはどこにも記載されていません。 とにかく、デコーダーはこれらの値を捨てます。 したがって、これを行うことで2バイトも節約できます。
0000 0000 0000 0000 0
000 0000
0111
1111 1111 1111
0
000 0000
0121
2121 2121 2121
0
000 0000
0212
1212 1212 1212
0
000 0000
0222
2222 2222 2222
0
000 0000
0202 0202 0202 0202 0
202 0202
0020
2020 2020 2020
0
000 0000
0000 0000 0000 0000 0
000 0000
結果のRLEをエンコードします。 おそらく、より馴染みのある16進数形式に切り替える方が便利でしょう。
00 00 00 00 00 00
15
55 55 55
00 00
19
99 99 99
00 00
26
66 66 66
00 00
2A
AA AA AA
00 00
22 22 22 22 22 22
08
88 88 88
00 00
00 00 00 00 00 00
最初の行をエンコードします。 6バイト
0x00
値192 + 6 = 198または
C6
6回繰り返します。 6回繰り返す予定の値を書き込んだ後、
0xC6
0x00
。 最初のスキャンラインの準備ができました。
2番目のスキャンラインは
0x15
から始まります。 この値は、
0xC1
0x15
( "once
0x15
")としてエンコードできます。 しかし、PCXのRLE機能のために、単純に
0x15
と記述することができ、「1回」が暗示されます。
次に、3つの同一のバイトが
0xC3
0x55
なり
0xC3
。
また、行の最後には2つの
0xC2
、額、
0x00 0x00
、またはより
0xC2
0x00
2つの方法で表すことができ
0x00
。 そして、2バイトです。 女の子がトリッキーなテクニックに感銘を受けることはまずありませんが、必要以上に複雑なことをする理由は他にないので、
0x00 0x00
取得し
0x00 0x00
。
ところで、キャッチーなものについて。 エンコードされたデータに、
0xC0
0x73
0xC0
0x65
0xC0
0x63
0xC0
0x72
0xC0
0x65
0xC0
0x74
ようなもの、つまり一連の長さ0を挿入します。これらは画像自体には影響しません。 ウィキペディアはステガノグラフィーに使用できると書いていますが、私にとっては、そのようなステッチは白い糸で縫われており、ファイルサイズを大きくする以外には得意ではありません。
同様の方法で続けると、次のようになります。
C6
00
15
C3
55 00 00
19
C3
99 00 00
26
C3
66 00 00
2A
C3
AA 00 00
C6
22
08
C3
88 00 00
C6
00
128バイトのヘッダーを先頭に追加するだけで、完了です! 結果を賞賛するために、 このスクリプトを実行できます 。 node.jsにありますが、お気に入りの言語に書き換えることは難しくないでしょう。
PCXプラクティス2:パレット
次に、別の画像を取得して、PCXに再度転送し、可能な限り圧縮してみます。 今回は、画像が7×5より小さいです。
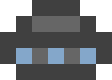
これはUFOです。 私はそれがあまり似ていないことを知っています。
まず最初に、色深度を選択しましょう:2ビット。 これらは、必要なだけの4色です。 たとえば、次のようにパレットを定義します。
 |  |  |  |
|---|
次に、ラスタデータキュー。 2回目は、面倒な数字の書き込みプロセスを行わず、生データとそのデータを16進数ですぐに記録します。
| 生データ | 圧縮データ |
0F C0
3A B0
FF FF
D9 9C
3F F0
| 0F
C1
C0
3A B0
C2
FF
C1
D9 9C
3F
C1
F0
|
おっと! 圧縮されたデータのサイズは元のサイズよりも大きいことが判明しました。 これは、
0xC0
値が繰り返し回数のマーカーであり、そのように書き込むことができないためです。
0xC0
代わりに、
0xC0
代わりに
C1
C0
0xC1
0xF0
ありました。
0xFF 0xFF
の場合、幸運でした-貴重なバイトを失うことはありませんでした。 しかし、一般的には、つまらない絵が出てきます。今ではRLEが助けになるのではなく、単に気になります。
絶望の方向で、これで何ができるか見てみましょう。 マーカーは、2つの最上位ビットが1である11 XXXXXXのバイトです。 データは、最上位ビットから順番に書き込まれます。 ただし、2ビットの色深度では、4×nオフセットのピクセルは、バイトがマーカーであるかどうかに影響します。 つまり、番号3のカラーピクセル(この場合、濃い灰色)。
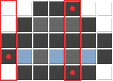
ここに、ファイルサイズの急増の原因があります。 3行目では、濃い灰色のピクセルも選択された列に入りますが、天気は変わりません。エンコードされると、行自体が2つの同一のバイトを提供します。
パレット内の色の順序は自分で決定するため、4×nのオフセットで最も少ない色として番号3を選択します。 青は最高の候補者であり、彼はそのような場所でまったく発見されたことがない。 パレットを再定義して、2回目の試行を行います。
|  |  |  |
|---|
| 生データ | 圧縮データ |
0A 80
25 60
AA AA
B7 78
2A A0
| 0A 80
25 60
AA AA
B7 78
2A A0
|
圧縮されたデータは元のデータと同一であることが判明しました。 RLEこの画像は強すぎましたが、少なくともオーバーヘッドはありませんでした。 いずれにせよ、ラスターデータの準備ができており、これが圧縮可能な最大値です。
まあデモ: UFOジェネレーター
合計
繰り返しますが、PCXの重量を減らすための簡単なテクニック:
- 可能な最小の色深度(パレットサイズ)の選択。
- ガベージデータの最適化。
- 意味のないデータの削除(系列の長さ0);
- 最適化パレット。
続く
まあ、それがおそらくすべてです。 TGAについてはお話ししませんが、PCXとは異なりますが、違いよりもはるかに多くの類似点があります。 しかし、当時、他に直接注目すべきグラフィック形式はありませんでした。
もちろん、CompuServeのGIF形式を除きます。 次回はそれについて掘り下げます。