PHPレベルの配列とは何ですか?
PHPレベルでは、配列はマップと交差する順序付きリストです。 大雑把に言えば、PHPはこれら2つの概念を組み合わせています。その結果、一方では非常に柔軟なデータ構造になりますが、Anthony Ferraraが述べているように、おそらく最も最適ではなく、より正確になります:
PHP配列は、万能型の優れたデータ構造です。 しかし、すべての万能な<anything>のように、大規模な取引は通常、何もできないことを意味します。
手紙へのリンク

(写真は、バケット、V。Vasnetsovを含むHashTableです)
そして、ここから始めます-挿入された各値によって消費されるメモリと時間を測定してみましょう。 これを行うには、次のスクリプトを使用します。
// time.php $ar = array(); $t = 0; for ($i = 0; $i < 9000; ++$i) { $t = microtime(1); $ar[] = 1; echo $i . ":" . (int)((microtime(1) - $t) * 100000000) . "\n"; } // memory.php $ar = array(); $m = 0; for ($i = 0; $i < 9000; ++$i) { $m = memory_get_usage(); $ar[] = 1; echo $i . ":" . (memory_get_usage() - $m) . "\n"; }
これらのスクリプト
php time.php > time
および
php memory.php > memory
、それらにグラフを描画します。これは、大量のデータがあり、長い間数値を見るためです(時間データは何度も収集され、グラフ上の不要なジャンプを避けるために調整されます)。
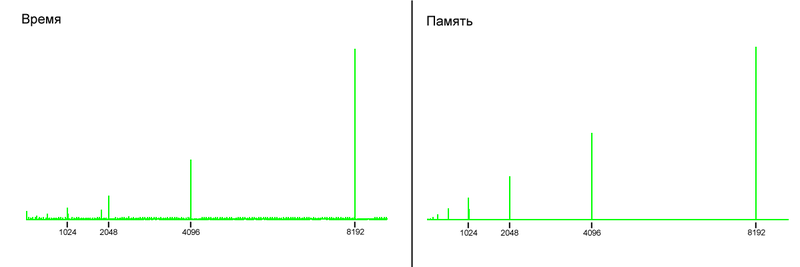
(X軸上-配列内のel-tovの数)
ご覧のとおり、両方のグラフで、消費メモリと使用時間の両方にジャンプがあり、これらのジャンプは同時に発生します。
実際には、Cレベル(および実際にはシステムレベル)には、サイズが固定されていない配列はありません。 Cで配列を作成するたびに、サイズを指定して、システムに割り当てる必要があるメモリ量をシステムが認識できるようにする必要があります。
次に、これはPHPでどのように実装され、チャート上のそれらのジャンプをコンパイルする方法ですか?
空の配列を作成すると、PHPは特定のサイズで作成します。 配列を埋めて、ある時点でこのサイズに到達してそれを超えると、サイズの2倍の新しい配列が作成され、すべての要素がその配列にコピーされ、古い配列が破棄されます。 通常、これは標準的なアプローチです。
そして、これはどのように実装されていますか?
実際、PHPで配列を実装するには、完全に標準的なハッシュテーブルデータ構造を使用します。これについては、実装の詳細について説明します。
ハッシュテーブルには、最初と最後の値へのポインター(配列の並べ替えに必要)、現在の値へのポインター(配列の繰り返しに使用、これは
current()
が返すもの)、配列に表される要素の数、配列Bucketへのポインター(後で詳しく説明します)、および他の何か。
なぜ
私たちに
バケットが必要です
そしてどこ
私たちに
それらを置きます
ハッシュテーブルには2つの主要なエンティティがあり、1つ目はハッシュテーブル自体で、2つ目はバケット(以降、退屈しないようにバケット)です。
バケット自体に値が格納されます。つまり、各値には独自のバケットがあります。 ただし、これに加えて、元のキーはバケット、次のバケットと前のバケットへのポインター(PHPではキーを任意の順序で配置できるため、配列を配置するために必要です)、および他の何かに格納されます。
したがって、配列に新しい要素を追加するときに、そのようなキーが存在しない場合、その下に新しいバケットが作成され、ハッシュテーブルに追加されます。
しかし、最も興味深いのは、これらのバケットがハッシュテーブルに格納される方法です。
上記のように、HTにはバケットへのポインターの特定の配列がありますが、バケットは特定のインデックスでこの配列で使用でき、このインデックスはバケットのキーを知ることで計算できます。 少し複雑に聞こえますが、実際には、すべてが思ったよりもはるかに単純です。 HTからキーによってアイテムが取得される方法を解析してみましょう。
- キーが文字列の場合、文字列は整数aにハッシュされます(DJBX33Aハッシュアルゴリズムが使用されます)。
- ハッシュの元の値は、マジック5381として取得されます
- 各キーシンボルについて、ハッシュに33を掛け、ASCIIの文字番号を追加します
- マスク(ビット単位のand)は常に結果の数値キーに適用され、常に配列のサイズ(バケットを含む)から1を引いた値に等しくなります。
- その結果、このキーは、配列からバケットへの目的のポインタを取得するためのインデックスとして使用できます
マスクについて:ポインターの配列に4つの要素が含まれているとします。したがって、マスクは3、つまりバイナリシステムでは11です。
これで、123(1111011)のような数値をキーとして取得した場合、マスキング後に3(3&123)が取得され、この数値は既にインデックスとして使用できます。
その後、マスク3を使用して、キー54と90の要素をハッシュテーブルに追加しようとします。これらのキーは両方とも、マスキング後は2に等しくなります。
衝突をどうするか?
バケットには、袖にさらに2、3枚のカードがあります。 各バケットには、インデックス(キーからのハッシュ)が等しい前後のバケットへのポインターもあります。
したがって、すべてのバケット間で実行されるメインの二重リンクリストに加えて、インデックスが等しいバケット間の小さな二重リンクリストもあります。 つまり、およそ次の図がわかります。

キー54と90、マスク3を使用してケースに戻りましょう。54を追加すると、HT構造は次のようになります。
{ nTableSize: 4, // nTableMask: 3, // nNumOfElements: 1, // HT nNextFreeElement: 55, // , ( ) ..., arBuckets: [ NULL, NULL, 0xff0, // , Bucket, NULL ] } 0xff0: { h: 54, // nKeyLength: 0, // , pData: 0xff1, // , zval ... }
90のキーを持つ要素を追加すると、すべてが次のようになります。
{ nTableSize: 4, nTableMask: 3, nNumOfElements: 2, nNextFreeElement: 91, ..., arBuckets: [ NULL, NULL, 0xff0, // Bucket NULL ] } 0xff0: { h: 54, pListNext: 0xff2, // Bucket ( ) pNext: 0xff2, // Bucket ... } 0xff2: { h: 90, pListLast: 0xff0, // pLast: 0xff0, // ... }
ここで、nTableSizeオーバーフローの前にいくつかの要素を追加しましょう(nNumOfElements> nTableSizeの場合にのみオーバーフローが発生することを思い出します)。
キー0、1、3の要素を追加します(存在しない要素、およびマスクを適用した後は同じままになります)。
{ nTableSize: 8, // ( ) nTableMask: 7, nNumOfElements: 5, nNextFreeElement: 91, // ..., arBuckets: [ // , 0xff3, // key = 0 0xff4, // key = 1 0xff2, // key = 90 - 90 ( 90 & 7 = 2), 6- 0xff5, // key = 3 NULL, NULL, 0xff0, // key = 54 NULL ] } 0xff0: { h: 54, pListNext: 0xff2, // , pNext: NULL, // ... } 0xff2: { h: 90, pListNext: 0xff3, pListLast: 0xff0, pLast: NULL, ... } 0xff3: { h: 0, pListNext: 0xff4, pListLast: 0xff2, ... } 0xff4: { h: 1, pListNext: 0xff5, pListLast: 0xff3, ... } 0xff5: { h: 3, pListNext: NULL, // pListLast: 0xff4, ... }
配列がオーバーフローした後に起こることは、rehashと呼ばれます。 基本的に、既存のすべてのバケットを(pListNextを介して)繰り返し、隣接を割り当て(衝突)、arBucketsにそれらへの参照を追加します。
しかし、キーによって要素が受信されると、実際にはどうなりますか? 前のアルゴリズムに何か他のものが追加されます。
- キーが文字列の場合、文字列は整数aにハッシュされます(DJBX33Aハッシュアルゴリズムが使用されます)。
- ハッシュの元の値は、マジック5381として取得されます
- 各キーシンボルについて、ハッシュに33を掛け、ASCIIの文字番号を追加します
- マスク(ビット単位のand)は常に結果の数値キーに適用され、常に配列のサイズ(バケットを含む)から1を引いた値に等しくなります。
- インデックスのバケットを取り出します
- このバケットのキーが目的のものと等しい場合、検索は完了します。それ以外の場合:
- ループでは、pNextからバケットを取得し(存在する場合)、キーが等しいかどうかを確認します
そのため、pNextのバケットがなくなる(通知がスローされる)まで、または一致が見つかるまで。
PHPでは、ほとんどすべてがこのHashTable構造だけで構築されていることに注意する価値があります:任意のスコープにあるすべての変数は実際にHTにあり、すべてのクラスメソッド、すべてのクラスフィールド、クラス定義自体もHTにあり、実際には非常に柔軟な構造です。 とりわけ、HTはフェッチ/挿入/削除とほぼ同じ速度を提供し、3つすべての複雑さはO(1)ですが 、衝突の場合の小さなオーバーヘッドの警告があります。
ところで、 ここでは、PHP自体にハッシュテーブルを実装しました。 まあ、つまり、PHPでPHP配列を実装=)