目的:R言語で最愛のHabraHabrからデータを収集し、実際には、Rが作成されたもの、つまり統計分析を実施すること。
したがって、このトピックを読んだ後、次のことがわかります。
- Rを使用してWebリソースからデータを取得する方法
- 後の分析のためにデータを変換する方法
- Rをよりよく知りたいと思うすべての人に読むためにどのリソースが強く推奨されますか
読者は、言語の基本的な構成に慣れるのに十分なほど独立していることが期待されます。 このためには、記事の最後にあるリンクが最適です。
準備する
次のリソースが必要です。
インストール後、次のように表示されます。
[パッケージ]タブの右下のパネルに、インストールされているパッケージのリストがあります。 さらに以下をインストールする必要があります。
- Rcurl-ネットワークでの作業用。 CURLで作業したすべての人は、開かれたすべての機会をすぐに理解します。
- XMLは、XMLドキュメントのDOMツリーを操作するためのパッケージです。 xpathで要素を見つける機能が必要です
[パッケージのインストール]をクリックし、必要なパッケージを選択し、チェックマークを付けて選択して現在の環境を起動します。
データを取得します
インターネットから受け取ったドキュメントのDOMオブジェクトを取得するには、次の行に従ってください。
url<-"http://habrahabr.ru/feed/posts/habred/page10/" cookie<-" " html<-getURL(url, cookie=cookie) doc<-htmlParse(html)
送信されるCookieに注意してください。 実験を繰り返したい場合は、Cookieを置き換える必要があります。Cookieは、サイトでの承認後にブラウザが受け取ります。 次に、興味のあるデータを取得する必要があります。
- 投稿が公開されたとき
- ビュー数
- お気に入りに追加された人数
- +1および-1のクリック数(合計)
- +1クリック数
- どのくらい-1
- 現在の定格
- コメント数
あまり詳しく説明することなく、すぐにコードを提供します。
published<-xpathSApply(doc, "//div[@class='published']", xmlValue) pageviews<-xpathSApply(doc, "//div[@class='pageviews']", xmlValue) favs<-xpathSApply(doc, "//div[@class='favs_count']", xmlValue) scoredetailes<-xpathSApply(doc, "//span[@class='score']", xmlGetAttr, "title") scores<-xpathSApply(doc, "//span[@class='score']", xmlValue) comments<-xpathSApply(doc, "//span[@class='all']", xmlValue) hrefs<-xpathSApply(doc, "//a[@class='post_title']", xmlGetAttr, "href")
ここでは、xpathを使用して要素と属性の検索を使用しました。
さらに、受信したデータからdata.frameを作成することを強くお勧めします-これはデータベーステーブルに類似しています。 さまざまな難易度のリクエストを作成することができます。 時々、これでRまたはR
posts<-data.frame(hrefs, published, scoredetailes, scores, pageviews, favs, comments)
data.frameを生成した後、受信したデータを修正する必要があります:行を数値に変換する、通常の形式で実際の日付を取得するなど このようにします:
posts$comments<-as.numeric(as.character(posts$comments)) posts$scores<-as.numeric(as.character(posts$scores)) posts$favs<-as.numeric(as.character(posts$favs)) posts$pageviews<-as.numeric(as.character(posts$pageviews)) posts$published<-sub(" ","/12/2012 ",as.character(posts$published)) posts$published<-sub(" ","/11/2012 ",posts$published) posts$published<-sub(" ","/10/2012 ",posts$published) posts$published<-sub(" ","/09/2012 ",posts$published) posts$published<-sub("^ ","",posts$published) posts$publishedDate<-as.Date(posts$published, format="%d/%m/%Y %H:%M")
すでに受信したものから計算される追加のフィールドを追加することも役立ちます。
scoressplitted<-sapply(strsplit(as.character(posts$scoredetailes), "\\D+", perl=TRUE),unlist) if(class(scoressplitted)=="matrix" && dim(scoressplitted)[1]==4) { scoressplitted<-t(scoressplitted[2:4,]) posts$actions<-as.numeric(as.character(scoressplitted[,1])) posts$plusactions<-as.numeric(as.character(scoressplitted[,2])) posts$minusactions<-as.numeric(as.character(scoressplitted[,3])) } posts$weekDay<-format(posts$publishedDate, "%A")
ここでは、「合計35:↑29および↓6」という形式の既知のメッセージを、実行されたアクションの数、プラスの数、マイナスの数に関するデータの配列に変換しました。
これについては、すべてのデータが受信され、分析可能な形式に変換されたと言えます。 上記のコードは、すぐに使用できる機能として設計しました。 記事の最後に、ソースへのリンクがあります。
しかし、熱心な読者は、このようにして、シリーズ全体を取得するために、1ページのみのデータを取得していることにすでに気付いています。 ページのリスト全体のデータを取得するために、次の関数が作成されました。
getPostsForPages<-function(pages, cookie, sleep=0) { urls<-paste("http://habrahabr.ru/feed/posts/habred/page", pages, "/", sep="") ret<-data.frame() for(url in urls) { ret<-rbind(ret, getPosts(url, cookie)) Sys.sleep(sleep) } return(ret) }
ここでは、誤ってHabraエフェクトをHabra自体に配置しないように、システム関数Sys.sleepを使用します。
この関数を次のように使用することをお勧めします。
posts<-getPostsForPages(10:100, cookie,5)
したがって、5秒の一時停止で10〜100のすべてのページをダウンロードします。 評価はまだ表示されていないため、10ページまでは興味深いものではありません。 数分待った後、すべてのデータはposts変数にあります。 Habrを邪魔しないように、すぐに保存することをお勧めします! これは次の方法で行われます。
write.csv(posts, file="posts.csv")
そして次のように読んでください:
posts<-read.csv("posts.csv")
やった! Habrから統計を取得し、次の分析のためにローカルに保存する方法を学びました!
データ分析
このセクションは私が言わないままにします。 読者が自分でデータを試して、彼の広範囲に及ぶ結論を得ることをお勧めします。 たとえば、曜日に応じてプラスとマイナスの気分の依存関係を分析してみてください。 私が行った興味深い結論は2つだけです。
Habrユーザーはマイナスよりもプラスになりやすい。
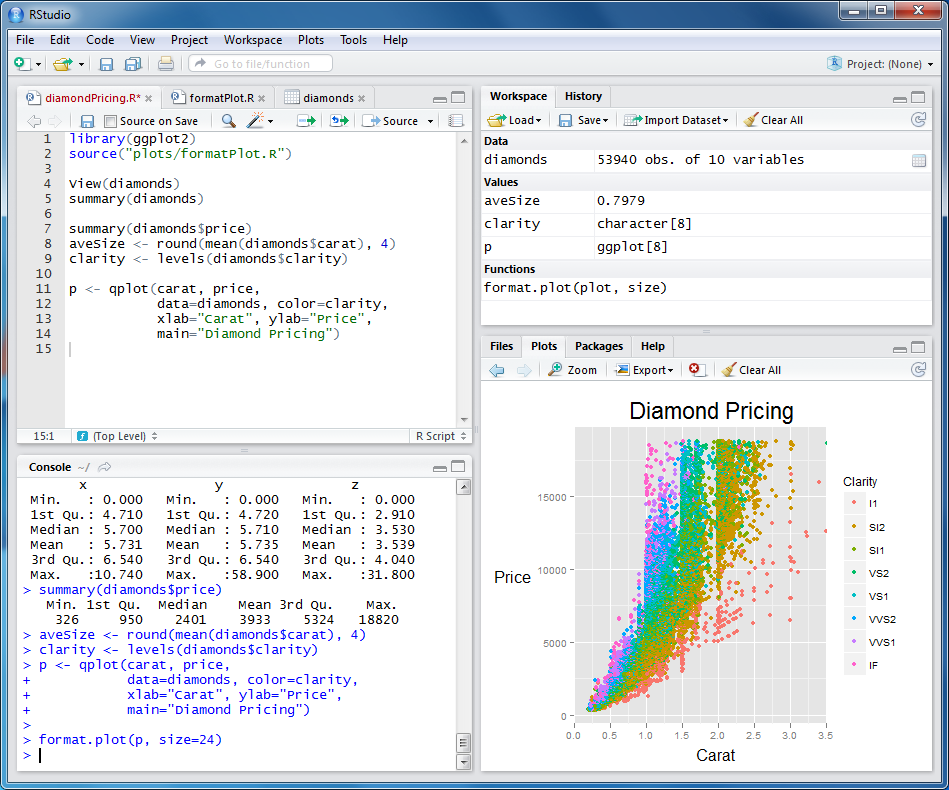
これは次のグラフで見ることができます。 マイナスの「クラウド」が、プラスの広がりよりも均一で幅が広いことに注目してください。 ビューの数から得られるプラスの相関は、マイナスの場合よりもはるかに強力です。 言い換えれば:考えずにプラス、マイナスの原因!
(グラフ上の碑文をおaびします:ロシア語で正しく表示する方法を見つけ出すまで)
実際、投稿にはいくつかのクラスがあります
この声明は言及された投稿で与えられたものとして使用されましたが、実際にはこれを確認したかったのです。 これを行うには、アクションの合計数に対するプラスの平均シェアを計算するだけで十分です。マイナスについても同様で、2番目を1番目に分割します。 すべてが均一である場合、ヒストグラムで多くの局所ピークを観察するべきではありませんが、それらはそこにあります。
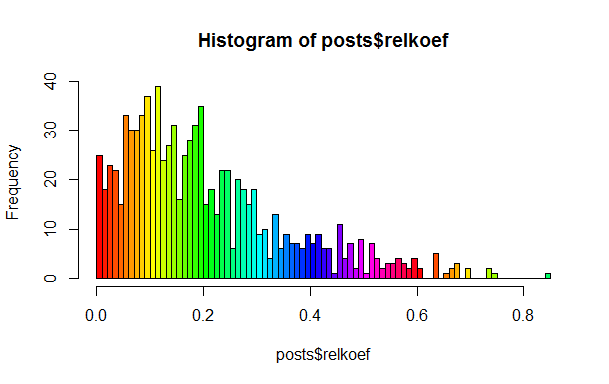
ご覧のとおり、0.1、0.2、および0.25付近に顕著なピークがあります。 読者自身がこれらのクラスを見つけて「名前を付ける」ことをお勧めします。
Rには、データのクラスタリング、近似、仮説のテストなどのアルゴリズムが豊富に含まれていることに注意してください。
有用なリソース
本当にRの世界に没頭したいなら、以下のリンクをお勧めします。 Rのトピックに関する興味深いブログやサイトをコメントで共有してください。ロシア語でRについて書いている人はいますか?
R、haskell、lisp、javascript、pythonなどの言語は、すべての自尊心のあるプログラマーに知られるべきだと思います。仕事のためでなければ、少なくとも視野を広げてください!
PS 約束されたソース