 HOLO-ギリシャ語の「λ」からの接頭辞、「すべて」。
HOLO-ギリシャ語の「λ」からの接頭辞、「すべて」。
はじめに
興奮するわけではありませんが、「類似」の音楽を見つけることを目的として、音楽ライブラリを1つの全体に結合できる私の開発を紹介できることを嬉しく思います。
数年前、MATLABの独立した研究のピーク時に、特定の音楽サンプルから「同じ精神で」他の作品を見つけることができるプログラムを作成したかったのです。 さまざまな理由により、実装をさらに延期せざるを得ませんでしたが、ある時点で問題は前進しました。 その結果、開発の基礎がわずかに変更され、プログラムの最初のバージョンが作成されました。
問題の声明
したがって、問題のステートメントは次のとおりです。
- ハードドライブには比較的大きな(10,000ファイルを超える)音楽コレクションがあり、これを使用して完全にカタログ化することが難しくなっているため、多くの曲が何ヶ月も何年もプレイリストに入れられません。
- ファイルに含まれる音波の形式以外の情報を使用せずに、構成の数値特性を評価する必要があります(ファイル名、アルバム、id3タグなどは考慮されません)。
- アナライザーに1つ以上の組成物をサンプルとして供給します。
- サンプルのリストと一致しないコンポジションのリストを表示し、サンプルからの「距離」の昇順でソートします。
C#は開発プラットフォームになりました。個人的には最も簡単な言語であり、十分に高速で、優れた開発環境を備えています。 Codeplexなどのサイトをすばやく検索すると、いくつかの自転車の発明を避けることができました。特に、次のライブラリが使用されています。
- NAudio-オーディオファイルの読み取り用。
- Meta.Numerics -FFT変換用。
- データを保存および処理するためのSQLite + SQLite netFXラッパー 。
- また、調査段階では、.NET用のバージョンのALGLIBライブラリが接続されます。
アーキテクチャ的には、プログラムは2つのサブシステムで構成されています-音楽コレクションのデータベースの形成とデータベース検索システム。
理論
データベースの形成は、次のように実装されます。
分析されたファイルは、サンプルからのベクトルとして表され、そこからL個のサンプルのN個のスナップショットが抽出され、それぞれがFFT変換を使用して周波数応答 (fft-snap)で与えられます。 実際、この変換は、時系列を、時系列を構成するさまざまな周波数の振幅のセットに変換します。 次に、fft-snapが比例的にK回圧縮され(ダウンスケール比)、後で分析される周波数の数が削減されます。
さらに、結果の画像セットの各周波数は個別に考慮されます-平均値(平均)、中央値(中央値)、標準偏差(stdev)、ベベル( 歪度 )および急峻度( 尖度 )などの統計的特性が計算されます。 その結果、各コンポジションに対してL / 2K周波数のセットがあり(FFTは中央に対してほぼ対称的であることが判明)、それぞれに対して5つの統計が計算されます。 データベースには、ファイル名、ディスク上のファイルへのパス、および5L / 2Kの実数が含まれており、それぞれが表す統計の名前でマークされています。
たとえば、64,000サンプルの長さで40枚の写真を1,000回圧縮してファイルを分析します。 その結果、各コンポジションのベクトルは5 *(64000/1000)/ 2 = 160の数値になります。
この時点で、分析用データベースの形成の主要段階は完了したと見なされます。 サポート手順は次のとおりです。
- 統計テーブルにインデックスを作成します。
- 各統計の全体的な値の計算(最大、最小、平均、およびコリドー-最大と最小の差)。
これで分析を開始できます。 160次元空間内の2つの点の近接度を評価する最も簡単な方法は、それらの間のユークリッド距離を計算することです(対応する統計量のペアごとの差の平方の合計、平方根は抽出されません-計算は長くなりますが、ソート結果には影響しません)。 考えてみてください-数えますが、コンポジションの周波数応答の異なる周波数には異なるばらつきがあり、「額」の距離を計算すると歪んだ距離が得られ、低周波数に重点が置かれます。 望ましくない効果を補正するために、値間の差の2乗を特定の周波数の平均振幅の2乗で除算します。 したがって、距離を計算する頻度分布の特性の最初の異方性空間は、はるかに等方性、つまり均一になります。
理論的には、近接度によって構成を統合するクラスター分析を実行することは可能ですが、これまでは空間内のポイント間の距離の計算にも基づいているため、この方法の使用を放棄することが決定されましたが、アルゴリズムはより複雑で、距離を増やして曲を並べ替えるのにあまり役立ちません。
練習する
おそらくこれまでに十分な理論があるので、音楽コレクションに基づいた実用的な結果についてお話します。 トラックの数は30,277で、ジャンルは非常に異なります-クラシック音楽、ロック、ハードロック、アンビエント、ドラムとベース、ハウス、テクノ、エスニック、ライトドゥームから最も核の速いものまで、あらゆる種類のメタル。
コレクション全体の分析には2日半かかり、後処理なしのデータベースは180メガバイト、インデックスとともに460かかります。
プログラムの検索インターフェイスは、SQLクエリの動的な形成で構成されます。SQLクエリは、各周波数の正規化された統計のユークリッド距離を計算するアルゴリズムを実装します。
1つの構成をサンプルとして指定することも、複数の構成を指定することもできます。 一般に、1つのコンポジションがさまざまな理由で発生する統計のスプリアス変動を持っているが、複数のサンプルが本質的に多次元空間で重心を形成するという事実により平準化されるため、複数のサンプルに近い曲を一度に検索する機能は検索の精度を大幅に向上させます。その寄生変動は大幅に減少します。 複数のサンプルを決定する際の主なことは、サンプル間で明確な共通性があることを確認することです(たとえば、1つのアルバムの曲や1つの狭いジャンルの曲など)。 サンプルが互いに非常に異なる場合、近い構成の発行は無関係です。
1つのサンプルでのクエリは、平均で約1分実行されますが、サンプル数を増やすと、それに比例して時間が長くなります。
SQLサンプルは次のとおりです。
select b.id, sum(((a.statvalue - b.statvalue)*(a.statvalue - b.statvalue))/(c1.value*c1.value)) as distance, 10000*max((a.statvalue - b.statvalue)*(a.statvalue - b.statvalue)/(c2.value*c2.value)) as maxdiff, 10000*avg((a.statvalue - b.statvalue)*(a.statvalue - b.statvalue)/(c2.value*c2.value)) as meandiff from stats a, stats b, feature c1, feature c2 where a.id in (631, 1919) and b.id not in (631, 1919) and a.statname = c1.statname and c1.feature = 'mean' and a.statname = c2.statname and c2.feature = 'max_min' and a.statname = b.statname and c1.statname = c2.statname and a.statvalue <= b.statvalue + 75*c2.value/100 and a.statvalue >= b.statvalue - 75*c2.value/100 and a.statname in ('b_median_FFT1_01', 'b_median_FFT1_02', 'b_median_FFT1_03', 'b_median_FFT1_04', 'b_median_FFT1_05', 'b_median_FFT1_06', 'b_median_FFT1_07', 'b_median_FFT1_08', 'b_median_FFT1_09', 'b_median_FFT1_10', 'b_median_FFT1_11', 'b_stdev_FFT1_01', 'b_stdev_FFT1_02', 'b_stdev_FFT1_03', 'b_stdev_FFT1_04', 'b_stdev_FFT1_05', 'b_stdev_FFT1_06', 'b_stdev_FFT1_07', 'b_stdev_FFT1_08', 'b_stdev_FFT1_09', 'b_stdev_FFT1_10', 'b_stdev_FFT1_11', 'b_skewn_FFT1_01', 'b_skewn_FFT1_02', 'b_skewn_FFT1_03', 'b_skewn_FFT1_04', 'b_skewn_FFT1_05', 'b_skewn_FFT1_06', 'b_skewn_FFT1_07', 'b_skewn_FFT1_08', 'b_skewn_FFT1_09', 'b_skewn_FFT1_10', 'b_skewn_FFT1_11', 'b_kurto_FFT1_01', 'b_kurto_FFT1_02', 'b_kurto_FFT1_03', 'b_kurto_FFT1_04', 'b_kurto_FFT1_05', 'b_kurto_FFT1_06', 'b_kurto_FFT1_07', 'b_kurto_FFT1_08', 'b_kurto_FFT1_09', 'b_kurto_FFT1_10', 'b_kurto_FFT1_11') group by b.id having maxdiff <= 100 and meandiff <= 64 order by distance limit 30;
例として、 My Dying Brideのアルバム「Songs of Darkness、Words of Light」から取得した3つの曲のサンプルからのクエリの結果を示します。
これらの曲は、死の危機にmetalしたメタルジャンルの良い例です。
30曲の出力サイズは次のとおりです。
さらに、さらに3つの無関係なトラックと、既にリストにあるものの1つの複製。 私の意見では、すでにかなり受け入れられています。 いずれにせよ、「MDBの精神で」何かを聞きたいのであれば、そのようなプレイリストを拒否しません。
- FUBAR-クロール関連性は、おそらく、ギターサウンドのテクスチャのみです。
- The Soundbyte-The Dark多くの電子機器ですが、雰囲気は偶然です。
- AHAB-Ahabs Oath To the Point!
- Gorement-Into Shadowsパターンよりも少し極端ですが、非常に近いです。
- 墓-マリーナ抽象的なスラッジダム、質感が似ています。
- 難解-ポイントへの忠誠 !
- Autechre-Eutow非常に予想外のオプションですが、聴けば、音の質感の類似点を感じることができます。
- Entombed-Retaliation要点ではなく、非常に近い。
- Quake Mission Pack 1-Scourge of Armagon-04-music-track-4.mp3馬鹿げたオプションですが、全体的に関連性は高かったです。
- Nile-Divine Intentポイントまでの曲の最初の部分は、サンプルよりもさらに強烈に聞こえます。
- mberの涙-天国の果てまで !
- 神経症-恵みの時代わずかに異なるジャンルですが、関連性は高いです。
- 若い未亡人-若者の内外で高い関連性。
- エンピリウム-オータムグレイビューズドゥームメタル。
- 暗い静けさ-亡命に渡された時間さらに極端ですが、関連性は良好です。
- 絶望の形-これらの絵画は静かです
- ロゼッタ-道徳の関連性の決定論 。
- Solstafir-光の幽霊は非常に高い関連性。
- レッドツェッペリン-10年が過ぎ去った予想外のオプションでしたが、全体的にも受け入れられました。
- 発疹チフス -***検閲済み***関連性が高く、トラックのタイトルがサイトのわいせつとして検閲されています。
- Voivod-受け入れられる神の太陽関連性。
- ゆりかごのゆりかご-見るガラスを通しての悪意予想外の、非常に良いオプション。
- 窒息-償還関連性は、極端なために損なわれます。
- Nihilist –Abnormally Deceasedギターの音の質感に合わせます。
- 奇妙な牧師-ナンナの要点への門 !
- Goresleeps-Avalon Dreams(The Voice from Legend)ポイントまで!
さらに、さらに3つの無関係なトラックと、既にリストにあるものの1つの複製。 私の意見では、すでにかなり受け入れられています。 いずれにせよ、「MDBの精神で」何かを聞きたいのであれば、そのようなプレイリストを拒否しません。
他の例を挙げることもできますが、一般に、これまでのプログラムの最も単純な識別ジャンルはアンビエントです(エイダンベイカー、井上哲、ラストモルドなど、何千もの)。
短所
もちろん、それらも存在します。これは主に、比較アルゴリズムが完全ではないためです。
- プログラムは、平均ボリュームを考慮しません。 したがって、ちなみに、80年代の歌はこの問題で出てくる可能性がありますが、サンプルは、ラウドネス戦争がすでになくなっていた2000年代のものです。
- 私のデータベースでは、限られたリストから意図的に無関係な組成物が定期的に表示されますが、結果の中にその存在がまだ説明できません。 そのような場合、例外のリストが作成されます。
- 私の意見では、メインファイル-プログラムは、いくつかがすでにサンプルとして取られている場合、同じアルバムからほとんど曲を生成しません。 まれに、1つまたは2つで、それ以上のことはありません。
- 同様の欠点は、たとえばZemfiraなどのすべての歌を引き出して、例として2つか3つの歌を尋ねることです。 もちろん、声は独特の特徴ですが、構成が異なると音が異なるバックグラウンドインストゥルメントは、好ましい検索の条件に違反します。 周波数ごとに分析の解像度を上げ、各曲のサンプル数を追加すると、何かを期待できますが、操作の速度が大幅に低下する可能性があります。
- N次の中心モーメントは一般に楽曲を特徴づけますが、そのうちの2つ(歪度と尖度)は音の可聴特性と関連付けるのが困難です。 これはそれほど悪くないかもしれませんが、もっと理解しやすい指標が欲しいです。
- 速度:平均して、サンプルのリストにある各トラックを待つ分までに、一般的には許容できますが、もっと速くしたいです。 昇順の並べ替えを伴うクエリの現在のアーキテクチャでは、インデックスが存在するにもかかわらず、SQLiteがすべてのコンポジションを完全に実行することを避けられないため、並べ替えを無効にすると作業が何倍も速くなります。 ところで、ソートせずに作業する場合、オプションを選択するための追加の方法が提供されます。
Githubにアップロードされたソース。 (どういうわけか、私の人生で初めて、リポジトリをプッシュすることができました。えええ。計算を手伝いたい人は-PMでお願いします。ちょっとした相談が必要です)
githubをいじりたくない人のために、Googledriveにバイナリを投稿しました。 アーカイブを自分に保存するには、Ctrl + Sを押す必要があります。
最初のユーザーによると、誰もがACM MP3コーデックを持っているわけではないことが明らかになりました。そのため、ファイルが処理されない可能性があります。 確かではありませんが、おそらくK-Lite Codec Packのインストールが役立つはずです。
厳しく判断しないよう強くお願いします。すべては熱意をもって行われます。 C#プログラミングは私の主な職業ではありません。
プログラムはプレイリストを保存して開くことができます。サンプルのリストと結果のリストをダブルクリックすると、トラックを開いて聴くことができます。
SQLクエリの最適化や、上記以外の追加のメトリックの作成を手伝いたい人がいれば、個人的なメッセージを書いてください。私は協力して喜んでいます。
プログラムを実行しようとしたときにエラーが発生した場合-書き込みをはるかに少なくして、すべてを支援しようとします。
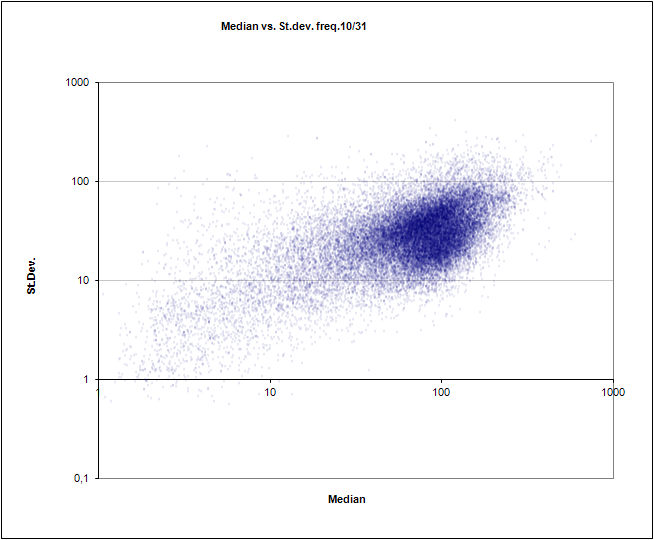
ボーナス:コレクションの分析に基づいたいくつかのチャート
周波数中央値#10 of 31対急勾配
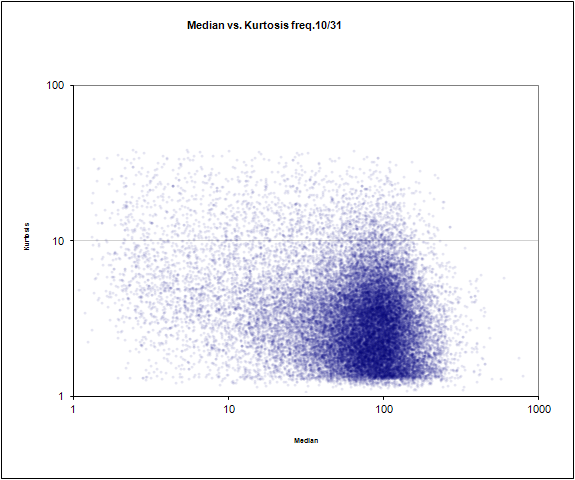
べベルに対して31回中10回の頻度の中央値
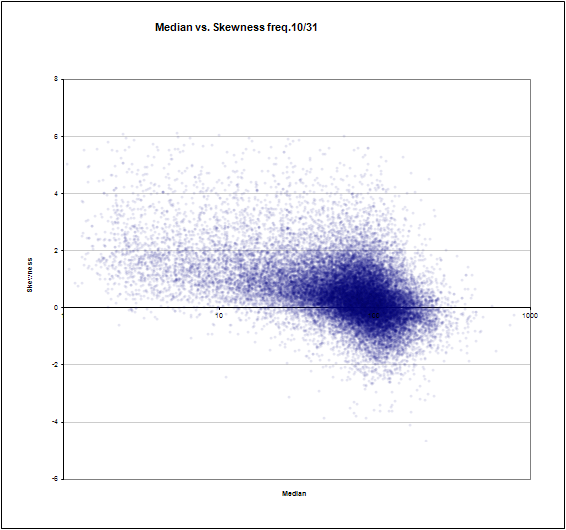
頻度中央値#10 of 31対標準偏差
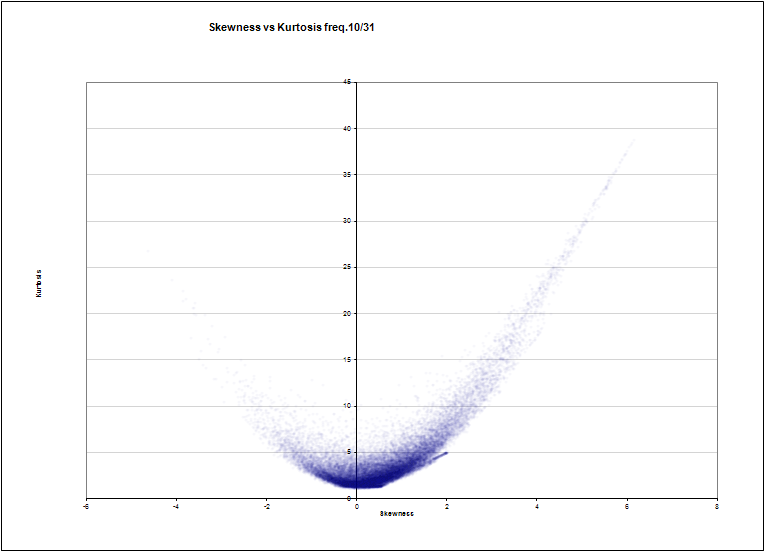
べベルに対する周波数急峻度#10(通常のノイズの多い放物線ではありませんか?)
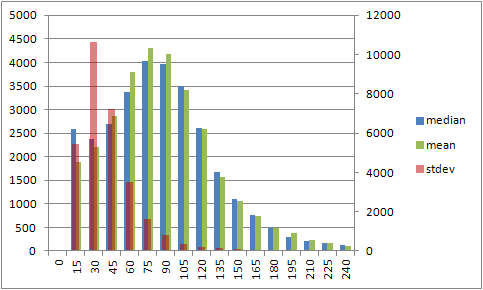
左軸に平均と中央値、右に標準偏差の分布のヒストグラム
すべての周波数の平均値の例(100の周波数でベースに対して行われ、平均値に正規化)

すべての周波数の平滑化されたベベル値のグラフ(100個の周波数、平均値に正規化)

べベルに対して31回中10回の頻度の中央値
頻度中央値#10 of 31対標準偏差
べベルに対する周波数急峻度#10(通常のノイズの多い放物線ではありませんか?)
左軸に平均と中央値、右に標準偏差の分布のヒストグラム
すべての周波数の平均値の例(100の周波数でベースに対して行われ、平均値に正規化)
すべての周波数の平滑化されたベベル値のグラフ(100個の周波数、平均値に正規化)