アプリケーションの最適化についての議論を続けます。これは、 「アプリケーションの最適化の品質に関する簡単な評価はありますか?」の投稿で始まりました。
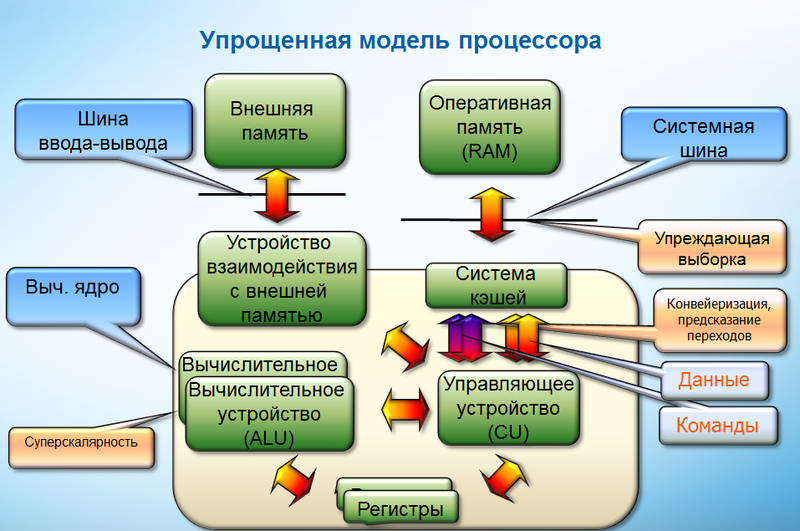
プロセッサーについて詳しく話すことができます。確かに、Habréの読者の中にはそのような会話ができる人がたくさんいます。 しかし、プロセッサに関する私の見解は純粋に実用的です。 アプリケーションのパフォーマンスに興味があるので、プロセッサのパフォーマンスのプリズムを通して、コンピューティングコアの基本原則を理解するだけです。 これらの基本原則に影響を与えるために存在する方法と同様に。 Intel64アーキテクチャに焦点を当てます。 これは、パフォーマンス分析チームで、主にこのアーキテクチャについてインテルの最適化コンパイラの作業を分析しているためです。 高性能コンピューティング用のコンピューティングシステムの市場では、このアーキテクチャと互換性のあるアーキテクチャが最大のシェアを占めているため、パフォーマンスの問題のほとんどはかなり一般的な性質のものです。 カーネルとコンピューティングシステムのパフォーマンスを決定する主な問題と機会を簡単にリストし、これらの問題に影響を与えるように設計されたさまざまな最適化の短いリストを提供します。
命令同時実行レベル
最新のコンピューティングコアの特徴は、パイプライン(パイプライン化)の存在、スーパースカラー性です。 コンピューティングコアには、独立したチームを定義し、指示をスケジュールするためのメカニズムがあります。 つまり これらのメカニズムは、処理のために到着した命令のバッファを見て、適切な計算能力があり、命令がまだ実行されていない他の命令に依存しない場合、実行のためにそれらを選択します。 そのため、Intel64アーキテクチャの特徴は、順不同の実行です。 つまり このようなアーキテクチャの場合、コンパイラは命令の順序の詳細な決定を処理する必要がありません。 パイプラインの負荷レベルは、処理される独立した命令の数、いわゆる命令並列処理のレベルによって決まります。
条件付き遷移の数と遷移予測子の品質
さまざまなコマンドの実行順序は、コードの直線部分をつなぐ制御フローグラフによって決定されます。 制御フローの分岐が発生する場所では、原則として、さまざまな条件付き遷移が使用されます。 つまり、条件が計算されるまで、次にどの命令を実行する必要があるかは明確ではありません。 パイプラインが中断しないようにするために、可能な制御転送パスの1つを選択し、この方向からコンピューティングパイプラインに命令を送り続ける分岐予測メカニズムがコンピューティングコアにあります。 条件が計算された後に行われる検証は、すでに完了した指示を待っています。 予測子が間違えた場合、計算コアのバッファーをクリアして新しい命令をロードする必要があるため、計算コアの作業に遅延が生じます。 この状況は、分岐予測ミスと呼ばれます。 分岐予測メカニズムは非常に複雑で、条件付き遷移に最初に遭遇したときに方向を推測しようとする静的部分と、統計を蓄積して使用する動的部分の両方を含みます。
メモリサブシステムの品質
すべてのメインデータと命令はRAMにあるため、このデータをコンピューティングデバイスに配信できる期間はパフォーマンスにとって重要です。 この場合、メインメモリからデータを受信する際の遅延は、数百プロセッササイクルです。 プロセッサを高速化するために、キャッシュまたはキャッシュのサブシステムがあります。 キャッシュには、メインメモリから頻繁に使用されるデータのコピーが格納されます。 現代のマルチコアプロセッサの場合、カーネルが第1レベルと第2レベルのキャッシュを所有し、プロセッサがコアが共有する第3レベルのキャッシュも持っている場合が一般的です。 最初のレベルのキャッシュはサイズが最小で最速であり、上位階層のキャッシュは低速ですが、大きくなります。 Intel64プロセッサには包括的なキャッシュがあります。 これは、何らかのレベルのキャッシュでアドレスが表される場合、上位階層のキャッシュにも含まれることを意味します。 したがって、メモリからデータを取得する必要がある場合、メモリサブシステムは、第1、第2、および第3レベルのキャッシュ内のアドレスを順次チェックします。 キャッシュミス(つまり、キャッシュに必要な情報がない)の場合、後続の各ケースでは、遅延は大きくなります。 たとえば、Nehalemの場合、異なるレベルのキャッシュへのおおよそのアクセス時間は次のようになります。第1レベルのキャッシュでは4、第2レベルおよび第3レベルのキャッシュではそれぞれ11および38です。 RAMへのアクセスの遅延は約100〜200サイクルです。 メモリサブシステムの動作を理解するには、キャッシュ内の必要な情報の送信と保存が、キャッシュラインと呼ばれる(現時点では)64バイトの固定長のパケットで行われることが重要です。 特定のメモリアドレスが要求されると、一部の「隣接」データが「途中で」キャッシュにロードされます。 システムバスは、キャッシュサブシステムとCPUの間でデータを転送します。 メモリサブシステムの重要な特性は、バス帯域幅です。 単位時間あたりにキャッシュに転送できるキャッシュラインの数。 したがって、システムバスの動作は、アプリケーションの実行におけるボトルネックになることがよくあります。
このようなキャッシュ編成に関連して、プログラムが使用するデータの参照原理の局所性などの要因が大きな役割を果たします。 アプリケーションプロセス中の基本オブジェクトとデータの再利用を特徴付ける時間的局所性と、空間的局所性(比較的近いストレージ領域を持つデータの使用)は区別されます。 また、コンピューティングコアでは、ローカリティの原則をサポートするメカニズムが実装されています。 一時的なローカリティは、最も頻繁に使用されるデータをキャッシュにキャッシュしようとするキャッシュメカニズムによってサポートされます。 キャッシュラインを解放して新しいキャッシュラインをロードする必要があるという問題が発生した場合、最も使用されていないラインは削除されます。 空間的局所性については、事前取得メカニズムが機能します。これは、後続の作業に必要なメモリアドレスを事前に決定しようとします。 同時に、空間的な局所性が高いほど(隣接する要素へのアクセスが進む)、キャッシュにダウンロードする必要があるデータが少なくなり、システムバスの負荷が少なくなります。
ここでは、コンピューティングコアのレジスタを最速のメモリとして言及することもできます。 再利用されたデータをレジスタに保存すると便利です。 計算中にデータがレジスタからスタックにコピーされたり、スタックからコピーされたりすると、レジスタのスピルなどのパフォーマンスの問題が発生します。

ベクトル化の使用
Intel64プロセッサはベクトル命令をサポートしています。 つまり さまざまなタイプのベクトルを作成し、ベクトルを処理し、出力で結果のベクトルを受け取る命令をそれらに適用する可能性があります。 これらはSSEファミリーの指示です。 一連の命令が開発されており、新しいコマンドと機能が追加されています。 SSE2、SSE3、SSE4、AVX-元のアイデアの拡張。 問題は、私たちのプログラミング言語は最初はスカラーであり、コンピューティングコアのこの機能を使用するためにいくらか努力する必要があるということです。 ベクトル化は、スカラーコードをベクトルコードに置き換えるコード変更です。 つまり スカラーデータはベクトルにパックされ、スカラー演算はベクトル(パケット)の演算に置き換えられます。 xmmintrin.hを使用して、ベクトル化を手動でプログラミングしたり、自動ベクトル化で何らかの最適化コンパイラを使用したり、ベクトル命令を使用するユーティリティで最適化されたライブラリを使用したりできます。 この変更を使用する可能性には多くの制限があります。 さらに、収益性を決定する多くの要因があります。 最適化はパフォーマンスを向上させるものであるため、これが変更を記述した理由です。 ベクトル化を改善するには、特定の条件を満たす必要があります。 つまり ベクトル化は単なる「機会」です。 この機会を真の成果につなげるために一生懸命努力する必要があります。
マルチスレッドコンピューティングの使用
最新のプロセッサ上に複数のコンピューティングコアが存在するため、これらのコア間でコンピューティングを分散することにより、高いアプリケーションパフォーマンスを実現できます。 しかし、これは単なる「機会」です。 100万人の高度に専門的なプログラマーがいることは、彼らが1時間で最適化コンパイラを実装できるという希望を与えません。 シングルスレッドのコードをマルチスレッドのコードに変換するには、真剣な努力が必要です。 一部の最適化コンパイラには、マルチスレッドアプリケーションを作成するプロセスを、コンパイル中に単一のオプションを追加するプロセスに減らす自動並列化機能があります。 しかし、自動パラレライザーのパスには非常に多くの落とし穴があるため、多くの場合、最適化コンパイラーが支援を必要とし、多くの場合、それは単に無力です。 OpenMPディレクティブを使用すると、大きな成功を収めることができます。 ただし、ほとんどの場合、最初のシングルスレッドアルゴリズムを並列化するには努力が必要です。 私の意見では、それらは計算アルゴリズムの重大な変更に関連しており、非アルゴリズムコード最適化と呼ばれるものを超えているため、ここでは他の並列化方法については言及しません。
これらの問題に基づいて、実行中のアプリケーションのパフォーマンスを決定する3つの主な特徴と、実装可能な2つの優れた機能を区別できます。
1.)メモリサブシステムの品質。
2.)条件付き遷移の数と遷移予測子の品質。
3.)指導の並行性のレベル。
4.)ベクトル化の使用。
5.)マルチスレッドコンピューティングの使用。
最適化
コンパイラーとプログラマーは、リストされた計算の特性に基づいてどのツールを使用する必要がありますか?
メモリサブシステムを改善するために、ループの交換、ループのブロックへの分割(ループブロッキング)、ループの結合と分割(ループの融合/分配)など、多くのループ最適化が呼び出されます。 これらの最適化には欠点があります。 すべてのサイクルがこのような最適化に適しているわけではなく、主にCおよびFortranのコンピューティングプログラムで使用されています。 コンパイラーは、プリエンプティブバウンスメカニズムを支援し、プリフェッチプログラム命令を自動的に挿入しようとする場合がありますが、これも非常に特殊な操作であり、星の好ましい配置を必要とします。 実行可能モジュールが構築されている場合、動的プロファイラーを使用して、コンパイラは構造体のフィールドを再配置し、コールド領域を個別の構造体に移動することにより、アプリケーションデータの空間的局所性を改善できます。 ある構造から別の構造にフィールドを転送するような最適化もあります。 コンパイラーがそのような最適化の正確さと収益性を証明することは非常に困難ですが、プログラマーがそのようなことを行うのははるかに簡単です。主なことは、1つまたは別のコード変更のアイデアを理解することです
データの局所性を改善する上で重要な役割は、スカラー最適化、つまり データフローの分析、定数の取得、制御グラフの最適化、一般的な部分式の削除、デッドコードの削除に関連する最適化。 これらの最適化により、アプリケーションが実行する必要のある計算量が削減されます。 その結果、命令もキャッシュに保存する必要があるため、命令の数が減り、データの局所性が向上します。 これらの最適化手法の実行品質は、計算効率と呼ばれます。 プロシージャー間の分析は、これらの最適化のすべてに役立ちます。 使用する場合、データフローの分析はグローバルになります。 コンパイラによって処理されている特定のプロシージャのレベルだけでなく、プログラム全体でオブジェクトのプロパティの転送を分析します。 このプロシージャがアプリケーションのさまざまな場所から呼び出された特定の引数のプロパティが調べられ、プロシージャ内で使用され、グローバルオブジェクトのプロパティが調べられます。各関数について、この関数内で使用または変更できるオブジェクトのリストが作成されます。インライン化)および部分的な置換も、データの局所性にプラスの影響を与える可能性があります。 上記の最適化の多くは手作業で行うことはできません。それぞれの拡張された定数の効果はわずかである可能性がありますが、その結果、定数を引っ張ると全体的な効果が得られ、より複雑な最適化の効果を適用してより正確に評価することができます。
さらに、最適化コンパイラは、レジスタの割り当てに多くの注意を払っています。
最適化コンパイラーは、特定のアクションを実行して、条件分岐の数と遷移予測の品質を削減できます。 最も簡単なのは、遷移が発生する条件を変更することにより、静的分岐予測のパフォーマンスを改善することです。 静的予測子は、制御グラフの分岐中に下方遷移が可能な場合、実行されないことを想定しています。 コンパイラがif分岐の確率がelseの確率よりも低いと信じている場合、コンパイラはそれらを交換できます。 非常に強力な最適化は、サイクルから不変チェックを削除することです。 もう1つのよく知られた最適化は、ループの展開です。 制御グラフに沿って条件を引き伸ばす便利なスカラー最適化があります。これにより、冗長なチェックを削除し、それらを組み合わせて、制御グラフを簡素化できます。 また、コンパイラは特定のパターンを認識し、cmovなどの命令を使用してブランチを置き換えることができます。 おそらくより多くの例を挙げることができますが、これは、最適化コンパイラーに、誤った予測による遅延に対処する方法があることも示しています。
命令の並列処理を改善するために、スケジューリングが使用されます。スケジューリングは、コード生成中のコンパイラーの作業の最後の段階で実行されます。
ベクトル化を使用してアプリケーションのパフォーマンスを向上させるために、コンパイラにはループのベクトル化を実行し、スカラーコードをベクトル1に置き換える自動ベクトライザーがあります。 このコンパイラコンポーネントは絶えず進化しており、ベクトル拡張の新しい機能を実装し、認識されたイディオムの数を増やし、混合データループをベクトル化します。さらに、ベクトル化は効率的なコード化のため、さまざまなランタイムチェックをコードに挿入し、マルチバージョンコードを作成しますループ内の反復回数、メモリ内のさまざまなオブジェクトの場所、使用されているマルチメディア拡張機能から。 操作をより効率的にするには、ベクトライザーと他のループ最適化の相互作用が必要です。 コンパイラは常にベクトル化の有効性を証明できるとは限らないため、プログラマーがプログラムに関する知識を活用して生産的なコードの作成を支援できるように、さまざまなディレクティブがサポートされています。
インテル®コンパイラーは、開発者に自動並列化(ループの自動並列化のメカニズム)の使用を提供します。 実際、人件費の観点からマルチスレッドアプリケーションを作成する最も安価な方法は、特別なオプションを使用してアプリケーションの構築を開始することです。 しかし、最適化コンパイラの観点から見ると、これは簡単な作業ではありません。 最適化の実行可能性を証明する必要があります。ループ内で実行される作業量を正しく評価する必要があります。そのため、並列化の決定により生産性が向上します。 自動並列化および自動ベクトル化は、他のループ最適化と相互作用する必要があります。 おそらく、この分野では最高の最適化アルゴリズムはまだ作成されておらず、実験と革新的なアイデアの範囲はまだ素晴らしいです。 プログラマーにとってより明白な並列化メソッドを開発するために、CILK +やThreading Building Blocksなどの新しい言語拡張機能とさまざまなサポートライブラリが作成されます。 まあ、優れた信頼できるOPENMPも割引するには早すぎます。
結論:
以前の投稿で、アプリケーションがどれだけ最適化されているかを理解するための簡単な基準はないことを提案しました。 これは、特定の条件が満たされた場合にのみ使用できるさまざまなパフォーマンス最適化が存在するという事実に由来しています。 これらの条件が満たされているかどうかにかかわらず、これまたはその最適化を行う機会があります-この問題を理解し、アプリケーションのパフォーマンスを分析するプロセスで必要です。 したがって、私の意見では、アプリケーションパフォーマンスの分析は、パフォーマンスに重要なアプリケーション領域の特定、これらの領域のプロセッサの遅延の原因の特定、特定された理由に影響する最適化の使用が可能かどうかの判断、およびベクトル化によるアプリケーションパフォーマンスの向上の可能性の判断に限定されます並列化。
ベクトル化はベクトル化されています(分析の小さな例)
同じアプリケーションであっても、パフォーマンスを分析するときに、まったく驚くべき結果を示すことがあります。 ここで、たとえば、ベクトルがベクトル化されているかどうかを自問しますか? このテストを検討してください。
#include <vector> using namespace std; int main () { vector<float> myvector; vector<float>::iterator it; for(int j=0; j<1000; j++) { it = myvector.end(); it = myvector.insert ( it , j ); } for (int i=1; i < myvector.size(); ++i) myvector[i]++; printf("%f\n",myvector[0]); return 0; }
このテキストをコンパイルするには、VS2008に統合されたIntelコンパイラを使用します。 この場合、サイクルがコードの14行目で公開されているかどうかの質問に興味があります。 –Qvec_report3オプションを使用して、オートベクトライザーレポートを表示します。
icl -Qvec_report3 -Qipo -Qansi_alias vector.cpp
Intel C ++ Intel 64、バージョンMainline Beta Build xで実行されるアプリケーション用のIntel 64コンパイラXE
...
... \ vector.cpp(14):(列30)リマーク:ループがベクトル化されていません:ループ構造がサポートされていません。
...
現在、同じコンパイラを使用していますが、VS2010に既に統合されています。
icl -Qvec_report3 -Qipo -Qansi_alias vector.cpp
...
... \ vector.cpp(14):(列30)備考:LOOP WAS VECTORIZED。
...
ここでは、同じプログラムをコンパイルする際にコンパイラの動作が異なる理由の一番下に到達する方法については説明しません。 (アセンブラーが表示され、コードを前処理できます)。 Intelコンパイラは異なるバージョンのVSに統合されているため、この場合、異なるバージョンのSTLライブラリが使用されます。 STL VS2008バージョンでは、[]演算子に配列の範囲外のチェックが含まれています。 その結果、__ invalid_parameter_noinfoプロシージャの呼び出しがループ内に現れてプログラムを終了し、コンパイラはそのようなループをベクトル化できません。 しかし、VS2010では、そのような検証はもうありません。 なぜだろうか?
–Qansi_aliasオプションを削除すると、ベクトル化も消えてしまうのは面白いです。 実際の整数ではなく整数を格納するベクトルを作成した場合も同じことが起こります。 しかし、これらの「奇跡」の理由は、別の記事の機会です。
一次資料
さまざまなパフォーマンスの問題を調査するための文献: Software Optimization Cookbook、Second Edition、またはThe Software Vectorization Handbook。
さまざまな最適化手法の基本的なソース:Randy Allen、Ken Kennedy。 最新のアーキテクチャ向けのコンパイラの最適化、およびDavid F. Bacon、Susan L. Graham、Oliver J. Sharp。 ハイパフォーマンスコンピューティング用のコンパイラ変換。
プログラムによるコードの改善に関心のあるプログラマーのために、Agner Fog、 Optimizing software in C ++:Windows、Linux and Macプラットフォーム用の最適化ガイドをお勧めします。
雑誌「Open Systems」の記事「Optimizing Compilers」からいくつかの考えをコピーすることを恥ずかしがりませんでした。