
Hunspell辞書(FireFox、Seamonkey、Mirandaなど)を使用するプログラムにこのような不便さを我慢したくないため、いくつかの言語を接着するための自動グラフィカルユーティリティを作成し、結果の辞書をさらに使用する可能性がありました。
創造の歴史
創造の歴史についてのいくつかの行。 このアイデアは、FireFox用の包括的なロシア語-英語辞書を作成した2008年に始まりました。
Mozillaのftpサイトに投稿されました。
ftp.mozilla-russia.org/dictionaries/ru-en_spell_dictionary.xpi
フォーラムにもトピックがありました。
forum.mozilla-russia.org/viewtopic.php?id=15316
その瞬間から多くの時間が経過しましたが、ごく最近、私はほぼ同時に、より新しいものを求めている興味のある人々からいくつかの手紙を受け取りました。
既製の更新を送信するのではなく、ユーザーが複数の辞書を個別に組み立てることができるGUIユーティリティを完成させることにしました。
その瞬間、このユーティリティはDelphiで「自分のために」書かれており、職場で使用されていましたが、これはクロスプラットフォームソリューションとは言えません。
もちろん、Embarcadero RAD Studioの最新バージョンを使用してクロスプラットフォームソリューションを作成できるようになりましたが、Javaを使用した自動ユーティリティの実装に集中することにしました。
挑戦する
最小実装のユーティリティは次のことができるはずです。
1.次の最も一般的な形式から辞書をダウンロードします
-非圧縮ビュー* .dicおよび* .aff
-ZIPアーカイブ(* .zip)
-XPInstall形式(* .xpi)
-拡張機能OpenOffice(* .oxt)
2.接着する辞書を選択する機能を提供する
3.受け取った辞書と説明の名前を変更する機会を与える
4.形式でアップロードする
-非圧縮ビュー* .dicおよび* .aff
-ZIPアーカイブ(* .zip)
-XPInstall形式(* .xpi)
実装
プログラムの作成を開始する前に、辞書をダウンロードして接着できるようにするために、辞書の形式を調べる必要がありました。
Hunspellの情報はここにあります。
hunspell.sourceforge.net
フォーマットの説明
pwet.fr/man/linux/fichiers_speciaux/hunspell
またはロシア語の翻訳で
mozilla-russia.org/projects/dictionary/hunspell.html
つまり、Hunspellスペルチェッカーには2つのファイルが必要です。 最初のファイルは単語(* .dic)を含む辞書で、2番目のファイルは辞書の特別なラベル(フラグ)の値を定義する接辞ファイル(* .aff)です。 フラグは、辞書ファイル内の単語に割り当てられ、接尾辞ファイルで定義されます。
ファイルの形式と構造を考えると、主なタスクは、単に辞書ファイルを接着することに加えて、異なる辞書の接辞を壊さないことでした。
接尾辞ファイルのフラグに名前を付けるには、3つの方法があります。
1.デフォルトでは、各接辞には1文字(レジストリを含む)または数字が付けられます。
2.長い-各接辞は2文字または数字付きの文字と呼ばれます。
3.番号-各接辞には1〜65000の値があります。
ほとんどの場合(私が出会った辞書)、接辞ファイルには数十の異なる接辞フラグしか含まれていなかったため、辞書の作成者は最初のアプローチを1文字で使用できましたが、多数の異なる接辞があるため、複数のファイルの接着には明らかに適していませんでした、したがって、結果のファイルでデジタル命名を使用することが決定されました。 もちろん、マイナスがあります-ファイルサイズがわずかに増加しますが、これは重要ではないと思います。
また、すべてのディクショナリファイルは異なるエンコーディングであることが多いため、統一のために共通のエンコーディングUTF-8が選択されました。
それ以外の場合、特に目に見える問題はありませんでした。
プログラムは辞書をロードし、それらを接着し、重複する単語を無視します。その結果、未使用の接辞フラグが破棄されます。
この記事のフレームワークでは、個々の手順の実装には進みません。希望する人のために、ソースコードをここに投稿したからです。
ANTコレクター用のスクリプトもあります。
code.google.com/p/hunspell-merge
働き方
現在、UbuntuおよびWindows 7のユーティリティを、実装タスクで指定された種類のソースファイルでテストしました。
このコンテンツにはJavaランタイム(JRE)が必要です。
このページから HunspellMerge.jarおよびLinuxまたはWindows OSの起動ファイルをダウンロードします。 Linuxの場合、ファイルを実行する権利を忘れないでください。
Java Webstartの使用を開始することもできます。起動ファイルはこのリンクにあります。
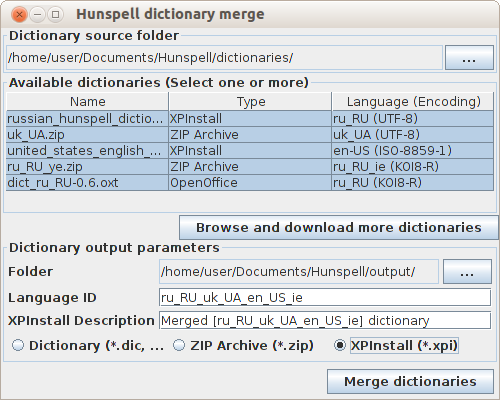
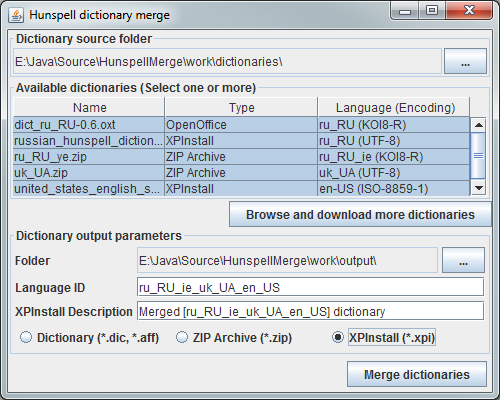
動作するには、一連のソースファイルが必要です。これらのファイルは、デフォルトでユーティリティの作業フォルダーのディクショナリサブフォルダーに配置できます。
追加の辞書は、ここに投稿されているリンクからダウンロードできます。
code.google.com/p/hunspell-merge/wiki/OnlineDictionaries
ユーティリティを起動するか、辞書の新しいソースフォルダーを選択すると、それらが辞書のリストに表示されます。
ユーザーは、いくつかの辞書を選択(CtrlまたはShiftを押しながら)、保存先フォルダーを選択、言語の名前を指定し、ダウンロードがXPInstall形式の場合は、辞書の説明を修正するだけです。
作業結果を使用する
Firefox
出力形式(XPInstall)
ファイルパスをコピーするか、ファイルをブラウザのアドレスバーにドラッグします。
Enterキーを押して、拡張機能をインストールします。
ミランダ/ミランダNG
出力形式(辞書)
ファイル(* .aff、* .dic)をプログラムディレクトリのDictionariesフォルダにコピーします。 Mirandaを再起動します。
計画
このユーティリティは数晩のうちに作成されたため、接辞ファイルの拡張命令をテストおよびサポートする特別な時間はありませんでした。 これは改訂予定ですが、ある言語の一部の命令は別の言語の同じ命令に反する可能性があるため、現在のところ、サフィックス(SFX)、プレフィックス(PFX)、置換(REP)の3種類のメインフラグがサポートされています。
インターフェイスにロシア語を追加します。
また、ドキュメントを作成し、GoogleCodeでページを改良するのもよいでしょう。
おわりに
このような接着された辞書が機能する他のプログラムを聞いてみたいです。
このプログラムには欠陥がないわけではないことを理解しているので、ユーティリティを改善するための提案や提案を喜んで聞きます。
ご関心をお寄せいただきありがとうございます。
UPD判明したように、異なる言語からダウンロードされた、または技術的、経済的など、さまざまな方向性を持つ同じ言語の辞書を単に接着するだけでも役立ちます。