
数日後、別の尊敬すべき一族がやってきて、同じキャプチャのパーサーを注文しました。 それを分析するために、私はもっと多くの時間を費やさなければならず、 Ocradはありませんでしたが、非常にシンプルで効果的な方法が見つかりました。
1週間後、このゲームで3番目の、そして最もふさわしい一族がやって来て、新しいキャプチャを注文しました。 毛布を引っ張って数か月後、ほとんどすべてのトップクランは新しいアーティファクトの写真、カラフルな紙の山の上のプログラマー、たくさんのナンセンスジェネレーターのプロジェクトで豊かになり、私は個人的に貴重な経験をしました。
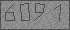


より最近では、この経験は、画像からテキストに戻るサイトの1つからの数千の電話番号を解析するのに役立ちました。 使用されるアルゴリズムは同じであり、共有したいです。 ドライバーとハンマーがあります。シンクロファソトロンや重力銃など、それらを使って集めたものはすでにあなたのビジネスです。
このすべてを最初にPerlで記述し、次にPHPで記述しましたが、リストを持つ人を退屈させる価値はありませんよね?
手順1.マトリックスの画像。
必要に応じて、イメージをxy 、または[x] [y]の形式の2次元マトリックスに解析します。
マトリックスの各要素、つまりピクセルの色に値を割り当てます。
さまざまな色のピクセル数をカウントします。これに関する情報は、通常の配列に入力されます。
ステップ2.過剰を取り除きます。
画像は、256色以下のGIFから取得した場合でも、情報量を減らす必要があります。 色の数を減らします。配列内の参照が最も多い色の少なくとも50%未満のすべての値を破棄します。 一見モノクロの画像からは、通常4色が残ります。 これは原色のリストです。
ステップ3.次に面白いのは、シャープとグレースケールを合計することです。 あなたの手を見てください:
新しい2次元行列b [x] [y]を作成します。 結果を書き込みます。
隣接する4つのピクセル(正方形)を取得します。
これらのピクセルの色の少なくとも1つが原色のリストに残っている場合は、新しい行列にb [0] [0] = Xと書き込みます。 ない場合は、b [0] [0] = 0と書き込みます。
次の4ピクセルを使用します。 マトリックスの最後まで繰り返します。大きな画像の場合は、操作を2回実行することもできます。 ただ夢中にならないでください-画像が複雑になるほど、さらに比較するのが難しくなります。
その結果、次のような美しさが得られます。
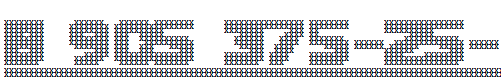
学校で郵便番号を書くように教えたとき、これは子供の頃のものですよね?
最も単純なことは、コンピューターに、十字とゼロで構成されるグラフィックイメージが十進数であることを説明することです。 これを行うには、シンボルごとにマトリックスを部分サブマトリックスに分割し、それらを標準と比較します。 残念ながら、各キャプチャの標準は異なり、わずかではありますが調整する必要があります。
最後に、完成したPHP関数int similar_text(str、str)で使用される類似の文字列を比較するためのOlivierアルゴリズムによって保存されます 。 もちろん、行の長さが短いほど、チェックが速くなるため、「認識された」文字の最初の行を標準の最初の行と比較し、2番目の行と2番目の行を最後まで比較しました。
1個のエラーで4万の電話番号が認識されました。 アルゴリズムをより普遍的なものにするために-そして私たちのポケットの中に100万人ですよね?