特定のケースに何を選択しますか? zaparkiとdeadline'ovの条件では、すべてのjava.util.concurrentをカバーするのはかなり困難です。 同様のものを選択して、行ってください! そのため、徐々にArrayBlockingQueue、ConcurrentHashMap、AtomicInteger、Collections.synchronizedList(新しいLinkedList())およびその他の興味深いものがコードに表示されます。 時には正しい、時にはそうではない。 ある時点で、Javaの標準クラスの95%以上が製品開発でまったく使用されていないことに気付き始めます。 コレクション、プリミティブ、ある場所から別の場所へのバイトの移動、休止状態、SpringまたはEJB、その他のライブラリ、そして出来事、アプリケーションの準備ができました。
少なくとも何らかの方法で知識を合理化し、トピックへの入力を容易にするために、マルチスレッドで作業するためのクラスの概要を以下に示します。 私は主に自分用のチートシートとして書いています。 そして、他の誰かが似合うなら、それは一般的に素晴らしいです。
種子用
すぐにいくつかの興味深いリンクを提供してください。 マルチスレッドで少し泳ぐ人のための最初の。 「高度な」プログラマーのための2番目-ここに何か役に立つかもしれません。
java.util.concurrentパッケージの作成者について少し
誰かがjava.util.concurrentクラスのソースコードを開いた場合、著者のDoug Lea(ダグリー)、Oswego教授(Osuigo)、ニューヨーク大学に気づかずにはいられませんでした。 彼の最も有名な開発のリストには、Java コレクションとutil.concurrentが含まれており、それらは何らかの形で既存のJDKに反映されていました。 また、動的なメモリ割り当てのためのdlmalloc実装も作成しました。 文献の中には、Javaでのマルチスレッドコンカレントプログラミングに関する本:Design Principles and Pattern、2nd Editionがありました 。 詳細については、彼のホームページをご覧ください 。

2010年のJVM Language SummitでのDoug Leaのパフォーマンス。
トップへ
おそらく、多くの人がjava.util.concurrentを見ると混乱を感じていました。 1つのパッケージに、完全に異なる機能を持つ異なるクラスが混在しているため、関連するものとその動作を理解するのが多少難しくなります。 したがって、機能属性に応じてクラスとインターフェースを概略的に分割し、特定の部分の実装を検討できます。
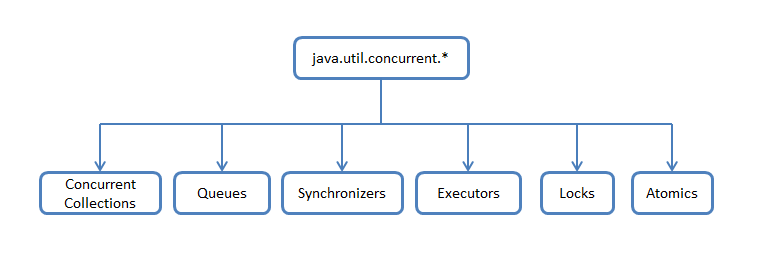
同時コレクション -java.utilパッケージの標準のユニバーサルコレクションよりも、マルチスレッド環境でより効率的に動作するコレクションのコレクション。 コレクション全体へのアクセスをブロックするベースラッパーのCollections.synchronizedListの代わりに、データセグメントのロックが使用されるか、 待機なしのアルゴリズムを使用したデータの並列読み取り用に作業が最適化されます。
キュー -マルチスレッドをサポートする非ブロッキングおよびブロッキングキュー。 ノンブロッキングキューは、スレッドをブロックせずに速度と動作を向上させるために強化されています。 ブロッキングキューは、プロデューサースレッドまたはコンシューマスレッドを「スローダウン」する必要がある場合、たとえばキューが空またはブランド変更された場合、または無料のコンシューマがない場合など、条件が満たされない場合に使用されます。
Synchronizers-スレッド同期のためのヘルパーユーティリティ。 それらは「並列」コンピューティングの強力な武器です。
エグゼキューター -スレッドプールを作成し、結果を取得して非同期タスクをスケジュールするための優れたフレームワークが含まれています。
ロック -基本的なsynchronized、wait、notify、notifyAllと比較して、フローの同期の代替のより柔軟なメカニズムを表します。
アトミック -プリミティブおよびリンクのアトミック操作をサポートするクラス。
1.コンカレントコレクション
CopyOnWriteコレクション
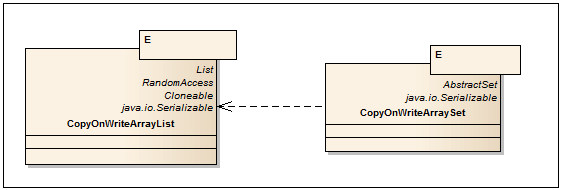
名前はそれ自体を物語っています。 コレクションを変更するすべての操作(追加、設定、削除)により、内部アレイの新しいコピーが作成されます。 これにより、コレクションを反復処理するときにConcurrentModificationExceptionがスローされなくなります。 配列をコピーする場合、オブジェクトへの参照(リンク)(浅いコピー)のみがコピーされることに注意してください。 要素フィールドへのアクセスはスレッドセーフではありません。 CopyOnWriteコレクションは、書き込み操作が非常にまれな場合、たとえば、リスナーサブスクリプションメカニズムを実装してそれらを通過する場合に使用すると便利です。
CopyOnWriteArrayList <E>

 -CopyOnWriteアルゴリズムで実装されたArrayListのストリームセーフアナログ。
-CopyOnWriteアルゴリズムで実装されたArrayListのストリームセーフアナログ。 追加のメソッドとコンストラクター
| CopyOnWriteArrayList(E [] toCopyIn) | 入力として配列を受け取るコンストラクター。 |
| int indexOf(E e、int index) | 指定されたインデックスから検索を開始し、最初に見つかった要素のインデックスを返します。 |
| int lastIndexOf(E e、int index) | 指定されたインデックスから開始して、逆検索で見つかった最初の要素のインデックスを返します。 |
| boolean addIfAbsent(E e) | コレクションにないアイテムを追加します。 equalsメソッドは、要素を比較するために使用されます。 |
| int addAllAbsent(コレクション<?extends E> c) | コレクションにないアイテムを追加します。 追加されたアイテムの数を返します。 |
CopyOnWriteArraySet <E>
-CopyOnWriteArrayListをベースとして使用したSetインターフェイスの実装。 CopyOnWriteArrayListとは異なり、追加のメソッドはありません。
スケーラブルなマップ
HashMap、TreeMapの実装が改善され、マルチスレッドとスケーラビリティのサポートが改善されました。
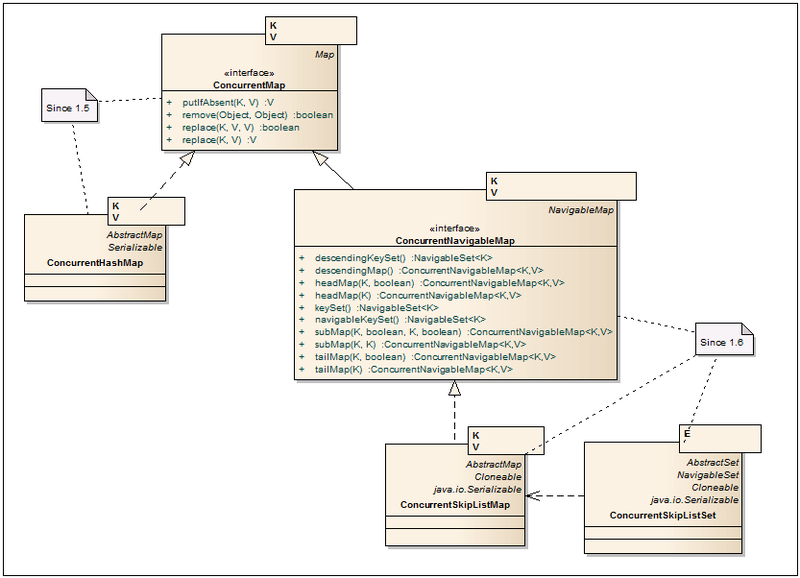
ConcurrentMap <K、V>
 -いくつかの追加のアトミック操作でMapを拡張するインターフェース。
-いくつかの追加のアトミック操作でMapを拡張するインターフェース。
追加の方法
| V putIfAbsent(Kキー、V値) | キーがコレクションにない場合にのみ、新しいキーと値のペアを追加します。 指定されたキーの以前の値を返します。 |
| boolean remove(オブジェクトキー、オブジェクト値) | 指定されたキーがMapの指定された値と一致する場合にのみ、キーと値のペアを削除します。 アイテムが正常に削除された場合、trueを返します。 |
| ブール置換(Kキー、V oldValue、V newValue) | 古い値がMapで指定された値と一致する場合にのみ、キーで古い値を新しい値に置き換えます。 値が新しい値に置き換えられた場合、trueを返します。 |
| V置換(Kキー、V値) | キーがいずれかの値に関連付けられている場合にのみ、キーによって古い値を新しい値に置き換えます。 指定されたキーの以前の値を返します。 |
ConcurrentHashMap <K、V>
-HashMapのHashtableおよび同期ブロックとは異なり、データはハッシュキーで分割されたセグメントの形式で表示されます。 その結果、データへのアクセスは、1つのオブジェクトではなくセグメントによってロックされます。 さらに、反復子は特定のタイムスライスのデータを提示し、ConcurrentModificationExceptionをスローしません。 ConcurrentHashMapの詳細については、 こちらの habratopikaを参照してください 。 追加のコンストラクタ
| ConcurrentHashMap(int initialCapacity、float loadFactor、int concurrencyLevel) | コンストラクターの3番目のパラメーターは、同時に書き込むスレッドの予想数です。 デフォルト値は16です。メモリ内のコレクションのサイズとパフォーマンスに影響します。 |
ConcurrentNavigableMap <K、V>
 -NavigableMapインターフェースを拡張し、戻り値としてConcurrentNavigableMapオブジェクトの使用を強制します。 すべての反復子は安全に使用できると宣言されており、ConcurrentModificationExceptionをスローしません。
-NavigableMapインターフェースを拡張し、戻り値としてConcurrentNavigableMapオブジェクトの使用を強制します。 すべての反復子は安全に使用できると宣言されており、ConcurrentModificationExceptionをスローしません。
ConcurrentSkipListMap <K、V>
-これは、マルチスレッドをサポートするTreeMapの類似物です。 また、データはキーでソートされ、containsKey、get、put、removeなどの同様の操作の平均ログ(N)パフォーマンスが保証されます。 SkipList操作アルゴリズムは、 WikiおよびHabrで説明されています。
ConcurrentSkipListSet <E>
-ConcurrentSkipListMapに基づくSetインターフェイスの実装。
2.キュー
ノンブロッキングキュー

リンクされたノードでのスレッドセーフでノンブロッキングのキュー実装。
ConcurrentLinkedQueue <E>
-実装では、Michael&Scottの待機不要アルゴリズムを使用し、ガベージコレクターでの作業に適合しています。 このアルゴリズムは非常に効率的であり、最も重要なことには、非常に高速です。 CAS上に構築。 size()メソッドは、長時間にわたって機能します。 常に引っ張らない方が良いです ここでアルゴリズムの詳細な説明を見つけることができます 。
ConcurrentLinkedDeque <E>
 -Dequeは、二重終了キューの略で、「デッキ」と表示されます。 これは、データを両側で追加およびプルできることを意味します。 したがって、クラスはFIFO(先入れ先出し)とLIFO(後入れ先出し)の両方の動作モードをサポートします。 実際には、LIFOが必要な場合にのみConcurrentLinkedDequeを使用する必要があります。 ノードの双方向性により、このクラスはConcurrentLinkedQueueと比較してパフォーマンスが40%低下します。
-Dequeは、二重終了キューの略で、「デッキ」と表示されます。 これは、データを両側で追加およびプルできることを意味します。 したがって、クラスはFIFO(先入れ先出し)とLIFO(後入れ先出し)の両方の動作モードをサポートします。 実際には、LIFOが必要な場合にのみConcurrentLinkedDequeを使用する必要があります。 ノードの双方向性により、このクラスはConcurrentLinkedQueueと比較してパフォーマンスが40%低下します。
ブロッキングキュー
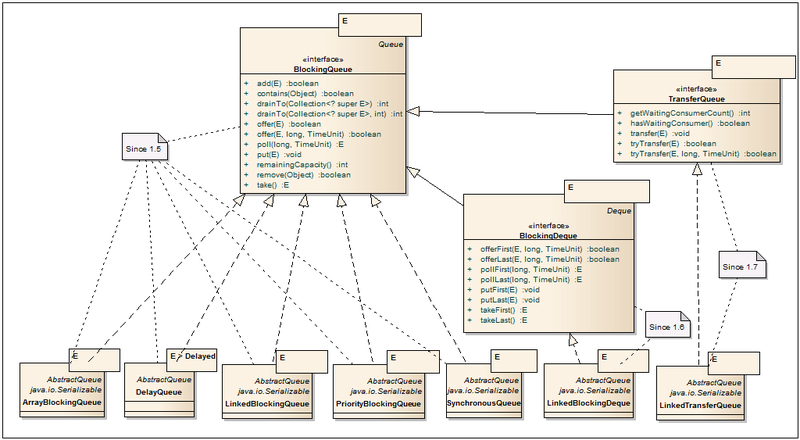
BlockingQueue <E>
-キューを介して大きなデータストリームを処理する場合、ConcurrentLinkedQueueの使用では明らかに不十分です。 キューをレイクしているストリームがデータの流入に対処しなくなった場合、メモリからすぐに抜け出すか、IO / Netに過負荷をかけることができるため、タイムアウトやシステム内の空きディスクリプタの不足によりシステムがクラッシュするまでパフォーマンスが低下することがあります。 そのような場合には、キューのサイズを設定する機能を備えたキュー、または条件に応じたロックを備えたキューが必要です。 ここにBlockingQueueインターフェースが表示され、有用なクラスのセット全体への道が開かれます。 キューのサイズを設定する機能に加えて、キューの非充填またはオーバーフローに対して異なる応答をする新しいメソッドが追加されました。 したがって、たとえば、オーバーフローしたキューに要素を追加すると、1つのメソッドはIllegalStateExceptionをスローし、もう1つのメソッドはfalseを返し、3番目は場所が表示されるまでストリームをブロックし、4番目はタイムアウトでストリームをブロックし、場所が表示されない場合はfalseを返します。 また、ブロッキングキューはnull値をサポートしていないことにも注意してください。 この値は、ポーリング方法でタイムアウトインジケータとして使用されます。
ArrayBlockingQueue <E>
-クラシックリングバッファ上に構築されたブロッキングキュークラス。 キューのサイズに加えて、ロックの「誠実さ」を管理する機能を利用できます。 fair = false(デフォルト)の場合、スレッドのシーケンスは保証されません。 「正直」の詳細については、ReentrantLockの説明を参照してください。
DelayQueue <E extends Delayed>
-遅延インターフェイスのgetDelayメソッドを使用して各アイテムで定義された特定の遅延の後にのみ、キューからアイテムをプルできるようにするかなり具体的なクラス。
LinkedBlockingQueue <E>
-「2ロックキュー」アルゴリズムで実装されたリンクノードのブロッキングキュー:1つのロックは追加し、もう1つのロックは要素を引き出します。 2つのロックのため、ArrayBlockingQueueと比較して、このクラスはより高いパフォーマンスを示しますが、メモリ消費量が多くなります。 キューサイズはコンストラクターで指定され、デフォルトはInteger.MAX_VALUEです。
PriorityBlockingQueue <E>
-PriorityQueueのマルチスレッドラッパーです。 要素がキューに挿入されると、Comparatorのロジックまたは要素のComparableインターフェイスの実装に従って、その順序が決定されます。 最小の要素が最初にキューから出てきます。
SynchronousQueue <E>
-この行は、1つが入力され、1つが左にあるという原則に基づいて機能します。 各挿入操作は、「コンシューマ」ストリームがキューからアイテムをプルするまで「プロデューサー」ストリームをブロックし、逆も同様です。「コンシューマ」は「プロデューサー」がアイテムを挿入するまで待機します。
BlockingDeque <E>
-双方向ブロッキングキューの追加メソッドを記述するインターフェイス。 データは、キューの両側で挿入および引き出すことができます。
LinkedBlockingDeque <E>
-リンクされたノード上の双方向ブロッキングキュー。1つのロックを持つ単純な双方向リストとして実装されます。 キューサイズはコンストラクターで指定され、デフォルトはInteger.MAX_VALUEです。
TransferQueue <E>
-このインターフェースは、アイテムをキューに追加するときに、別のスレッド「消費者」がキューからアイテムを引き出すまで「プロデューサー」を挿入するスレッドをブロックできるという点で興味深いかもしれません。 ロックは、タイムアウトを設定することも、保留中の「Consumer」をチェックすることで置き換えることもできます。 したがって、同期メッセージと非同期メッセージの両方をサポートするメッセージ転送メカニズムを実装することが可能になります。
LinkedTransferQueue <E>
-Slackアルゴリズムを備えたデュアルキューに基づくTransferQueueの実装。 スタンバイモードの場合、 CASおよびパーキングストリームをアクティブに使用します。
3.シンクロナイザー
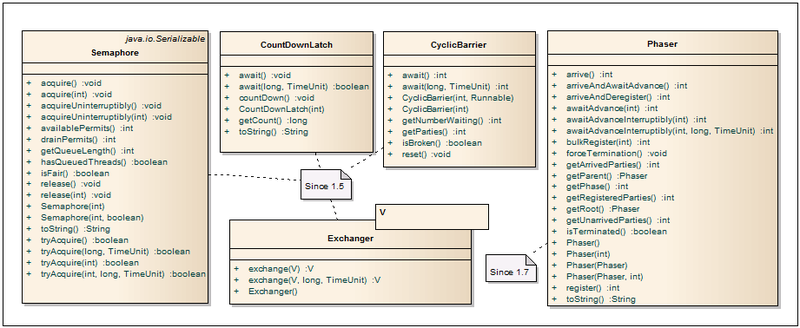
このセクションでは、スレッドをアクティブに管理するためのクラスを提供します。
セマフォ
- セマフォは 、ハードウェアリソースまたはファイルシステムを操作するときにスレッドの数を制限するために最もよく使用されます。 共有リソースへのアクセスは、カウンターによって制御されます。 ゼロより大きい場合、アクセスが許可され、カウンター値が減少します。 カウンターがゼロの場合、現在のスレッドは、別のスレッドがリソースを解放するまでブロックされます。 スレッドのリリースの許可と「正直さ」の数は、コンストラクターによって設定されます。 セマフォを使用する際のボトルネックは、アクセス許可の数を設定することです。 多くの場合、この番号は「鉄」の力に応じて選択する必要があります。
CountDownLatch
-1つ以上のスレッドが、他のスレッドで特定の数の操作が完了するまで待機できるようにします。 古典的なドライバーの例は、クラスのロジックを非常によく説明しています。ドライバーを呼び出すスレッドは、ドライバーを持つスレッドが初期化してからcountDownメソッドを呼び出すまで、awaitメソッドで(タイムアウトの有無にかかわらず)ハングします。 このメソッドは、カウントダウンカウンターを1つ減らします。 カウンターがゼロになるとすぐに、awaitで待機中のすべてのスレッドが機能し続け、すべての後続のawait呼び出しは待機せずに実行されます。 カウントダウンカウンターは1回であり、元の状態にリセットすることはできません。
CyclicBarrier
-ある時点で特定の数のスレッドを同期するために使用できます。 Nスレッドがawait(...)メソッドを呼び出してロックすると、バリアが実現します。 その後、カウンターは元の値にリセットされ、待機中のスレッドは解放されます。 さらに、必要に応じて、スレッドのロックを解除してカウンターをリセットする前に特別なコードを実行することができます。 これを行うには、Runnableインターフェイスの実装を持つオブジェクトがコンストラクターを介して渡されます。
エクスチェンジャー<V>
-名前が示すように、このクラスの主な目的は、2つのストリーム間でオブジェクトを交換することです。 同時に、null値もサポートされているため、このクラスを使用して1つのオブジェクトのみを転送したり、2つのストリームのシンクロナイザーとして転送したりできます。 exchange(...)メソッドを呼び出す最初のスレッドは、同じメソッドが2番目のスレッドを呼び出すまでブロックします。 これが発生すると、スレッドは値を交換し、作業を続行します。
フェイザー
-スレッド同期のバリアの改善された実装。CyclicBarrierとCountDownLatchの機能を組み合わせ、それらの最高の機能を組み込みます。 そのため、スレッドの数は厳密に設定されておらず、動的に変更できます。 クラスを再利用して、ストリームをブロックせずにストリームの準備状況を報告できます。 詳細については、habratopikaをご覧ください 。
4.エグゼキューター
それで、私たちはパッケージの大部分に到達しました。 ここでは、FutureインターフェイスとCallableインターフェイスを介して結果を取得する可能性がある非同期タスクを実行するためのインターフェイス、およびスレッドプールを作成するためのサービスとファクトリー、ThreadPoolExecutor、ScheduledPoolExecutor、ForkJoinPoolについて説明します。 理解を深めるために、インターフェイスとクラスを少し分解します。
未来と呼び出し可能
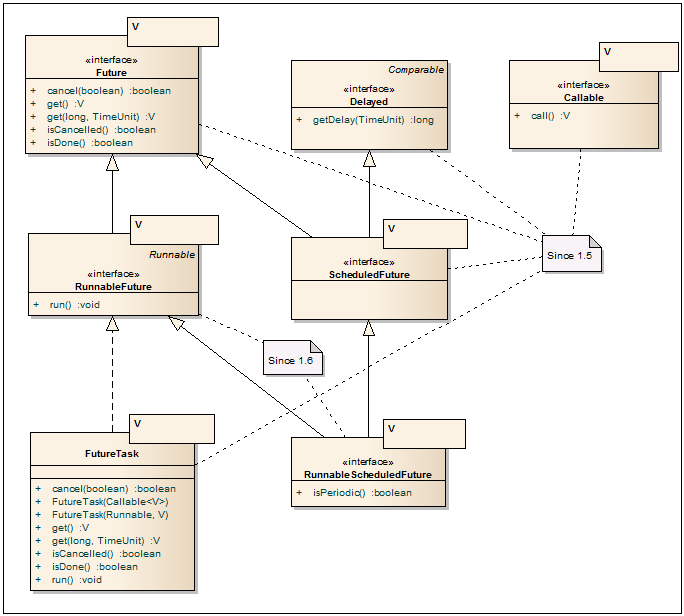
未来<v>
-非同期操作の結果を取得するための優れたインターフェース。 ここで重要なメソッドはgetメソッドです。このメソッドは、他のスレッドの非同期操作が完了するまで、現在のスレッドを(タイムアウト付きまたはタイムアウトなしで)ブロックします。 また、操作をキャンセルして現在のステータスを確認するための追加の方法があります。 FutureTaskクラスは、実装としてよく使用されます。
RunnableFuture <V>
-FutureがクライアントAPIのインターフェイスである場合、RunnableFutureインターフェイスは既に非同期部分の実行に使用されています。 run()メソッドが正常に完了すると、非同期操作が完了し、getメソッドを使用して結果をプルできます。
呼び出し可能<V>
-非同期操作用のRunnableインターフェースの拡張アナログ。 入力した値を返し、チェック済み例外をスローできます。 このインターフェースにはrun()メソッドがありませんが、多くのjava.util.concurrentクラスはRunnableとともにそれをサポートしています。
FutureTask <V>
-Future / RunnableFutureインターフェースの実装。 非同期操作は、RunnableまたはCallableオブジェクトの形式で、コンストラクターの1つの入力で受信されます。 FutureTaskクラス自体は、たとえば、新しいThread(タスク).start()またはThreadPoolExecutorを介して、ワーカースレッドで実行されるように設計されています。 非同期操作の結果は、get(...)メソッドを使用してプルされます。
遅れた
-将来、およびDelayQueueで開始される非同期タスクに使用されます。 非同期操作を開始するまでの時間を設定できます。
ScheduledFuture <V>
-FutureおよびDelayedインターフェイスを組み合わせたトークンインターフェイス。
RunnableScheduledFuture <V>
-RunnableFutureとScheduledFutureを組み合わせたインターフェース。 さらに、タスクが1回限りのタスクであるか、指定した頻度で開始する必要があるかを指定できます。
エグゼキューターサービス
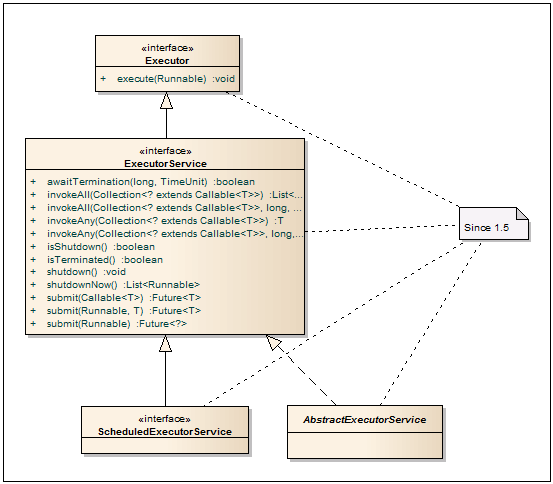
執行者
-Runnableタスクの起動を実装するクラスに基本的なインターフェースを提供します。 これにより、タスクの追加と開始方法の分離が保証されます。
ExecutorService
-RunnableまたはCallableタスクを実行するサービスを記述するインターフェース。 入力サブミットメソッドは、CallableまたはRunnableの形式でタスクを受け入れ、Futureが戻り値として使用され、それを通じて結果を取得できます。 InvokeAllメソッドは、転送されたリスト内のすべてのタスクが完了するまで、または指定されたタイムアウトの期限が切れるまで、スレッドブロック付きのタスクリストで動作します。 invokeAnyメソッドは、転送されたタスクのいずれかが完了するまで呼び出しスレッドをブロックします。 すべてに加えて、インターフェースには正常なシャットダウンのためのメソッドが含まれています。 shutdownメソッドを呼び出した後、このサービスはタスクを受け入れなくなり、サービスにタスクをスローしようとするとRejectedExecutionExceptionをスローします。
ScheduledExecutorService
-ExecutorServiceメソッドに加えて、このインターフェイスは保留中のタスクを実行する機能を追加します。
AbstractExecutorService
 -ExecutorServiceを構築するための抽象クラス。 実装には、submit、invokeAll、invokeAnyメソッドの基本的な実装が含まれます。 ThreadPoolExecutor、ScheduledThreadPoolExecutor、およびForkJoinPoolは、このクラスを継承します。
-ExecutorServiceを構築するための抽象クラス。 実装には、submit、invokeAll、invokeAnyメソッドの基本的な実装が含まれます。 ThreadPoolExecutor、ScheduledThreadPoolExecutor、およびForkJoinPoolは、このクラスを継承します。
ThreadPoolExecutor&Factory
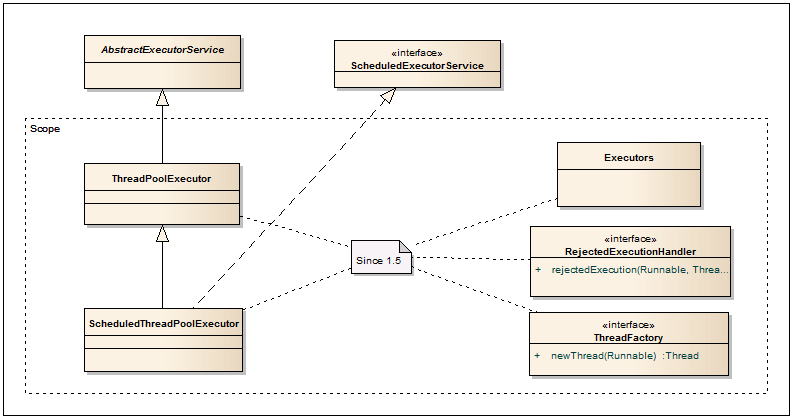
執行者
 -ThreadPoolExecutor、ScheduledThreadPoolExecutorを作成するためのファクトリクラス。 これらのプールのいずれかを作成する必要がある場合、このファクトリーがまさに必要なものです。 また、さまざまなRunnable-Callable、PrivilegedAction-Callable、PrivilegedExceptionAction-Callableアダプターなどが含まれています。
-ThreadPoolExecutor、ScheduledThreadPoolExecutorを作成するためのファクトリクラス。 これらのプールのいずれかを作成する必要がある場合、このファクトリーがまさに必要なものです。 また、さまざまなRunnable-Callable、PrivilegedAction-Callable、PrivilegedExceptionAction-Callableアダプターなどが含まれています。
ThreadPoolExecutor
-非常に強力で重要なクラス。 スレッドプールで非同期タスクを実行するために使用されます。 したがって、フローを発生および停止するためのオーバーヘッドはほぼ完全になくなります。 また、プール内のスレッドの最大数が固定されているため、予測されるアプリケーションパフォーマンスが提供されます。 前述のとおり、Executorsファクトリメソッドの1つを使用してこのプールを作成することをお勧めします。 標準構成では不十分な場合は、デザイナーまたはセッターを使用して、プールのすべての基本パラメーターを設定できます。 詳細については、このトピックを参照してください。
ScheduledThreadPoolExecutor
-ThreadPoolExecutorメソッドに加えて、特定の遅延の後、特定の頻度でタスクを開始できるため、このクラスに基づいてタイマーサービスを実装できます。
スレッドファクトリー
-デフォルトでは、ThreadPoolExecutorはExecutors.defaultThreadFactory()を通じて取得した標準のスレッドファクトリを使用します。 優先順位やスレッド名の設定など、さらに必要なものがある場合は、このインターフェイスの実装を使用してクラスを作成し、ThreadPoolExecutorに渡すことができます。
RejectedExecutionHandler
-何らかの理由でThreadPoolExecutorを介して実行できないタスクのハンドラーを定義できます。 このようなケースは、空きスレッドがないか、サービスがシャットダウンまたはシャットダウンされたときに発生する可能性があります。 ThreadPoolExecutorクラスにはいくつかの標準実装があります。CallerRunsPolicy-呼び出し元のスレッドでタスクを実行します。 AbortPolicy-受け入れをスローします。 DiscardPolicy-タスクを無視します。 DiscardOldestPolicy-最も古い非実行タスクをキューから削除し、新しいタスクの追加を再試行します。
フォーク参加

Java 1.7では、 分割統治アルゴリズムまたはMap Reduceで動作する再帰タスクを解決するために、新しいFork Joinフレームワークが導入されました。 より明確にするために、クイックソートソートアルゴリズムの視覚的な例を示します。
そのため、パーツに分割することにより、異なるスレッドで並列処理を実現できます。 この問題を解決するには、通常のThreadPoolExecutorを使用できますが、コンテキストの頻繁な切り替えと実行制御の監視のため、これらはすべて効果的に機能しません。 これが、 ワークスティークアルゴリズムに基づいたFork Joinフレームワークの助けとなります。 多数のプロセッサを搭載したシステムで最もよく表れます。 詳細については、 こちらのブログまたはDoug Leaの出版物を ご覧ください 。 ここでパフォーマンスとスケーラビリティについて読むことができます 。
フォークジョインプール
-ルート(メイン)ForkJoinTaskタスクを起動するためのエントリポイントを表します。 サブタスクは、発射する必要のあるタスクのメソッドを介して起動されます(フォーク)。 デフォルトでは、スレッドプールは、JVMで使用可能なコアの数と等しいスレッド数で作成されます。
ForkJoinTask
-すべてのFork Joinタスクの基本クラス。 主なメソッドは次のとおりです。fork()-非同期実行のために現在のForkJoinWorkerThreadスレッドのキューにタスクを追加します。 invoke()-現在のスレッドでタスクを起動します。 join()-サブタスクの完了を待って結果を返します。 invokeAll(...)-以前の3つの操作をすべて組み合わせて、2つ以上のタスクを一度に実行します。 適応(...)-RunnableまたはCallableオブジェクトから新しいForkJoinTaskタスクを作成します。
RecursiveTask
-相続人の非同期操作を実行する必要があるcomputeメソッドの宣言を含むForkJoinTaskの抽象クラス。
RecursiveAction
-結果を返さないという点でRecursiveTaskとは異なります。
ForkJoinWorkerThread
-ForkJoinPollのデフォルト実装として使用されます。 必要に応じて、ワーカースレッドの初期化および完了のメソッドを継承およびオーバーロードできます。
完了サービス
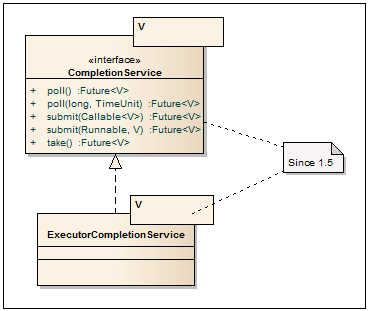
CompletionService
-非同期タスクの開始と結果の取得を分離したサービスインターフェイス。 そのため、タスクを追加するにはsubmitメソッドを使用し、 完了したタスクの結果を引き出すには、blockingメソッドtakeおよびnon-blocking pollを使用します。
ExecutorCompletionService
-実際、それはThreadPoolExecutorやForkJoinPoolなど、Executorインターフェースを実装するクラスのラッパーです。 主に、タスクの開始方法を抽象化し、実行を制御する場合に使用されます。 完了したタスクがある場合-それらを引き出し、そうでない場合-何かが完了するまでテイクインで待ちます。 デフォルトのサービスはLinkedBlockingQueueに基づいていますが、他のBlockingQueue実装を渡すことができます。
5.ロック
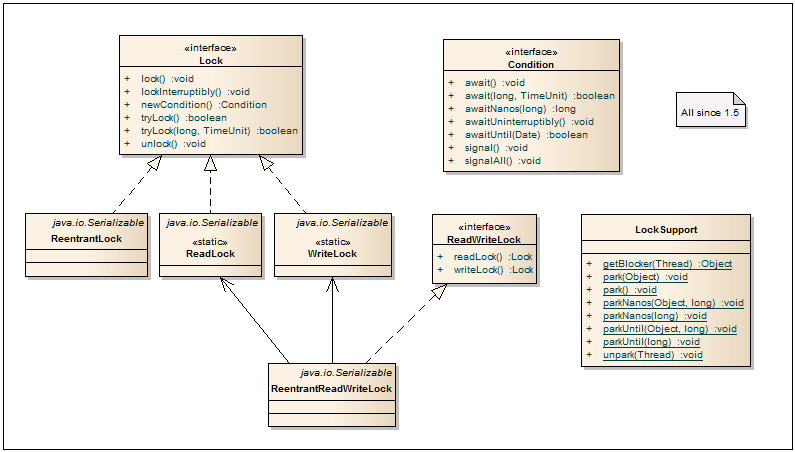
状態
-標準のwait / notify / notifyAllを使用した代替メソッドを記述するインターフェース。 条件を持つオブジェクトは、ほとんどの場合、lock.newCondition()メソッドを介してロックから取得されます。 したがって、1つのオブジェクトに対して複数セットの待機/通知を取得できます。
ロックする
-ロックフレームワークからの基本インターフェイス。同期を使用する場合よりも、リソース/ブロックへのアクセスを制限するためのより柔軟なアプローチを提供します。 そのため、複数のロックを使用する場合、それらのリリースの順序は任意です。 さらに、ロックが既に誰かによってキャプチャされている場合、別のシナリオに従う機会があります。
再入可能ロック
-入場時にロックします。 保護されたブロックに入ることができるスレッドは1つだけです。 このクラスは、フェアおよび非フェアスレッドのロック解除をサポートしています。 「正直な」ロック解除では、lock()を呼び出すスレッドが解放される順序が尊重されます。 「不公平な」ロック解除では、スレッドの解放の順序は保証されませんが、ボーナスとして、そのようなロック解除はより速く機能します。 デフォルトでは、「不公平な」ロック解除が使用されます。
ReadWriteLock
-読み取り/書き込みロックを作成するための追加インターフェース。 このようなロックは、システムに多くの読み取り操作があり、書き込み操作が少ない場合に非常に役立ちます。
ReentrantReadWriteLock
-マルチスレッドサービスおよびキャッシュで頻繁に使用され、同期ブロックと比較して非常に優れたパフォーマンスの向上を示します。 実際、このクラスは相互に排他的な2つのモードで動作します。多くのリーダーは並行してデータを読み取り、1つのライターのみがデータを書き込みます。
ReentrantReadWriteLock.ReadLock
-readWriteLock.readLock()で取得したリーダーの読み取りロック。
ReentrantReadWriteLock.WriteLock
-readWriteLock.writeLock()を介して取得されたライターの書き込みロック。
ロックサポート
-ロック付きのクラスを構築するように設計されています。 廃止されたThread.suspend()およびThread.resume()メソッドの代わりに、スレッドを駐車するためのメソッドが含まれています。
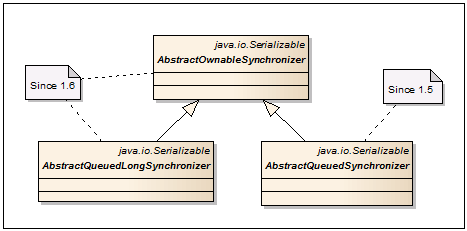
AbstractOwnableSynchronizer
-同期メカニズムを構築するための基本クラス。 データを処理できる排他ストリームを格納および読み取るためのゲッター/セッターのペアが1つだけ含まれています。
AbstractQueuedSynchronizer
-FutureTask、CountDownLatch、Semaphore、ReentrantLock、ReentrantReadWriteLockの同期メカニズムの基本クラスとして使用されます。単一のアトミックint値に依存する新しい同期メカニズムを作成するために使用できます。
AbstractQueuedLongSynchronizer
-longのアトミック値をサポートするAbstractQueuedSynchronizerのバリエーション。
6.アトミック

AtomicBoolean、AtomicInteger、AtomicLong、AtomicIntegerArray、AtomicLongArray-
クラスが1つの単純なint変数へのアクセスを同期する必要がある場合はどうなりますか?シンクロナイズドを使用して構築を使用できます。アトミック操作set / getを使用する場合、volatileも適しています。しかし、新しいAtomic *クラスを使用すると、さらに改善できます。CASを使用するため、これらのクラスでの操作は、synchronized / volatileを介して同期する場合よりも高速です。さらに、特定の値によるアトミック加算、およびインクリメント/デクリメントのメソッドがあります。
AtomicReference-
オブジェクトへの参照を持つアトミック操作のクラス。
AtomicMarkableReference-
次のフィールドのペアを持つアトミック操作のクラス:オブジェクト参照とビットフラグ(true / false)。
AtomicStampedReference-
オブジェクト参照とint値のフィールドのペアを持つアトミック操作のクラス。
AtomicReferenceArray-
アトミックに更新できるオブジェクト参照の配列。
AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater-
リフレクションを通じて名前でフィールドを原子的に更新するためのクラス。 CASのフィールドオフセットは、コンストラクターで決定され、キャッシュされます。反射によるパフォーマンスの大幅な低下はありません。
結論の代わりに
最後まで読んでいただき、ありがとうございます。少なくとも最後まで記事をスクロールしてください。ここでは例を挙げずにクラスの簡単な説明にすぎないことを強調したいだけです。これは、過剰なコード挿入で記事が乱雑にならないように特に行われます。主なアイデア:どの方向に移動し、何を使用できるかを知るために、クラスの概要を簡単に示します。クラスの使用例は、インターネットまたはクラス自体のソースコードで簡単に見つけることができます。この投稿が、マルチスレッドの興味深い問題を迅速かつ効率的に解決するのに役立つことを願っています。
