自動認識の後、I、l、1、O、0など、互いに類似した文字でエラーが発生することがよくあります。 Timesのような通常のフォントを使用している場合、そのようなエラーは気付かないかもしれません。 そのため、Distributed Proofreadersプロジェクト用に特別なフォントが作成されました。このフォントでは、「類似した」文字が互いに可能な限り異なります。
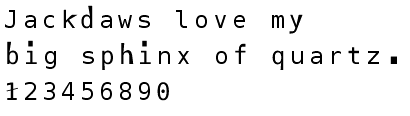
すべてのフォント文字は、プロジェクト参加者である自主校正者の多数のヒントと要望を考慮して設計されています。 目標は、典型的なOCRエラーをできるだけ便利かつ効率的に識別することです。
残念ながら、歴史的な理由でDistributed ProofreadersサイトはUnicodeをサポートしておらず、コミュニティはキリル文字を含まない非常に限られた言語のリストで動作します。 したがって、フォントDPCustomMono2自体はラテンアルファベット専用に設計されています。 しかし、フォントデザイナーが適用したアイデアは、キリル文字セットを作成するためにも使用できます。
このページでは、 DPCustomMono2をさまざまな一般的なフォントと比較できます。
