この資料をスライドとそれらのコメントの形で共有したいと思います。
テストは特定のプロジェクトで実行されましたが、一般に、メッセージの処理(タスクの完了)に少なくともかなりの時間がかかる(1秒あたり1000未満のメッセージを処理する場合)ほとんどの場合有効です。
*スライドでは、「購読者」という言葉の代わりに、「消費者」が均一性のコメントにも使用されています
* 5つのコンシューマーを持つ単一のキューが考慮されます(C1..C5)
理想的な条件
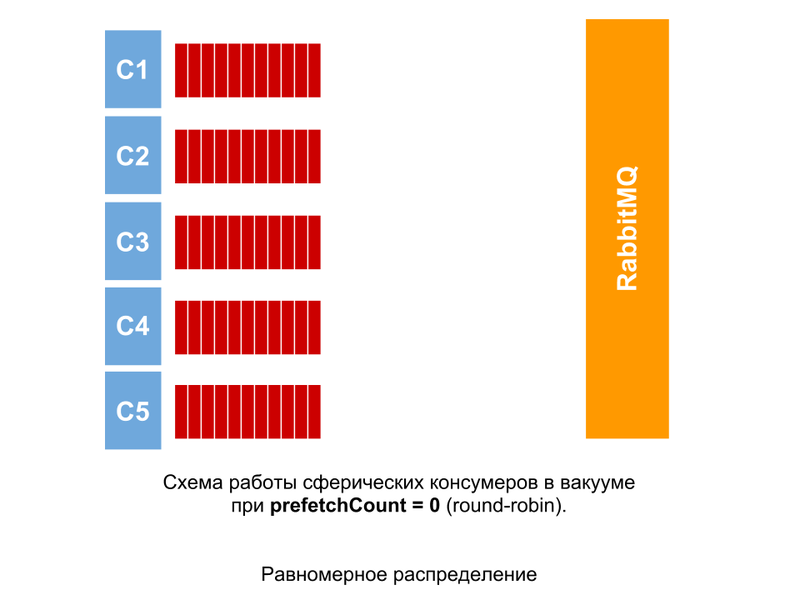
このような状況は、すべてのメッセージの処理にまったく同じ時間がかかった場合に観察される可能性があります。 prefetchCount = 0の場合、確認されていないメッセージの数に関係なく、メッセージはコンシューマに順番に配信されます。
等しいタスク
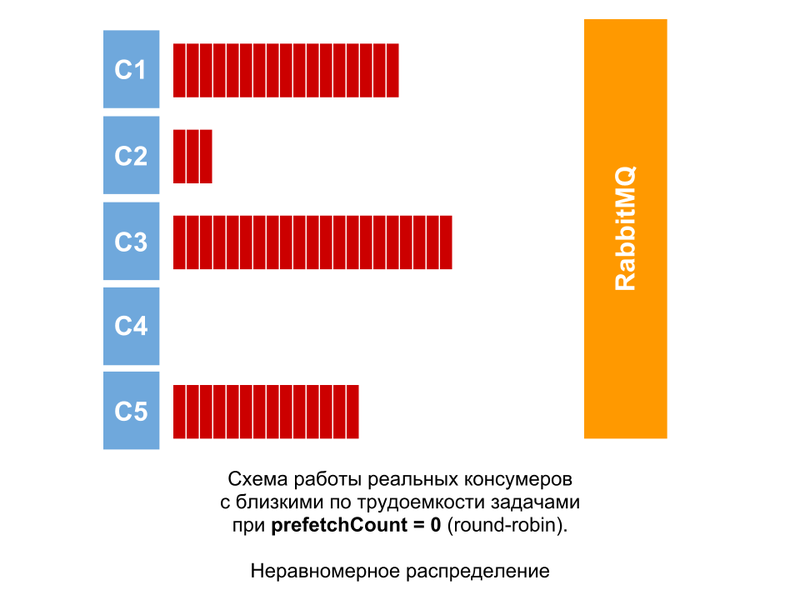
実際、タスクの複雑さは常に、少なくともわずかではありますが、常に異なります。 したがって、たとえそれらが等しい(非常に近い)場合でも、画像はほぼ同じになります。 消費者間で未確認のメッセージの数の差は、消費者全員がメッセージを処理できるとは限らないにしても大きくなります。
等しくないタスク

タスクの複雑さが大幅に異なる場合( たとえば、スプレッドがプロジェクトの数件の注文である場合) 、処理に時間がかかるメッセージを受信すると、未確認のメッセージの数が蓄積されます。 視覚的に(キューを監視)、メッセージがハングしているようです。 無料の消費者は新しいメッセージを即座に処理し、メッセージは忙しいメッセージに蓄積されます。 これらのメッセージは、処理中のコンシューマーへの接続が切断されない限り、処理のために他のコンシューマーに送信されません[図-C4] 。 また、この場合、無料の消費者にはかなりのダウンタイムがあります。
壮大な失敗

再起動
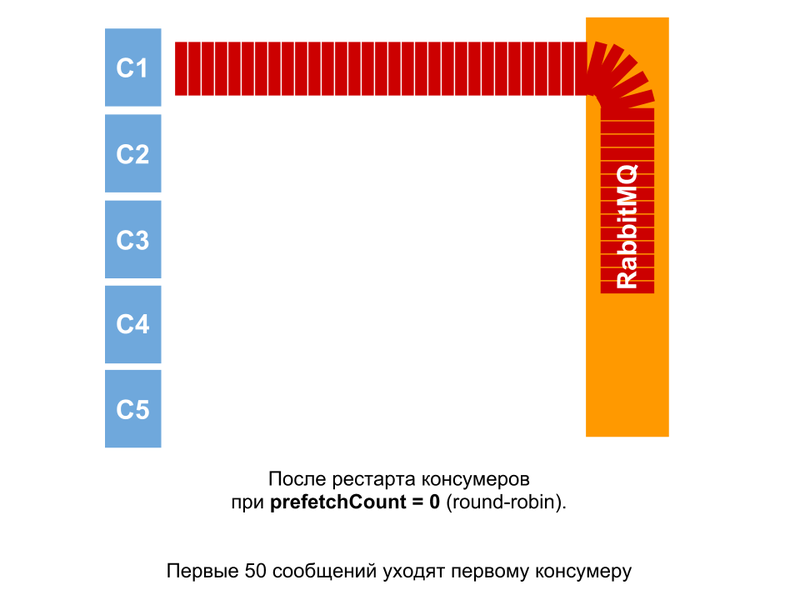
しかし、キューにメッセージがあり、コンシューマーが再起動される(または最初の起動のみ)場合、事態はさらに興味深いものになります。 消費者は一緒に開始しますが、とにかく最小の時間間隔で開始します。 したがって、最初のメッセージが開始されるとすぐに、メッセージのパケットをすぐに受信します(現時点ではまだ他のコンシューマが存在しないため)。 多数の実験により、50という数字が明らかになり、さらにメッセージは均等に配信されました。
メッセージがキューにある状況では、コンシューマーの開始時に、コンシューマーの1人がメッセージを受信します。 この後に別のメッセージが到着すると、同じ消費者に送信されます。 この理由は、ポインターのリセットである可能性があります。 最初のメッセージが処理のために送信されてから、コンシューマの数が変更されました。
公正な派遣
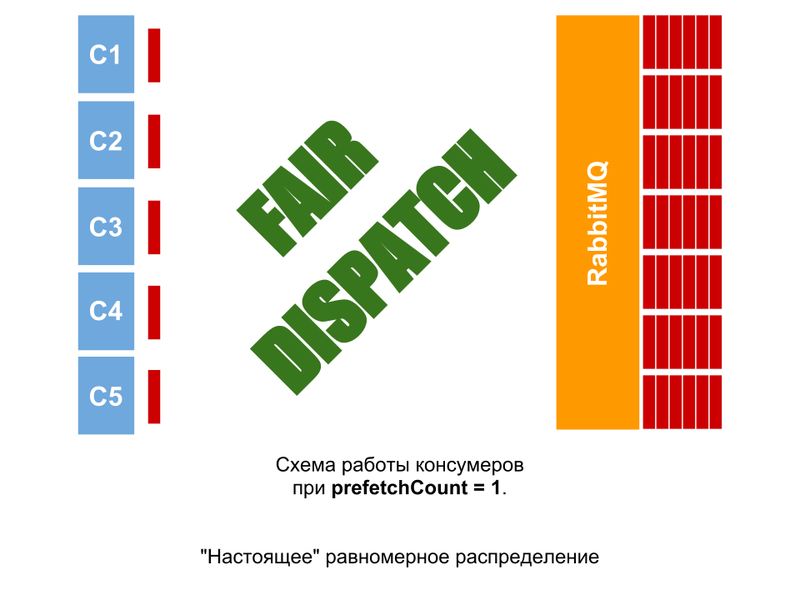
prefetchCount = nオプションを使用する場合( 例ではn = 1ですが、2、5、10など)、コンシューマは、前のメッセージを確認するまで次のnメッセージを受信しません。 したがって、タスクの複雑さの均一性に関係なく、均一なワークロードを取得できます。 キューにメッセージがある場合、状況はなく、一部のコンシューマーはアイドル状態です(アイドル状態の場合、キューのコンシューマーあたりのメッセージ数はn個以下になります)。
パフォーマンスRabbitMQ

しかし、それほど単純ではありません。 prefetchCountの値が低いほど、RabbitMQのパフォーマンスが低下します(値0は無限に対応し、チャートでは値10000に近くなります)。 このチャートは公式サイトからのものです 。
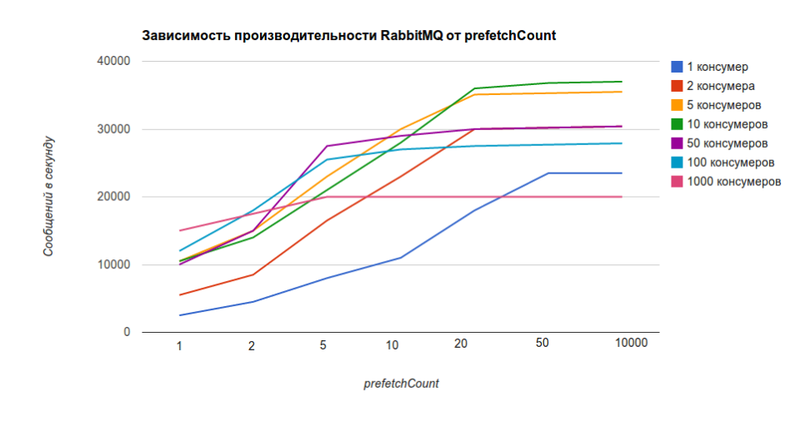
同じグラフ。prefetchCountの値にのみ依存し、コンシューマの数には依存しません。
prefetchCount = 1の 5つのコンシューマでは、 RabbitMQは1秒あたり1万メッセージを送信でき、 prefetchCount = 0-1秒あたり36kメッセージの3.6倍のメッセージを送信できます。
消費者パフォーマンス
しかし、ほとんどの場合のボトルネックはRabbitMQのパフォーマンスではなく、消費者のパフォーマンス(数桁低い)です。 テストプロジェクトでは、prefetchCountの値にそのような依存性がありました(むしろ、存在していません)(1秒間に1000メッセージ未満を処理する消費者にとっては、既に述べたように公平です)。

同時に、 [プロジェクトの]消費者数に対する生産性の依存性も同様であることが判明しましたが、消費者自身のリソース消費、サーバーのパフォーマンス、消費者が異なるサーバーに配置されているかどうかなどに大きく依存します。
結論

prefetchCount = 1の使用による最大損失は(最初のスライドの理想的な条件と比較して)0.03%です。 同時に、均一な分布とダウンタイムの減少により予想される時間の増加は約50..100%(1.5..2倍)になります。 prefetchCount = 0の実際のキューでは、メッセージの処理時間は多くの場合、残りのダウンタイムのために1人のコンシューマーが作業する時間になります(3番目のスライドのように)。 また、キューはより予測どおりに移動し、「フリーズ」の影響はありません。
[もちろん、他のプロジェクトでは、数字は異なります]
コメントでprefetchCountに関連するテストと観測の結果を共有することをお勧めします。