投稿のタイトルに適した写真を選択できますか?

その後、ロボットに教えてください! 彼もそれを望んでいます。
Open Enclosureプロジェクトチームは、habra-peopleに、自由にアクセス可能な(CC-BY-SA)テキストコーパスのマークアップを支援するよう依頼します。 カットの下で、私たちは軍団とは何か、なぜそれが必要なのか、ロシアと海外の軍団はどうなるのか、なぜそれが悪いのか、そして私たちの計画は何かについて話します。
テキストのコーパスは、テキスト、これらのテキストに関連するさまざまなメタデータ、およびそれらに含まれる単語と文の文法分析を含む言語データベースです。 メタデータと解析はマークアップです。 さまざまなレベルで発生します:形態学的、構文、セマンティックなど。 ラベル付きのテキスト本文がないと、テキスト分析用のソフトウェアを開発することは困難です(不可能ですらありません)。 機械学習を使用するプログラムの場合、トレーニングサンプルはラベル付きケースから取得されます。 それ以外の場合は、テストにケースが必要です。
世界の多くの言語でマークされたケースが存在します。 ほとんどの場合、テキストの本文は、さまざまな言語構造の使用例を選択できる専用の検索エンジンを介して利用できます。 これらのサービスは言語学者向けです。 そこからケース全体をダウンロードすることはできません。なぜなら、 それらに含まれるテキストはほとんどの場合著作権で保護されています。 言語ソフトウェアを開発するには、全体としてマークアップとともにダウンロードできるエンクロージャーが必要です。 Habréについては、 ここ(POSタグ付けについて)とここ(構文について )ですでに書いています 。
ロシアと海外のテキスト隊
ここでは、ロシア語は、たとえば英語ほどではありません。英語には、利用可能で手動でラベル付けされたテキストの隊がいくつかあります。 少なくともロシア人よりも英語を話す人が多いため、これは驚くことではありません。 驚くべきことに、 ロシア語の10分の1の人々が話すハンガリー語であっても、100万語以上のアクセス可能なマーク付きコーパスがあります。
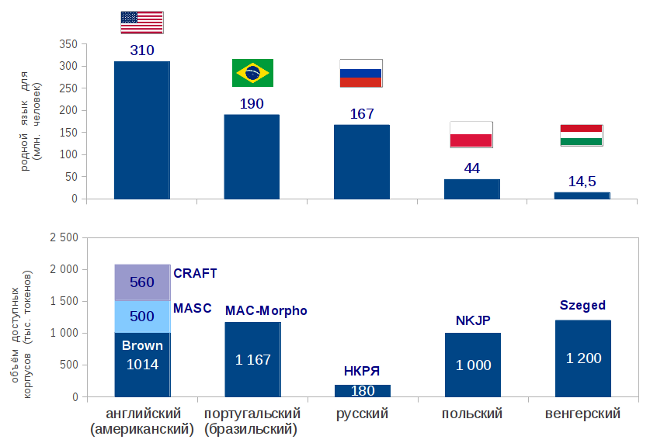
私たちはどうですか?
多くの組織(ロシア科学アカデミーロシア語研究所を含む)の共同の努力によって作成されたロシア語国立コーパス(NKRJ)は、コーパスの検索モードでのみ使用できます。 600万語の手でラベル付けされた単語のうち、 ダウンロードできるのは18万語のサンプルで 、文章が乱れている場合のみです。 あいまいさを排除した形態素解析ツールを作成する場合は、これらの18万個を使用する必要がありますが、これはほとんどの場合機械学習には不十分であるか、ポーランド語などの他の言語を試してください。 この状況は、明らかに、わが国のコンピューター言語学の発展には寄与していません。
ロシア語が「リソース不足の言語」に分類されないようにするために、NKRYやその他のプロジェクトの作成経験を考慮して、ロシア語の新しいオープン隊を作成することにしました。 National Corpsは優れた検索インターフェイスを提供し、さまざまな単語や構文の使用例の検索に関連する問題を解決するため、開発者向けの自由にアクセス可能なコーパスの作成に焦点を当てることにしました。ダウンロードして機械学習またはテストに使用できます。 検索はありませんが、怖くないわけではありません。 彼はNKRJにいます。 著作権の問題が配布に干渉しないように、Creative Commonsライセンスの下で利用可能なテキストまたはパブリックドメインにあるテキストのみが本文に含まれます。 マークアップは、CC-BY-SAの条件に基づいて作成されます。
作業の前段階(2011年)で、70万語のコーパスを組み立て、単語と文の境界を手動で設定しました。 このデータはすでにダウンロードできます 。 ここでの主な目標は、形態学的マークアップのあいまいさを取り除くことです。 この作業も手作業で行う必要があります。多くの作業がありますので、ご協力ください。
学校または形態学的マークアップとは何ですか
形態学的マークアップ(タグ付け、品詞タグ付け)は、語彙形式のテキスト内の各単語(「大」-「大」、「表」-「表」、「読」-「読」)と文法の指示の比較です。単語の特性:性別、数、ケース、時間など。主要な形態学的マークアップは、辞書に従って自動的に行われます。 目的に合わせて完成したAOTプロジェクト辞書を使用します。 ほとんどの単語では、マークアップはあいまいです。つまり、辞書のテキスト内の多くの単語には、いくつかの仮説があります。 多くの場合、仮説の1つだけが正しいです。 構文解析にはいくつかのオプションがあるあいまいな文があります。 例:
「これらの種類の鋼は店内にあります」
STEEL (名詞)またはARTICLE (動詞)?
「彼は自分の目で家族を見た」
FAMILY (名詞)またはFAMILY (数字)?
そのような例はまれです。 形態学的分析は、文の文脈で明確になります。文全体を読んだ後、この単語またはその単語がどのような形であるかを判断できます 。 たとえば、文「Mommy soap frame」の場合、最終的に次の分析を作成する必要があります。

辞書を使用して形態素解析を行った後、明確に解析できる単語は1つだけです。 「SOAP」および「FRAME」という単語に対して、それぞれ4つの仮説と2つの仮説が得られます。
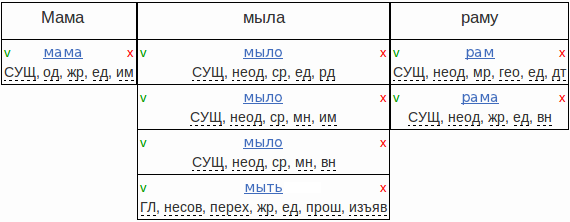
形態学的あいまいさを取り除くことは、各単語に対して1つの正しい仮説を選択することです。 ネイティブスピーカーにとって、これはほとんどの場合難しくありません。
計画があります!
曖昧性解消のタスクを簡素化するために、 それを単純な質問に分割しました 。これらの質問は 、曖昧性の各例の決定木を一緒に表します。 「SOAP」という単語の場合、最初の質問は「名詞または動詞?」です。 「ママはフレームを洗った」という文の場合、これは動詞であり、動詞の仮説は1つしかないため、曖昧性解消は終了します。 それ以外の場合は、もう1つ、最悪の場合はさらに2つの質問に答える必要があります。
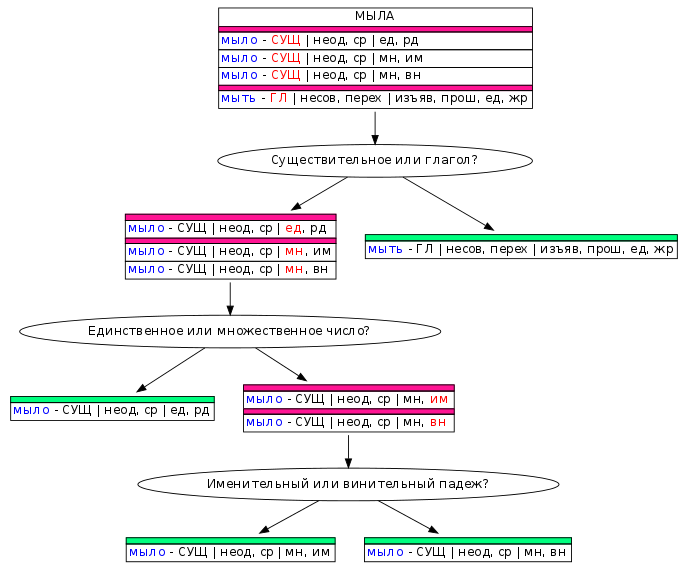
同じ種類の質問をグループにまとめました。 参加者は質問のタイプを選択し、コンテキスト内でランダムに選択された単語に関するこのタイプの質問のみに回答できるため、1つのタスクに集中できます。 マークアップを高速化 さまざまなタイプの質問を切り替えるのに時間を浪費する必要はありません。
マークアップを十分に正確にするために、 各質問は3人の異なる人々に尋ねられ 、回答が完全に同一であり、誰もコメントを書いていない場合にのみ、ダブルチェックなしで使用されます。 1つの回答が他の2つの回答と異なる場合、またはコメントが残っている場合、この例はモデレーターによってチェックされます。
この計画はいくつありますか?
概算によると、現在収集されているテキストのコレクションのあいまいさを解消するには、質問が3回尋ねられるという事実を考慮して、
プロジェクトに参加するには、先延ばしの攻撃、勤務時間(マークアップインターフェイスがスマートフォンで機能する)、およびその他の強制的な一時停止を有用なアクティビティで使用できます。 この意味で、ケースのレイアウトはソリティアに似ており、より便利です 。 特別な言語知識は必要ないので、この場所を読んだことがある人なら誰でも参加でき、一緒に軍団をマークするための形態学的レイヤーを作成します。 このページには、段階的なマークアップ手順が含まれています。
最近、私たちはすべての曖昧さがすでに取り除かれた提案のサブセットを収集して公開し始めました 。 このサブコーパスはまだ非常に小さく、約9,500語です。 マーキングが進むにつれてサイズが大きくなり、将来的には、これらのデータを使用して、明確に識別できる自由にアクセスできる形態素解析ツールを作成できます。
オープンハウジング。 明確に明確にしてください!
上記のケースへのリンク
ロシア語
[NKRYA]ロシア語国立軍団: ruscorpora.ru (このプロジェクトについての10月23日は、モスクワ工科大学の講堂での講義になります)
[OpenCorpora] Open Enclosureに関する記事とプレゼンテーション: opencorpora.org/?page=publications
英語
[Brown] Brownian Corps: en.wikipedia.org/wiki/Brown_Corpus
[MASC]手動で注釈を付けたサブコーパス(マニュアルでAmerican National Corpsとマーク): www.anc.org/MASC/Home.html
[CRAFT] Colorado Richly Annotated Full Text Corpus(言語的および存在論的マークアップ付きの67の生物医学記事): bionlp-corpora.sourceforge.net/CRAFT/index.shtml
ポルトガル語、ポーランド語、ハンガリー語
[MAC-Morpho]ブラジルのポルトガルのフォルハ・デ・サンパウロ新聞からのテキスト: www.nilc.icmc.usp.br/lacioweb/english/plancamento.htm
[NKJP] Narodowy KorpusJęzykaPolskiego。 NKJPサブエンクロージャー、GNU GPL v.3ライセンスで入手可能: nkjp.pl/index.php?page=14&lang=1
[セゲド]セゲドコーパス、ハンガリー語の本文: www.inf.u-szeged.hu/projectdirs/hlt/index_en.html
投稿の冒頭の写真: 「家族の肖像画」と「トーテムモスター」 。