飛行機のノード、たとえばエルロンを回すメカニズムを考えてみましょう。 それは一連の機械的および電子的コンポーネントで構成され、協調して動作し、目的のアクションを生み出します-補助翼を回します。 このメカニズムの信頼性は理論的に計算できます。そのためには、個々の要素の信頼性のみを知る必要があります。 これらの要素の1つが通常のねじであると仮定しますが、これは機構の動作にとって重要です-壊れると、補助翼は回転を停止します。 このネジの信頼性を判断する方法は? このようなネジのバッチを取り、一連の強度テストを実行して、統計値を決定し、この特定のネジがこのシリーズからあまり外れていないことを想定できます。 一般に、この仮定は実証されておらず、非常に危険です。 別の方法もあります。このネジを取り、原子ごとにスキャンし、すべての微視的欠陥と不規則性を考慮した量子力学モデルを構築します。 次に、巨大なスーパーコンピューターでこのモデルを計算した後、このネジが異なる負荷の下でどのように動作し、破損するかを確認します。 このアイデアは刺激的ですが、まったく意味がありません。 なぜなら、それらは風の突風、パイロットの行動、航空機の他の部分の機械的反応などの多くの要因に依存しているためです。 そして、これらすべての要因をシミュレートするには、パイロットを加えた平面全体と地球の大気全体をマトリックスに打ち込む必要があります。さらに、太陽の磁気disturbance乱と近隣の銀河での超新星爆発による重力波を考慮する必要があります。
エンジニアではなくプログラマーであり、予測可能なオブジェクトをはるかに扱っているのは良いことです。 原子スキャナーはまだ発明されていないだけでなく、物理学のすべての法則も知っているわけではありません。 物理的な織機とソフトウェアシステムの違いだと思います。 ソフトウェアシステムは、動作を理論的に予測できる要素で構成されています。 さらに、その動作は時間に依存しません-プログラムは摩耗しません。
この例を考えてみましょう。 .Net Frameworkでは、StringオブジェクトにSubstringメソッドがあります。
public string Substring(int startIndex)
このメソッドは、 startIndexの位置から文字列の末尾で終わる部分文字列を返します。 ファイル名の最後の3文字を返すメソッドが必要であり、次のコードを記述したとします。
static string Extension(string name) { return name.Substring(name.Length-3); }
このコードは良いですか? はい、彼は必要なことを行います-最後の3文字を返します。 また、正常に機能しますが、長さが3文字より短いファイル名が入力されるまでは。 そして、最も適切でない瞬間にArgumentOutOfRangeException型の例外が発生します。
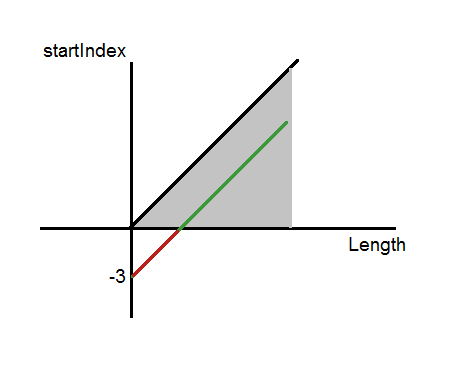
どうした そして、起こったのは、Substringメソッドにスコープがあり、違反があったことです。 startIndex引数は、[0、 Length ]の範囲の値を取ることができます。ここで、 Lengthは文字列の長さです。 X軸が文字列の長さで、Y軸が最初のインデックスである2次元座標系を取得すると、右上の4分の1に三角形の領域が得られ、無限になります。 ここで、実装のSubstringメソッドに渡すことができる値のセットを示します。 このセットは、式startIndex = Length -3で記述されます。ラインの通常の式。 Length = 0の場合、 startIndex = -3、 Length = 3の場合、 startIndex =0 。プログラムクラッシュの原因がグラフに明確に表示されます。可能な入力値の範囲がメソッド定義の範囲を超えています。
間違いを見つけました。 修正方法 取得するもの、つまり、このExtensionメソッドの要件に依存します。 Substringを呼び出す前に条件を挿入できます
If(name.Length < 3) return String.Empty;
または、次のようにメソッドを書き換えます。
static string Extension(string name) { int index = name.Length - 3; if (index < 0) index = 0; return name.Substring(index); }
これらの実装の動作は異なりますが、どちらの場合も、可能な引数値はすべてSubstringメソッドのスコープ内にあります。
拡張メソッドに別のバグがあることに気づいたと思います。 引数名にnullを渡すことができるため、痛々しいほどよく知られているNullReferenceExceptionが発生します。 次の例では、このタイプのバグを検討します。
例は実際の練習から取られます。 タイプEntityのオブジェクトをタイプDTOのオブジェクトに変換し、ビジネスロジックのレベルをデータアクセスのレベルから分離するのに役立つ非常に簡単なメソッドがあります。
static ProductDto Translate(ProductEntity e) { return new ProductDto() { Name = e.Name, Code = e.Code, Description = e.Description }; }
引数eをポインターと見なす場合、nullとオブジェクトへの参照の2つの値のみを取ることができます。 そして、これら2つの値のうち、最後のメソッドのみがTranslateメソッドのスコープ内にあります。 そして、プログラムのどこかでこのメソッドが引数nullで呼び出されると、それは落ちます。
ただし、現在、Substringメソッドとは異なり、その実装は利用可能です。 メソッドの先頭に次の行を追加して、このスコープを拡張しないのはなぜですか。
if (e == null) return null;
これで、メソッドのスコープには引数eの両方の可能な値が含まれ、どのような状況でもこのメソッドが機能することが保証されます。
ただし、壊れたポインターにぶつかった経験豊富なプログラマーは、このような実装が他のエラー、おそらくはより深刻なエラーを単純にマスクすることに反対するかもしれません。 実際、Translateメソッドの入力にnullが含まれる理由は何ですか? おそらく、このnullを呼び出しチェーンに静かに渡すのではなく、例外をスローする必要がありますか? 異議は非常に合理的であるため、より一般的なコンテキストでこの方法を検討する価値があります。
このメソッドは、データベースからオブジェクトのリストを取得し、それをUIにマップするプログラムの一部であるとします。 同時に、左側に短い名前のリストが表示され、ユーザーは項目を選択できます。その結果、オブジェクトに関する詳細情報が右側に表示されます。 そして、詳細情報を取得するときだけ、Translateメソッドが使用されます。オブジェクトの識別子はDBブロックのプロシージャに転送され、このプロシージャはクエリを実行し、結果をオブジェクトにパックしてTranslateメソッドに渡します。
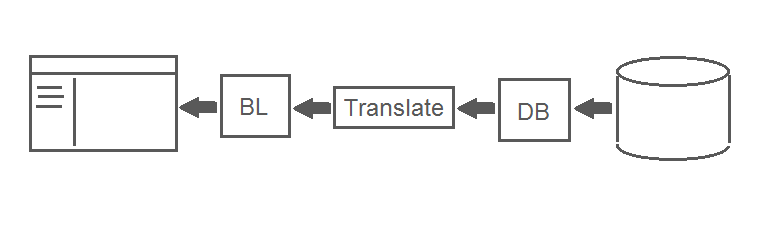
これにより、2番目の質問が発生します。渡された識別子を持つオブジェクトがデータベースに存在しない場合、DBブロックでプロシージャは何をする必要がありますか? nullを返す必要がありますか? いいえ、このためです。
短い名前と詳細情報のリストは論理的に関連しており、合意されたデータセットに基づいて形成される必要があるため、要求された識別子を持つオブジェクトが存在しないことはデータの不整合を示していることは明らかです)、または短い名前のリストを形成するコードのどこかにエラーがあります。 別の理由は次のようになります:短い名前のリストが表示された後、システムの他のユーザーがデータベースからオブジェクトの1つを削除した後、最初のユーザーがこのオブジェクトを選択して詳細情報を表示しました。 ここでは、ロックメカニズムがないことが理由ですが、これらのすべてのケースで、要求されたオブジェクトが存在しないことは、より高いレベルのエラーを示しています。 したがって、DBブロック内のプロシージャに対する最も合理的なアクションは、最大の情報を渡すことができる例外をスローすることです:実行されたクエリ、データベースなど。 この情報はすべて、アプリケーションをさらにデバッグするために非常に重要であり、データアクセスレベルでのみ使用できます。
さて、データアクセスレベルがわかりました。 ただし、nullを取得するときにTranslateプロシージャが何をすべきかという問題は未解決のままです。 データアクセスレベルが正しく実装されている場合、そこからnullが返されることはなく、引数をチェックして例外をスローする必要はありません。 つまり、このコンテキストでは、引数の値はメソッド定義の範囲内にあると確信しています。 したがって、通常、メソッドは元の形式のままにしておくことができます。引数を確認したり、例外をスローしたりする必要はありません。 しかし。 常により広いコンテキストがあります。
第一に、多かれ少なかれ複雑なソフトウェアシステムは常に個人ではなく、チームによって開発されます。チームはその構成が時間とともに変化する可能性があります。 次に、システム自体の機能が継続的に開発されています。 これは、変数の意味的負荷が変化するまったく異なるコンテキストで同じメソッドが使用され始めるという事実につながります。
上記のコンテキストの翻訳入力でのヌルの到着は何を証明していますか? 明らかに、どこかが壊れました。 つまり、このコンテキストのnull値は「どこかで壊れた」という意味になります。 ただし、別のコンテキストは非常に可能です。
ここで、データベース内のオブジェクトを一意のコード名で検索するためのユーザーインターフェイスを作成する必要があるとします。 ゼロまたは1つのレコードを返すSQLクエリが記述されます。 新しいメソッドがDBブロックに書き込まれます。これにより、見つかったオブジェクトまたはnullが返されます。 この場合、ユーザーが入力したオブジェクトコードが正しくない可能性があるため、nullは論理的な結果です。この場合、ユーザーフレンドリメッセージ「オブジェクトが見つかりません」がUIに表示されます。 つまり、このコンテキストでは、nullはまったく異なる意味を意味します。 そして、このコンテキストで既製のTranslateメソッドを使用しようとするとどうなりますか? 質問は修辞的です...
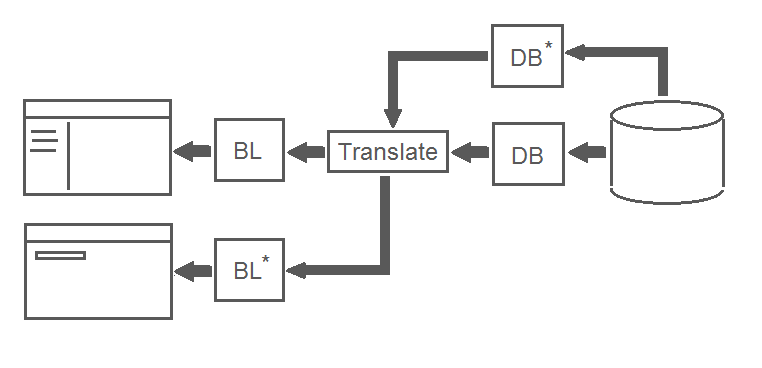
したがって、Translateメソッドが両方のコンテキストで確実に機能するようにするには、次の行を追加して、スコープをできる限り広くする必要があります。
if (e == null) return null;
メソッドの先頭まで。 実際、最初のコンテキストでは、データアクセスレベルはnullを返すことができません。2番目のコンテキストでは、nullは完全に有効な値です。
一般的な場合、他のどのコンテキストでメソッドを使用できるかがわからない場合、その定義の範囲をできるだけ広くする必要があります。
理論的には、Translateメソッドが例外をスローする必要がある別のコンテキストを考えることができます。 たとえば、データアクセスレベルがサードパーティライブラリにあり、不正に実装されている場合、例外をスローする必要があるときにnullを返します。 この場合、このメソッドの要件が互いに矛盾するため、Translateメソッドを3つのコンテキストで同時に使用することはできません。2番目のコンテキストでは、nullを出力に渡す必要があり、3番目のコンテキストでは例外がスローされ、最初のコンテキストでは問題になりません。 したがって、この状況では、メソッドの2つの異なる実装を記述する必要があります(または、より美しく、メソッドを仮想化し、オーバーロードにします)。
継続する。