
ベイズの定理は、少なくとも最も基本的な確率論のコースを取ったことのある人なら誰でも覚えているか、ささいな推論である。 条件付き確率とは何かを覚えておいてください。
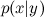 イベントx提供されたイベントy ? 定義により:
イベントx提供されたイベントy ? 定義により: 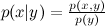 どこで
どこで 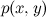 xとyの結合確率であり、 p ( x )とp ( y )は各イベントの確率です。 したがって、結合確率は次の2つの方法で表現できます。
xとyの結合確率であり、 p ( x )とp ( y )は各イベントの確率です。 したがって、結合確率は次の2つの方法で表現できます。
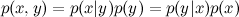 。
。
さて、ここにベイズの定理があります:

あなたはおそらくあなたをm笑していると思う-条件付き確率の定義の自明なトートロジーの書き換えは、特に機械学習のような大きくて自明ではない科学のようなものの主なツールになることができますか? ただし、理解を始めましょう。 最初に、単純にベイズの定理を他の表記法で書き直します(はい、私はモックを続けます):
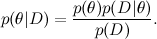
次に、これを典型的な機械学習タスクに関連付けましょう。 ここで、Dはデータ、私たちが知っていること、θはトレーニングしたいモデルパラメーターです。 たとえば、SVDモデルでは、データはユーザーが製品に付けた評価であり、モデルパラメーターはユーザーと製品に対してトレーニングする要因です。
各確率には独自の意味もあります。
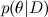 -これは、データを考慮した後のモデルパラメーターの確率分布である、見つけたいものです。 これは事後確率と呼ばれます。 原則として、この確率は直接見つけることができず、ここではベイズの定理が必要です。
-これは、データを考慮した後のモデルパラメーターの確率分布である、見つけたいものです。 これは事後確率と呼ばれます。 原則として、この確率は直接見つけることができず、ここではベイズの定理が必要です。 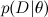 -これは、いわゆる尤度 (尤度)であり、モデルパラメーターが固定されている場合のデータの確率です。 これは通常、簡単に見つけることができます。実際、モデルの設計は通常、尤度関数を設定することにあります。 A
-これは、いわゆる尤度 (尤度)であり、モデルパラメーターが固定されている場合のデータの確率です。 これは通常、簡単に見つけることができます。実際、モデルの設計は通常、尤度関数を設定することにあります。 A 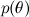 -事前確率、オブジェクトに関する直感の数学的形式化、実験前であっても以前に知っていたことの形式化。
-事前確率、オブジェクトに関する直感の数学的形式化、実験前であっても以前に知っていたことの形式化。
ここではおそらく、これを掘り下げる時間と場所はありませんが、トーマス・ベイズ牧師のメリットは、もちろん、条件付き確率の定義を2行で書き直すことではなく(そのような定義はありませんでした)、提唱することでしたそして、確率の概念そのもののこの見解を発展させます。 今日、「ベイジアンアプローチ」とは、フリークベンティスト(「フリーク」ではなく「頻度」という言葉から)ではなく、「信頼度」の観点から確率を考慮することを指します。 特に、これにより、1回限りのイベントの確率について話すことができます。実際、「ロシアは2018年に世界のサッカーチャンピオンになる」などのイベントや「Vasyaは映画が好きになる」などのイベントには「無限に向かう実験の数」がないためです。トラクタードライバー「」; それは恐竜のようなものです。好むと好まざるとにかかわらず。 しかし、数学はもちろん、どこでも同じです。コルモゴロフの公理は、彼らが彼らについてどう思うかを気にしません。
過去を統合する-簡単な例。 テキストを分類するタスクを考えてみましょう。たとえば、スポーツ、経済、文化などの既存のトピックデータベースに基づいて、トピック別にニュースフローをソートしようとしているとしましょう。いわゆる「バッグオブワードモデル」を使用します。それに含まれる言葉。 その結果、各テストケースxは一連のカテゴリVから値を取得し、属性によって記述されます
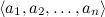 。 この属性の最も可能性の高い値を見つける必要があります。
。 この属性の最も可能性の高い値を見つける必要があります。
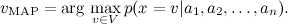
ベイズの定理により、
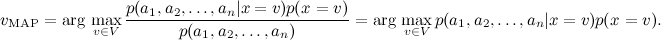
レート
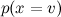 easy:発生頻度を単純に評価します。 しかし、異なることに感謝します
easy:発生頻度を単純に評価します。 しかし、異なることに感謝します 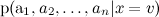 動作しません-それらが多すぎる、 -これは、さまざまなトピックのメッセージ内のこのような単語セットの正確性の確率です。 明らかに、そのような統計を取得する場所はありません。
動作しません-それらが多すぎる、 -これは、さまざまなトピックのメッセージ内のこのような単語セットの正確性の確率です。 明らかに、そのような統計を取得する場所はありません。
これに対処するために、単純ベイズ分類器(単純ベイズ分類器-馬鹿のベイズとも呼ばれます)は、目的関数の値が与えられた場合、属性の条件付き独立性を仮定します。
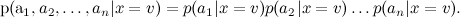
今、個人を訓練する
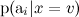 はるかに簡単です:カテゴリ内の単語の出現に関する統計を計算するだけで十分です(ナイーブベイの2つの異なるバリアントにつながる詳細がもう1つありますが、ここでは詳しく説明しません)。
はるかに簡単です:カテゴリ内の単語の出現に関する統計を計算するだけで十分です(ナイーブベイの2つの異なるバリアントにつながる詳細がもう1つありますが、ここでは詳しく説明しません)。
単純ベイズ分類器は、非常に強い仮定を立てていることに注意してください。テキストの分類では、同じトピックのテキスト内の異なる単語が互いに独立して現れると仮定します。 もちろん、これはまったくナンセンスです-しかし、それでも結果はかなりまともです。 実際、単純なベイズ分類器は見かけよりもはるかに優れています。 もちろん、彼の確率の推定は、真の独立の場合にのみ最適です。 しかし、分類器自体は、はるかに広範なクラスの問題に最適であり、その理由は次のとおりです。 まず、属性はもちろん依存していますが、依存関係は異なるクラスで同じであり、確率を評価する際に「相互に減少」します。 単語間の文法的および意味的な依存関係は、サッカーに関するテキストとベイジアントレーニングに関するテキストで同じです。 第二に、確率を評価するために、単純ベイズは非常に悪いですが、分類器としてははるかに優れています(通常、実際に
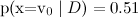 そして
そして 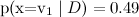 ナイーブベイズは配る
ナイーブベイズは配る 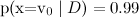 そして
そして 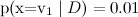 、しかし、分類はより頻繁に正しいでしょう)。
、しかし、分類はより頻繁に正しいでしょう)。
次のシリーズでは、この例を複雑にし、マークされたドキュメントのセットなしでドキュメント本文のトピックを強調表示できるLDAモデルを検討します。これにより、1つのドキュメントに複数のトピックを含めることができ、推奨タスクにも適用できます。