私は、ほとんどのプログラマと同様に、新しい構造とアルゴリズムを時々学びます。
今回は、キャッシュ忘却アルゴリズムに関する記事に出会いました。 これらは、最新のプロセッサのキャッシングサブシステムで動作するように最初に最適化されたアルゴリズムです。
このグループの代表者の1人は、Unrolledリンクリストです。
これは何?
それが何で何が食べられるのかを理解するために、最も人気のあるリストの実装を思い出すことをお勧めします。ArrayList(リスト自体ではなく配列について簡単に説明します)とLinkedListです。
主な利点と欠点を考慮してください。
ArrayList :
長所
- コンパクトさ-配列は、リストを表すための最も(少なくとも1つの)コンパクトなデータ構造です。
- 埋められていない配列の終わりでの挿入速度-操作は非常に高速です!
- インデックスによる要素の取得速度も非常に速く、キャッシュミスの数はN / Bで推定できます。ここで、Bはキャッシュラインのサイズ、Nは配列内の要素の数です。これはこの種の構造の参照と見なすことができます。
短所
- 真ん中に挿入することは配列にとって非常に便利な操作ではありません。右側をシフトする必要がありますが、arraycopyを使用してもまだ自由ではありません。
- メモリ領域の長さ-大きな配列を格納するには、大きな連続したメモリが必要です。 また、多くのガベージコレクターはメモリの断片化を効果的に処理しますが、特に大きなリストの場合、OutOfMemmoryの可能性は非常に高くなります。
LinkedList :
長所
- 比較的簡単で高速な中間挿入操作。
- 非常に断片化されたメモリを使用する場合、問題はありません。
短所
- 同じサイズのデータを保存するために必要なメモリが大幅に大きい(最大4回)。
- リストを反復処理する場合、最悪の場合のキャッシュミスの数は、リストノードの数と等しくなります。 最良の場合でも、すべてのノードが次々にメモリ内にある場合、ノードのサイズが大きいため、キャッシュミスの数はArrayListの数の数倍になります。
そのため、UnrolledLinkedListは2つのリストのメリットを組み合わせて、それらの弱点を継承しようとはしていません。
このリストのデバイスをより詳細に検討してください。
簡単に言えば、UnrolledLinkedListは、長さnの配列の接続(二重接続)リストです。 つまり、各ノードには1つの値ではなく、値の配列が含まれます。 同時に、配列は十分に小さいため、挿入および削除操作は非常に高速であり、メモリフラグメンテーションはノードを作成する能力にあまり影響しませんが、キャッシュミスの数を減らすためにキャッシュラインに完全に収まるに十分な大きさです。 さらに、各ノードには、追加された要素の数が格納されます。 グラフィカルに、このリストは次のように表すことができます。
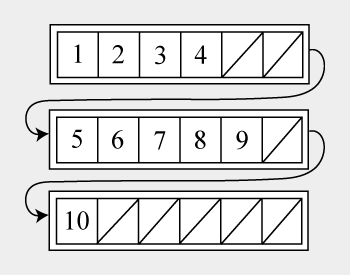
このリストの操作を検討してください。
ノードに挿入します。
空きセルがある場合、新しい要素は単に配列の最後に追加されます。 配列がすでにいっぱいになっている場合、現在のノードの後ろに新しいノードを作成し、配列の右半分をそこに転送して、新しい値を挿入する場所を作成します。 この場合、新しい要素は新しいノードの最後に挿入されます。 同じことを配列の中央の挿入にも適用できます。
グラフィカルに、この操作は次のように表すことができます。
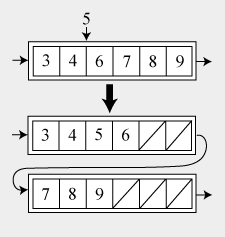
ノードからの削除:
操作は非常に簡単です。必要な要素を配列から削除し、必要に応じて残りの要素をシフトします。 ただし、1つありますが、配列の要素数がn / 2に減ると、n / 2の要素が隣接セルから転送されます。 この後、セルの1つが空の場合、削除されます。 この操作は、大きなリストを徐々に消去しながらメモリ消費を削減するために必要です。
インデックスでノードを検索:
リンクリストの場合と同様に、検索は先頭または末尾から始まり、より近いところから始まります。違いは、配列を反復処理する必要がないことです。ノードの要素数を含むフィールドの値を合計するだけです。 したがって、必要なノードの検索はLinkedListよりもはるかに高速になりますが、ここでの漸近的な動作はまだO(N)です。
最初は、各ノードの空のセルの半分が無駄すぎるように思えました。 ただし、小規模な実験で示されるように、平均して、セルの充填レベルは70%のレベルであり、50%の充填でも、メモリ消費量はリンクリストの消費量よりも大幅に少ないはずです。 さらに、このリストを使用すると、さまざまなニーズに合わせてカスタマイズできます。 アレイのフィルファクターを試してみましたが、大きなメリットは得られなかったため、すべてをそのままにしました。
キャッシュミスの数と言えば、そのようなリストの繰り返しは(N / n + 1)(n / B)として推定できます。ここで、Nはリストの長さ、nはノード配列の長さ、Bはキャッシュラインの長さです。 この見積もりは、ArrayListの見積もりに非常に近いものです。
執筆時点では、このようなリストは、1つのノードのみをロックする機能を備えた並行コレクションのかなり効果的な実装になり得るという考えもありました。 ただし、これは新しい研究と新しい記事のトピックです。
ソースはgithubに投稿されます。
これらはやや粗雑なコードですので、品質のために激しくキックしないでください。 しかし、いずれにせよ、私はどんな批判にも感謝します。
ソースにはさまざまなリストを測定して比較するいくつかの試みがありますが、すべての測定が正しく行われたかどうかわからず、足元を撃たなかったため、記事でそれらを提示することを恥ずかしく思います。 リスト上にポイントを最終的に配置するためのベンチマークの専門家の助けに非常に満足しています!
ご清聴ありがとうございました。
ソース:
blogs.msdn.com/b/devdev/archive/2005/08/22/454887.aspx
en.wikipedia.org/wiki/Unrolled_linked_list
UPD:パフォーマンスとサイズの測定値に到達しました。 マイクロベンチマークには、google-tool caliperを使用しました。
結果は次のとおりです。
線形反復
長さベンチマークus線形ランタイム
1000 UnrolledListIteration 6.34 =
1000 ArrayListIteration 5.56 =
1000 LinkedListIteration 5.93 =
100000 UnrolledListIteration 827.68 ==
100000 ArrayListIteration 637.05 =
100000 LinkedListIteration 1124.38 ==
1000000 UnrolledListIteration 9056.77 ========================
1000000 ArrayListIteration 6731.73 ===================
1,000,000 LinkedListIteration 11800.96 ===============================
ランダムアクセス:
長さベンチマークus線形ランタイム
1000 UnrolledListIteration 6.34 =
1000 ArrayListIteration 5.53 =
1000 LinkedListIteration 5.97 =
100000 UnrolledListIteration 844.30 ==
100000 ArrayListIteration 652.21 =
100000 LinkedListIteration 1106.90 ===
1000000 UnrolledListIteration 9066.88 ===========================
1000000 ArrayListIteration 6723.21 ====================
1,000,000 LinkedListIteration 10,339.15 ===============================
サイズ:
ArrayListの平均サイズは45172432,000バイトです//正直な結果ではありませんが、メモリ消費が徐々に増加することを示しています。
長さ1KKのArrayListの平均サイズは24000064,000バイトです
UnrolledListのビットの平均サイズは26250048,000バイトです
LinkedListのビットの平均サイズは56000048,000バイトです
これらは理論と一致する結果です)
リポジトリが更新されました。更新に精通したり、テストを実行したい人は誰でも歓迎します。