今、私たちは別の角度からそれを見ます。 私が言ったように、このタスクはさまざまな面で発生します。 同時に、「弱いAI」のエンジニアがAIタスクを理解する現在の傾向にどれほど深く誤解されているかを確認します。 残念ながら、現在、この分野の教育は悲惨な形式の作成を奨励しており、AIに目を向けています。 この種の教育の「流産」の1つについては、前の記事で説明しました。 しかし、そのような人々はたくさんあり、そのような「教育を受けた学生」を「スタンプ」する傾向は迷惑です。
適応のタスクの本質
ここで、基本をもう一度説明します。 それらは、L。A. Rastriginの「複雑なシステムの適応」によるモノグラフから取られています。
生物学者と社会学者を完全に満足させる新しい条件への適応としての適応の概念の明確化は、エンジニアの観点からは完全に不満足です。
適応の概念は、2つのタイプに分けることができます(実際、両方のタイプの適応が同時に出会い、相互に作用します)。
受動的適応 -固定環境への適応。 適応システムは、所定の環境でその機能を最良の方法で実行するように機能します。つまり、所定の環境で機能する有効性の基準を最大化します。 受動的適応の例は、植物で観察できます。
アクティブな適応 -このシステムに適した環境の検索。 これは、パフォーマンス基準を最大化するための環境の変更、または望ましい快適さを達成できるような環境の積極的な検索を意味します。 積極的な適応の例は、動物で観察できます。
注目すべきことは、彼が数学的に主題の概念を導入したという点で、他の誰もがいわば客観的なタスクだけを話すという点で、ラストリギンの仕事です。 そして、それに応じて、彼らは主題の数学的概念を持っていないので-したがって、これらすべての理論はAIから遠く離れています。 より正確には、主題の数学的概念が欠如しているため、弱いAIの枠組み内でのみ話すことができます。 さらに悪いことに、AIの主題の哲学的、心理的概念を持つことは、「強力なAIのオラクル」の問題です。
私たちの目的のために、主題が数学的に何であるかを理解する必要はありません。 主なことは、そのような概念があり、次のことに適用できるさまざまなレベルの適応を区別できることです:(1)制御目標の定式化、(2)制御オブジェクトの定義、(3)構造モデル合成(4)パラメトリックモデル合成
AI科学の現状は、モデルのパラメトリック合成のみを自動的に実行できるという事実にあり、したがって、パラメトリック適応のみが自動的に発生します。
最初の2つのレベル(管理の目標と管理の対象の決定)については説明しません。 これを行う方法についての詳細な理解すらありません。 少なくとも構造的適応とパラメトリック適応の違いを考慮するだけで十分です。
パラメトリックおよび構造適応
パラメトリック適応は、モデルパラメーターの修正、調整に関連付けられています。 この種の適応の必要性は、制御対象の特性のドリフトにより発生します。 適応により、各制御ステップでモデルを調整できます。モデルの初期情報は、オブジェクトとモデルの応答の不一致であり、その排除により適応プロセスが実装されます。
目標が達成されるだけでなく、モデルが洗練される適応管理は、デュアルと呼ばれます。 ここでは、管理の特別な組織を通じて、モデルの管理と適応という2つの目標が即座に達成されます。
人工ニューラルネットワークを使用してフィットネス関数を設定する方法と理由を理解したとき、「2人以上の教師」の問題の概要とAIコミュニティの主観的な意見で話したのは、まさにこの種の適応についてでした 。
構造適応の違いは何ですか?
モデルFは、構造とパラメーターで構成されます:F = ‹St、C›、ここでStはモデルFの構造、C =(C_1、...、C_k)はそのパラメーターです。
パラメーターを修正してモデルを常に適応させることとはほど遠いため、オブジェクトの適切なモデルを取得できます。 モデルの構造とオブジェクトの構造が一致しないと、不十分になります。 オブジェクトの進化の過程でその構造が変化すると、この状況は絶えず発生します。
主観的な例の苦い薬
現代のAIエンジニアは、構造適応を自分で実行するように教えられています。 車のために仕事をします。 さらに、これは、彼らが何をしているのかさえ理解していないような自己犠牲と自己愛で起こります。 ここでキャッチできる特徴的なフレーズ(lulza)は次のとおりです。
1. あなたの問題を解決するには、彼以外に何も必要ありません。
2. 1つのニューロンがこのタスクに対処する場合、なぜ隠しレイヤーが必要なのですか?
3. 「ユニバーサルソルバー」の代わりに、問題を解決し、それらに適したツールを選択できます。
私たちは古典的な始まりを持っています-人は構造適応の必要性のタスクを理解していません。 彼の知識の助けを借りて、彼は「モデルの構造の合成」の問題を解決しようとしています。 同時に、彼はこの機械を教える必要性を拒否します。 そして、それはすべて魅惑的に終了します-彼は自分が「賢い」と宣言し、残りは「適切なツール」を選択する方法を知っているという理由だけで「だまします」と宣言します。
いいえ、これは「ツールの選択」ではありません。残念なことに、これらは開発をやめ、機械のために何をするのかという知的タスクを見ない現代のAIエンジニアの現在の信条です。 これらはAIエンジニアであり、私たちのピラミッドの階段を押し進め、他の人がピラミッドの最上部にあるガゼボに向かわないようにすることだけを誇りに思っています。
そのようなAIエンジニアに対する私の個人的な態度は、強力なAIのオラクルとまったく同じであり、強力なAIのオラクルがそのような種類のAIエンジニアを大いに批判するとき、私を幸せにすることさえあります。 彼らは自分が何をしているのか、そしてAIの専門家としての彼らの仕事が何であるかを知らないからです。
「純粋な一般化」について少し
ローゼンブラットは、 純粋な一般化の概念を定式化した :
モデルにはN個の異なる刺激が提示されており、異なる方法でそれらに反応する必要があります。 最初に、特定の一連の画像がモデルに提示されるトレーニングが行われます。これには、区別される各クラスの代表者が含まれます。 次に、制御刺激が提示され、このクラスの刺激に対する正しい応答を取得する確率が決定されます。
制御刺激がトレーニング刺激のいずれとも一致しない場合、実験は「純粋な区別」だけでなく、「一般化」の要素も含みます。 制御刺激が、同じクラスの以前に提示された刺激によって活性化された要素とは完全に異なる感覚要素の特定のセットを興奮させる場合、実験は「純粋な一般化」の調査です。
なぜ今、これらのタスクは、弱いAIの代表者ではなく、強いAIの代表者によっても解決されないのですか? 答えは一つだけです。前者はそのような実験の本質を理解しておらず、後者はそのような実験の重要性を理解していません。 そして最後に時間をマークしています。
このセクションでは、「2人以上の教師」の問題の概要とAIコミュニティの主観的な意見の記事の追加の問題をどのように解決したかを見てみましょう。
256の出力があり、トレーニングサンプルが可能なバリエーションの半分に過ぎないことを示すと、次のようになります。
*次の状況に違反しています: 識別される各クラスの代表者を含む特定の画像シーケンスがモデルに提示されるトレーニングが実施されます
*パーセプトロンは、奇数がどのように取得されるかのみを示しました。 彼は自然界に偶数が存在することを知りませんでした。 偶数へのトレーニング後の重みはゼロでした。 それが、そのような予後不良がある理由です。 しかし、それでも、パーセプトロンは、偶数の存在を知ることができなかったという事実にもかかわらず、いくらかの予測をしました。 彼は、バイナリ表現の用語の形式に基づいてのみ、分類せずに試しました-少なくともいくつかの奇数を知るために偶数があったはずの場所で、それが偶数に近いように。 実際、彼は「単純な」クラスタリングを実行しました。
*したがって、 erererがMLP + BackPropアルゴリズムで行った予測結果の比較は、ここでは関係ありません。
*つまり パーセプトロンは「一般化」要素の問題として問題を解決しましたが、MLP + BackPropは問題についてあまりにも多くを知っていました-近似問題を解決しました。 しかし、パーセプトロンにはそのような構造的知識は与えられませんでした( 構造的適応を覚えていますか?) そして実際、パーセプトロンは単にここで物理的に一般化することができませんでした。
問題の状態を少し変える
次のステップで問題の条件をわずかに変更して、パーセプトロンに一般化の根拠があるようにしてみましょう。 まず、タスクの次元を64x64から32x32に減らします。これは結論に影響しませんが、すぐに計算されます。
これで、関数はc = a + bではなくなります。c= a + bには、上記の機能が存在します。奇数から学習したため、偶数の存在を推測する方法はありません。
次に、整数に丸めて関数c =(int)(a + b)/ 4を使用します。 視覚的には、このように見えます(今回のタスクを緑のグラデーションで区別するため):

(左側がフル機能、右側がパーセプトロンのトレーニングポイント)
次に、調査中の関数c =(int)(a + b)/ 4が予測にどのように寄与するかを分析しましょう。 各クラスの画像の例(数値cの値)が多いほど、予測が良くなることは明らかです。 これは、次のボックスに表示できます。

青い四角は、パーセプトロンが何も知らず、それを予測する必要がある点です。 しかし、彼の隣には緑が知られ、緑が明るいほど、彼が知っている例が多くなります。 極端なコーナーでは1つのポイントのみが知られており、中央の対角線には62の例があります。 したがって、パーセプトロンがこの関数を均一に一般化することを期待する必要はありません。 予測の質は、予測される関数の種類によって異なります。
そして、次のようになります。
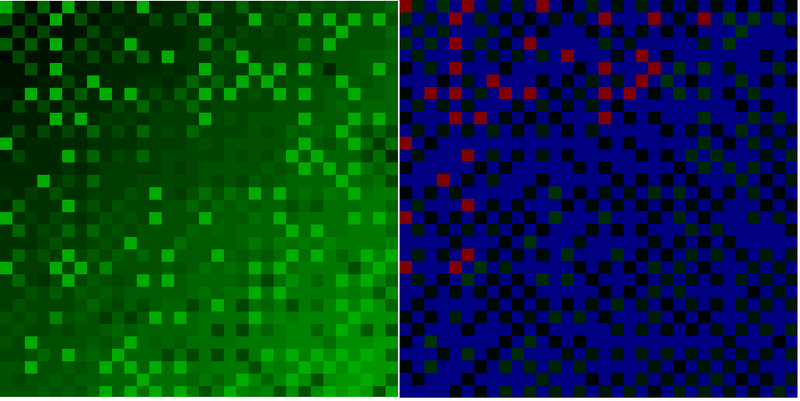
左側は完全な予測マップ、右側はエラー値の分布です(青い点はエラーがないことを示し、黒から緑へのグラデーションは最大10ユニットのエラーを示し、赤のエラーは10ユニットを超えています)。 または、エラー数の分布:
エラー値=対応するポイントの数
0 = 631
1 = 114
2 = 63
3 = 23
4 = 45
5 = 25
6 = 28
7 = 19
8 = 19
9 = 10
10 = 14
11 = 9
12 = 4
13 = 8
14 = 6
15 = 3
16 = 2
17 = 1
これはMLP + BackPropの場合よりもわずかに悪いですが、違いはパーセプトロンが画像の外観の統計のみに由来することであり、MLP + BackPropを使用する場合、実験者はさらに構造適応のタスクを実行します。
ここで、構造適応の実行方法を学習した場合、パーセプトロンはトレーニングサンプルの統計に基づいて予測できるだけでなく、構造/機能のタイプも考慮に入れることができます。