
ほとんどの人は知りませんが、私の論文は画像からテキストを読むためのプログラムでした。 高レベルの認識が得られれば、これを使用して検索結果を改善できると考えました。 私の優れた顧問であるガオ・ジュンビン博士は 、この主題について論文を書くことを提案しました。 最後に、私はこの記事を書く時間を見つけました、そして、ここで私が学んだすべてについて話そうとします。 私がちょうど始めていたときにこのような何かがあった場合...
私が言ったように、私はインターネットから通常の画像を取得し、検索結果を改善するためにそれらからテキストを抽出しようとしました。 私のアイデアのほとんどは、キャプチャをハッキングする方法に基づいていました。 誰もが知っているように、captchaは、登録ページまたはフィードバックページの「画像に表示されている文字を入力する」など、非常に迷惑なものです。
CAPTCHAは、人が難なくテキストを読むことができるように設計されていますが、マシンはできません(こんにちは、reCaptcha!)。 実際には、サイトに投稿されたほぼすべてのキャプチャが数か月間クラックされたため、これは機能しませんでした。
私はかなりうまくやった-画像の60%以上は私の小さなコレクションから正常に解決されました。 インターネット上のさまざまな画像を考慮すると、かなり良いです。
私の研究では、私に役立つ資料は見つかりませんでした。 はい、記事はありますが、非常に単純なアルゴリズムが公開されています。 実際、PHPとPerlで動作しないサンプルをいくつか見つけ、それらからいくつかのフラグメントを取り出して、非常に単純なキャプチャで良い結果を得ました。 しかし、それらのどれも私を本当に助けませんでした、それがあまりにも簡単だったので。 私は理論を読むことができる人の一人ですが、実際の例がなければ何も理解しません。 そして、ほとんどの記事で、彼らはコードを公開しないと書かれていました。なぜなら、彼らは悪い目的でそれを使うことを恐れていたからです。 個人的には、キャプチャは時間の無駄だと思います。方法を知っていれば、簡単に回避できるからです。
実際、初心者向けのハッキングキャプチャを示す資料が不足しているため、この記事を書きました。
始めましょう。 この記事で取り上げる内容のリストは次のとおりです。
- 使用技術
- キャプチャとは
- 画像からテキストを見つけて抽出する方法
- AI画像認識
- トレーニング
- すべてをまとめる
- 結果と結論
使用技術
すべての例は、PILライブラリを使用してPython 2.5で記述されています。 Python 2.6でも動作するはずです(Python 2.7.3、 約Translで正常に動作します )。
- Python: www.python.org
- PIL: www.pythonware.com/products/pil
上記の順序でインストールすると、サンプルを実行する準備が整います。
リトリート
例では、コードに直接多くの値を厳密に設定します。 ユニバーサルキャプチャレコグナイザーを作成するという目標はありませんが、これがどのように行われるかを示すだけです。
キャプチャ、最終的には何ですか?
ほとんどの場合、キャプチャは一方向の変換の例です。 文字セットを簡単に取得してキャプチャすることができますが、その逆はできません。 もう1つの微妙な点-人間にとっては読みやすいはずですが、機械の認識には適していません。 CAPTCHAは、「あなたは人間ですか?」などの簡単なテストと考えることができます。 基本的に、それらはいくつかの記号または単語を含む画像として実装されます。
多くのWebサイトでスパムを防ぐために使用されます。 たとえば、captchaは、 Windows Live IDの登録ページにあります 。
画像が表示されますが、実際に人間である場合は、別のフィールドにそのテキストを入力する必要があります。 フォーラムでのバイアグラのスパムや配布のための何千もの自動登録からあなたを守ることができるのは良い考えのように思えますか? 問題は、AI、特に画像認識方法が大幅に変更され、特定の分野で非常に効果的になっていることです。 最近のOCR(光学文字認識)はかなり正確で、印刷されたテキストを簡単に認識します。 ユーザーに不便を感じさせずにコンピューターが動作しにくくするために、少し色と線を追加することにしました。 これは一種の軍拡競争であり、いつものように、彼らはあらゆる防衛のためにより強力な武器を思いつきます。 強化されたキャプチャを倒すことはより困難ですが、それでも可能です。 さらに、普通の人に刺激を与えないように、画像はかなりシンプルなままにしておく必要があります。
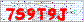
この画像は、解読するキャプチャの例です。 これは実際のキャプチャであり、実際のサイトに投稿されます。
これはかなり単純なキャプチャで、白い背景に同じ色とサイズの文字で構成され、ノイズ(ピクセル、色、線)があります。 バックグラウンドでのこのノイズは認識しにくくなると思われますが、削除するのがどれほど簡単かを示します。 これは非常に強力なキャプチャではありませんが、プログラムの良い例です。
画像からテキストを見つけて抽出する方法
画像内のテキストの位置とその抽出を決定するための多くの方法があります。 Googleを使用すると、テキストを検索するための新しい方法とアルゴリズムを説明する何千もの記事を見つけることができます。
この例では、色抽出を使用します。 これはかなり簡単な手法で、かなり良い結果が得られました。 このテクニックを論文に使用しました。
この例では、多値画像分解アルゴリズムを使用します。 本質的に、これは最初に画像の色のヒストグラムをプロットすることを意味します。 これは、色ごとにグループ化された画像内のすべてのピクセルを取得することによって行われ、その後、各グループに対してカウントが実行されます。 テストキャプチャを見ると、次の3つの原色を見ることができます。
- 白(背景)
- グレー(ノイズ)
- 赤(テキスト)
Pythonでは、これは非常に単純に見えます。
次のコードは、画像を開き、GIFに変換し(255色しかないため作業しやすくします)、色のヒストグラムを印刷します。
from PIL import Image im = Image.open("captcha.gif") im = im.convert("P") print im.histogram()
その結果、次の結果が得られます。
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 , 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 2, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 2, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 2, 1, 0, 0, 0, 2, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0 , 1, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0, 0, 1, 2, 0, 1, 0, 0, 1, 0, 2, 0, 0, 1, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 3, 1, 3, 3, 0, 0, 0, 0, 0, 0, 1, 0, 3, 2, 132, 1, 1, 0, 0, 0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 15, 0 , 1, 0, 1, 0, 0, 8, 1, 0, 0, 0, 0, 1, 6, 0, 2, 0, 0, 0, 0, 18, 1, 1, 1, 1, 1, 2, 365, 115, 0, 1, 0, 0, 0, 135, 186, 0, 0, 1, 0, 0, 0, 116, 3, 0, 0, 0, 0, 0, 21, 1, 1, 0, 0, 0, 2, 10, 2, 0, 0, 0, 0, 2, 10, 0, 0, 0, 0, 1, 0, 625]
ここでは、画像の255色それぞれのピクセル数を確認します。 白(255、最新)が最も頻繁に見つかることがわかります。 その後に赤(テキスト)が続きます。 これを確認するために、小さなスクリプトを作成します。
from PIL import Image from operator import itemgetter im = Image.open("captcha.gif") im = im.convert("P") his = im.histogram() values = {} for i in range(256): values[i] = his[i] for j,k in sorted(values.items(), key=itemgetter(1), reverse=True)[:10]: print j,k
そして、次のデータを取得します。
| 色 | ピクセル数 |
|---|---|
| 255 | 625 |
| 212 | 365 |
| 220 | 186 |
| 219 | 135 |
| 169 | 132 |
| 227 | 116 |
| 213 | 115 |
| 234 | 21 |
| 205 | 18 |
| 184 | 15 |
これは、画像で最も一般的な10色のリストです。 予想どおり、白が最も頻繁に繰り返されます。 その後、灰色と赤になります。
この情報を取得したら、これらの色グループに基づいて新しい画像を作成します。 最も一般的な色のそれぞれについて、2色の新しいバイナリイメージを作成します。この色のピクセルは黒で塗りつぶされ、他のすべては白です。
赤は最も一般的な色の3番目になりました。つまり、220の色のピクセルのグループを保存することを意味します。実験してみると、227の色が220にかなり近いため、このピクセルのグループを保持します。 以下のコードはcaptchaを開き、GIFに変換し、同じサイズの新しい画像を白い背景で作成し、必要な色を探して元の画像をバイパスします。 必要な色のピクセルを見つけた場合、2番目の画像の同じピクセルを黒でマークします。 シャットダウンする前に、2番目の画像が保存されます。
from PIL import Image im = Image.open("captcha.gif") im = im.convert("P") im2 = Image.new("P",im.size,255) im = im.convert("P") temp = {} for x in range(im.size[1]): for y in range(im.size[0]): pix = im.getpixel((y,x)) temp[pix] = pix if pix == 220 or pix == 227: # these are the numbers to get im2.putpixel((y,x),0) im2.save("output.gif")
このコードを実行すると、次の結果が得られます。
| オリジナル | 結果 |
| 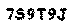 |
写真では、背景からテキストを正常に抽出できたことがわかります。 このプロセスを自動化するには、最初と2番目のスクリプトを組み合わせることができます。
「キャプチャのテキストが異なる色で書かれている場合はどうすればよいですか?」 はい、当社の技術は引き続き機能します。 最も一般的な色が背景色であると仮定すると、文字の色を見つけることができます。
したがって、現時点では、画像からテキストを正常に抽出できました。 次のステップは、画像にテキストが含まれているかどうかを判断することです。 アルゴリズム自体は非常に単純ですが、理解を困難にするため、ここではまだコードを記述しません。
for each binary image: for each pixel in the binary image: if the pixel is on: if any pixel we have seen before is next to it: add to the same set else: add to a new set
出力には、一連の文字境界があります。 それから、あなたがする必要があるのは、それらを互いに比較し、それらが連続して行くかどうかを見るだけです。 はいの場合、ジャックポットがあり、次に行くキャラクターを正しく識別しました。 また、受信した領域のサイズを確認したり、新しい画像を作成して表示したり(画像の
show()
メソッド)して、アルゴリズムが正確であることを確認することもできます。
from PIL import Image im = Image.open("captcha.gif") im = im.convert("P") im2 = Image.new("P",im.size,255) im = im.convert("P") temp = {} for x in range(im.size[1]): for y in range(im.size[0]): pix = im.getpixel((y,x)) temp[pix] = pix if pix == 220 or pix == 227: # these are the numbers to get im2.putpixel((y,x),0) # new code starts here inletter = False foundletter=False start = 0 end = 0 letters = [] for y in range(im2.size[0]): # slice across for x in range(im2.size[1]): # slice down pix = im2.getpixel((y,x)) if pix != 255: inletter = True if foundletter == False and inletter == True: foundletter = True start = y if foundletter == True and inletter == False: foundletter = False end = y letters.append((start,end)) inletter=False print letters
その結果、次のようになりました。
[(6, 14), (15, 25), (27, 35), (37, 46), (48, 56), (57, 67)]
これらは、各文字の始まりと終わりの水平位置です。
パターン認識のためのAIおよびベクトル空間
画像認識は、最新のAIの最大の成功と考えることができ、あらゆる種類の商用アプリケーションに組み込むことができました。 この好例は、郵便番号です。 実際、多くの国では、数字を認識するようにコンピューターに教えることは非常に簡単な作業であるため、自動的に読み取られます。 これは明らかではないかもしれませんが、パターン認識はAIの問題と見なされますが、非常に特殊な問題です。
パターン認識でAIと出会ったときに最初に遭遇することは、ニューラルネットワークです。 個人的には、文字認識のニューラルネットワークで成功したことはありません。 私は通常彼に3〜4人のキャラクターを教えます。その後、精度は非常に低くなり、桁違いに高くなります。キャラクターはランダムに推測します。 これは私の論文の非常にミッシングリンクであったため、最初はわずかなパニックを引き起こしました。 幸いなことに、私は最近、ベクトル空間検索エンジンに関する記事を読み、データを分類するための代替方法であることに気付きました。 結局、彼らは最良の選択であることが判明しました。
- 大規模な学習は必要ありません。
- 間違ったデータを追加/削除して、すぐに結果を見ることができます
- 理解とプログラミングが簡単です。
- 分類された結果が提供されるため、上位Xの一致を確認できます。
- 何かを認識できませんか? これを追加すると、以前に見たものとは完全に異なっていても、すぐに認識できるようになります。
もちろん、無料のチーズはありません。 速度の主な欠点。 彼らはニューラルネットワークよりもはるかに遅くなる可能性があります。 しかし、彼らの利点はこの欠点よりもまだ大きいと思います。
ベクトル空間の仕組みを理解したい場合は、 ベクトル空間検索エンジン理論を読むことをお勧めします。 これは私が初心者のために見つけた最高のものです。
前述のドキュメントに基づいて画像認識を構築しました。これは、当時勉強していたお気に入りのPLで最初に記述しようとしたものです。 このドキュメントを読み、その本質を理解したら、ここに戻ってください。
もう帰ってきた? いいね 次に、ベクトル空間をプログラムする必要があります。 幸いなことに、これはまったく難しくありません。 始めましょう。
import math class VectorCompare: def magnitude(self,concordance): total = 0 for word,count in concordance.iteritems(): total += count ** 2 return math.sqrt(total) def relation(self,concordance1, concordance2): relevance = 0 topvalue = 0 for word, count in concordance1.iteritems(): if concordance2.has_key(word): topvalue += count * concordance2[word] return topvalue / (self.magnitude(concordance1) * self.magnitude(concordance2))
これは、15行のPythonベクトル空間の実装です。 基本的に、2つのディクショナリが必要であり、0から1までの数字を与えて、それらがどのように接続されているかを示します。 0は接続されていないことを意味しますが、1は同一であることを意味します。
トレーニング
次に必要なのは、キャラクターを比較するための一連の画像です。 学習セットが必要です。 このセットは、使用するあらゆる種類のAI(ニューラルネットワークなど)のトレーニングに使用できます。
使用されるデータは、認識を成功させるために重要です。 データが優れているほど、成功する可能性が高くなります。 特定のキャプチャを認識し、それから既にシンボルを抽出できるので、トレーニングセットとして使用してみませんか?
これは私がやったことです。 生成された多くのキャプチャをダウンロードし、私のプログラムはそれらを文字に分割しました。 次に、受け取った画像をコレクション(グループ)に収集しました。 何度か試みた後、私はキャプチャが生成した各キャラクターの少なくとも1つの例を持っていました。 さらに例を追加すると認識の精度が向上しますが、これで理論を確認するには十分でした。
from PIL import Image import hashlib import time im = Image.open("captcha.gif") im2 = Image.new("P",im.size,255) im = im.convert("P") temp = {} print im.histogram() for x in range(im.size[1]): for y in range(im.size[0]): pix = im.getpixel((y,x)) temp[pix] = pix if pix == 220 or pix == 227: # these are the numbers to get im2.putpixel((y,x),0) inletter = False foundletter=False start = 0 end = 0 letters = [] for y in range(im2.size[0]): # slice across for x in range(im2.size[1]): # slice down pix = im2.getpixel((y,x)) if pix != 255: inletter = True if foundletter == False and inletter == True: foundletter = True start = y if foundletter == True and inletter == False: foundletter = False end = y letters.append((start,end)) inletter=False # New code is here. We just extract each image and save it to disk with # what is hopefully a unique name count = 0 for letter in letters: m = hashlib.md5() im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] )) m.update("%s%s"%(time.time(),count)) im3.save("./%s.gif"%(m.hexdigest())) count += 1
出力では、同じディレクトリに一連の画像を取得します。 複数のキャプチャを処理する場合、それぞれに一意のハッシュが割り当てられます。
テストcaptchaのこのコードの結果は次のとおりです。
 |  |  |  |  |  |
これらの画像の保存方法はユーザーが決定しますが、画像上にある同じ名前(シンボルまたは番号)のディレクトリに保存するだけです。
すべてをまとめる
最後のステップ。 テキスト抽出、文字抽出、認識技術、トレーニングセットがあります。
キャプチャの画像を取得し、テキストを選択し、キャラクターを取得し、トレーニングセットと比較します。 このリンクから、トレーニングセットと少数のキャプチャを含む最終プログラムをダウンロードできます。
ここで、トレーニングセットをダウンロードして、比較できるようにします。
def buildvector(im): d1 = {} count = 0 for i in im.getdata(): d1[count] = i count += 1 return d1 v = VectorCompare() iconset = ['0','1','2','3','4','5','6','7','8','9','0','a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t',' u','v','w','x','y','z'] imageset = [] for letter in iconset: for img in os.listdir('./iconset/%s/'%(letter)): temp = [] if img != "Thumbs.db": temp.append(buildvector(Image.open("./iconset/%s/%s"%(letter,img)))) imageset.append({letter:temp})
そして、すべての魔法が起こっています。 各文字がどこにあるかを判断し、ベクトル空間で確認します。 次に、結果を並べ替えて印刷します。
count = 0 for letter in letters: m = hashlib.md5() im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] )) guess = [] for image in imageset: for x,y in image.iteritems(): if len(y) != 0: guess.append( ( v.relation(y[0],buildvector(im3)),x) ) guess.sort(reverse=True) print "",guess[0] count += 1
結論
これで必要なものはすべて揃い、奇跡のマシンを立ち上げることができます。
入力ファイルは
captcha.gif
です。 期待される結果:
7s9t9j
python crack.py (0.96376811594202894, '7') (0.96234028545977002, 's') (0.9286884286888929, '9') (0.98350370609844473, 't') (0.96751165072506273, '9') (0.96989711688772628, 'j')
ここで、疑わしいシンボルと、それが実際に存在する信頼度(0から1)が表示されます。
本当に成功したようです!
実際、テストキャプチャでは、このスクリプトは約22%のケースで成功します( 約 28.5を取得しました。Transl。 )。
python crack_test.py Correct Guesses - 11.0 Wrong Guesses - 37.0 Percentage Correct - 22.9166666667 Percentage Wrong - 77.0833333333
ほとんどの誤った結果は、数字「0」と文字「O」の誤った認識によるものです。 人々でさえもしばしば混乱させるので、予想外のものは何もありません。 文字への分割にはまだ問題がありますが、これは単純に分割の結果を確認して中間点を見つけることで解決できます。
ただし、そのような完全ではないアルゴリズムを使用しても、人が1つを解決できなかった時間に、5つ目のすべてのキャプチャを解決できます。
Core 2 Duo E6550でこのコードを実行すると、次の結果が得られます。
real 0m5.750s user 0m0.015s sys 0m0.000s
翻訳者から。 Dual Core T4400で次の結果が得られました。
real 0m0.176s user 0m0.160s sys 0m0.012s
私たちのカタログには48個のキャプチャが含まれており、これを解決するのに約0.12秒かかります。 22%の成功率で、1日あたり約432,000のキャプチャを解決し、95,040の正しい結果を得ることができます。 そして、マルチスレッドを使用している場合は?
以上です。 私の経験が良い目的のためにあなたによって使われることを願っています。 このコードを使用して損害を与えることができることは知っていますが、本当に危険なことを行うには、かなり多く変更する必要があります。
captchaで自分自身を保護しようとしている人にとっては、プログラムで回避されるか、手動で解決する他の人に単純に支払われるため、これはあまり役に立ちません。 自分を守る他の方法を考えてください。