データ収集
何かを決める前に、全体像を見て、データから何らかの絞り込みを見てみるといいでしょう。 このため、最初にデータを収集する必要があります。 私はミンスクのアパートに最大6万ドルまで興味がありました(そのようなお金でアパートを買うことが本当に可能であることを知ったとき、マスコビッツが唾液を絞らないことを望みますか?)。 Googleはすぐにいくつかの不動産サイトを発行しましたが、そのうち、必要な検索設定の最大数はirr.byにありました。 もちろん彼のデザインは噴水ではありませんが、私は色で不動産サイトを選ぶブロンドの女の子ではありません。 とにかく、HTMLページ形式のデータは私には向いていませんでした。
数時間、検索文字列を入力に取り込むパーサーを投げ、結果の最初の5ページを実行し、興味のあるパラメーターを収集しました。 そして、次のことは私に興味がありました:
- 価格(以下-価格変数)
- 年齢
- メトロまでの距離(dist_to_subway)
- 家の階(階)と階数(storey_no)
- バルコニーまたはロッジア(バルコニー)の存在
- 合計(total_space)とリビングエリア(living_space)、およびキッチンのエリア(kitchen_space)
- 個別の部屋の数(room_no)
- バスルームのタイプ(restroom_comは一般、restroom_sepは個別)
問題を提起した唯一のものは、地下鉄までの距離でした。 通常、不動産サイトはそのような情報を提供しません。 通りの名前、家の番号、最寄りの駅だけがありますが、そこまでいくら行くかは一言ではありません。 幸いなことに、住所で座標を決定する問題は新しいものではなく、対応するプロセスはジオコーディングと呼ばれ、Babla Corporationはこの善行のために無料のサービスさえ提供しています。 コーヒーとクッキーの休憩で30分間のプログラミングを行った後、住所の地下鉄駅までの距離を決定するモジュールの準備が整いました。 (結果は非常に正確であることが判明したことに注意してください-約50の検証済み住所のうち、通りを指しているのは家ではなく2つだけで、他は完全に正しかったことに注意してください。リクエスト間の小さな中断、エラーが発生する可能性があります。)
売り手はアパートを説明するためのフィールドに常に慎重かつ正確に入力するとは限らないため、データは不完全でした。 良い方法では、空白のフィールドをNA(使用不可)としてマークし、このフォームでそれらを渡す必要がありました。 しかし、それは夕方であり、まだやることがあったので、単純化されたスキームに従って、データ収集段階でデフォルト値を打ち込むことにしました。 建設年に関する情報がない場合、1980(それぞれ、年齢-32歳)、地下鉄までの距離-2000メートル、床-4、階数-7を記録しました。非常にシンプルでほぼランダムです。 部屋の数、面積、価格は必須パラメーターであり、それらが存在しない場合、アパートは単純に破棄されました(結果として、これらのパラメーターの少なくとも1つが存在しない単一のケースは検出されませんでした)。
それとは別に、浴室のタイプについて話す必要があります。 数値計算を予想して、共通/個別の値を操作することは数値を操作するよりもはるかに難しいことに気づいたため、タイプごとに1つずつ、2つの個別の変数を作成する必要がありました。 さらに、1つの変数が1に等しい場合、2番目の変数は必然的に0に等しくなりました。統計では、これはダミー変数またはインジケータ変数と呼ばれます 。
しかし、トイレについては十分です。データを見てみましょう。
データを最初に見る
最も一般的なデータ分析ツールの1つはプロジェクトRです。 Rは、統計分析と機械学習だけでなく、データの操作と視覚化のための広範な機能を備えた開発環境とプログラミング言語です。 RStudioやEmacsプラグインなど、スクリプトを簡単に編集するための開発環境がいくつかありますが、ほとんどのタスクには共通のコンソールで十分です。 これはすべてクロスプラットフォームであり、完全に無料です。つまり、無料です。 Rは別の詳細な記事に間違いなく値します。ここでは、直接使用する関数と言語構造の説明に限定します。
上記で説明した広告パーサーは、受信したデータをCSVファイルとしてディスクに保存しました。 Rに読み込むには、次の関数を呼び出すだけです。
> dat <- read.csv("/path/to/dataset.csv")
, , `<-`. `=`, . , , .. :
> read.csv("/path/to/dataset.csv") -> dat
dat ( «data» ) `data.frame`. — R , , , `_` C `-` Lisp ( , , , - - , ). : , , . , price (6- ) :
> dat[6]
> dat["price"] # - dat$price
:
> dat[3, 6] # 3 6
:
> dat[1:10, 1:6] # , 10 6
> dat[1:10, c(3, 5)] # 10 3 5
> dat[, 6] # 6- ( dat[6])
> dat[, -6] # , 6
> dat[,] # ( dat)
, R . plot(). , 2 ( , ) (scatter plot). plot() , R :
> ?plot
, . :
> plot(dat$room_no, dat$price)
:
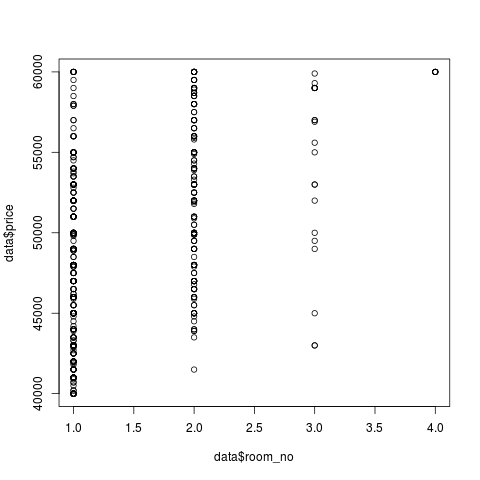
! 3- 4- ! . . dist_to_subway :
> dat[dat$room_no == 4, ]$dist_to_subway
[1] 2000.000 2000.000 2000.000 2000.000 4305.613
, 4 (`dat[dat$room_no == 4, ]`), (`$dist_to_subway`). — . , (2000 ), . , . , - , . . . , 1-, 3- 4-, ( ) URL ( ). , , , restroom_sep restroom_com , .
> dat2 <- dat[dat$room_no == 2, -(7, 8, 9, 13)]
: , /.
, , . cor(), , , , ( ):
> cor(dat2) age balcony dist_to_subway kitchen_space living_space age 1.0000000 0.23339483 0.23677636 -0.30167358 -0.18938523 balcony 0.2333948 1.00000000 -0.06881481 0.05694279 -0.03505876 dist_to_subway 0.2367764 -0.06881481 1.00000000 0.22700865 -0.21201038 kitchen_space -0.3016736 0.05694279 0.22700865 1.00000000 0.10018058 living_space -0.1893852 -0.03505876 -0.21201038 0.10018058 1.00000000 price -0.2246434 0.18848129 -0.11713353 0.35152990 0.22979332 storey -0.1740015 0.12504337 -0.03107719 0.22760853 0.09702503 storey_no -0.4683041 -0.28689325 -0.15872038 0.10098619 0.02122686 total_space -0.3732784 0.02748897 0.03466465 0.62723545 0.61874577 price storey storey_no total_space age -0.2246434 -0.17400151 -0.46830412 -0.37327839 balcony 0.1884813 0.12504337 -0.28689325 0.02748897 dist_to_subway -0.1171335 -0.03107719 -0.15872038 0.03466465 kitchen_space 0.3515299 0.22760853 0.10098619 0.62723545 living_space 0.2297933 0.09702503 0.02122686 0.61874577 price 1.0000000 0.35325897 0.24603010 0.51735302 storey 0.3532590 1.00000000 0.26811766 0.18082811 storey_no 0.2460301 0.26811766 1.00000000 0.14940533 total_space 0.5173530 0.18082811 0.14940533 1.00000000
, (> 0.6) , . 2- — living_space kitchen_space — total_space.
, . , : (, ) (, ), . , :
> plot(dat2$dist_to_subway, dat2$price)
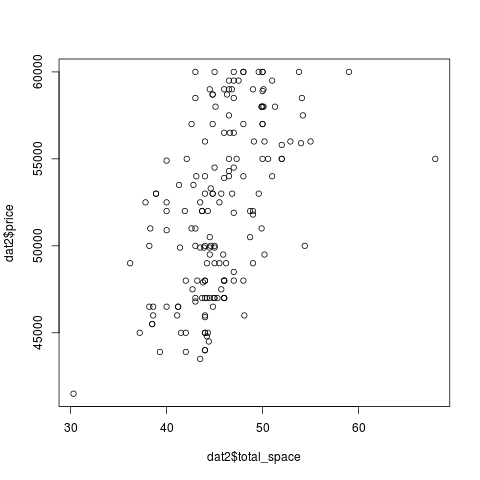
, . , , , , - .
, , - :
> plot(dat2$dist_to_subway, dat2$price)
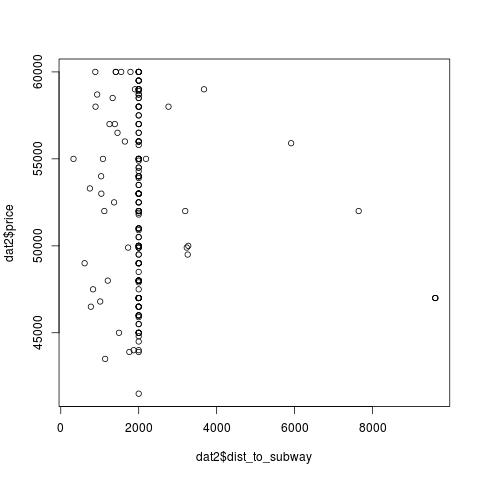
> plot(dat2$age, dat2$price)

, , , , — , , .
, , , . , «». . , , , . — , , , .
-, ? ? , , :
y = k * x + b
? , . y x, ( «») , .
k
X
,
b
—
Y
.
, 2 ? :
z = k1 * x + k2 * y + b
n , :
h(X) = k0 + k1 * x1 + k2 * x2 + ... + kn * xn
x1..xn
— , h(X) — X.
() :
price = k0 + k1 * age + k2 * balcony + k3 * dist_to_subway + k4 * storey + k5 * storey_no + k6 * total_space
,
k0..k6
! , , ? . , (, ) , . , R, lm() ( Linear Model):
> model <- lm(price ~ age + balcony + dist_to_subway + storey + storey_no + total_space, data = dat2)
~ , lm() «». , , R , , . ( ) , (age, balcony, etc.). :
> model <- lm(price ~ ., data = dat2)
, ( , ).
? , , :
> coef(model) (Intercept) age balcony dist_to_subway storey 21601.0057018 31.7479138 1981.3750585 -0.3962895 529.9350262 storey_no total_space 594.3711746 523.7914531
(Intercept)
k0
(, , , , , ). . total_space ( , , — intercept). 2 , 40 . , , . , , . , . . -, , , . -, , , 32- ( ) . -, , , .
. predict(), , «» :
> predicted.cost <- predict(model, dat2)
:
> actual.price <- dat2$price #
> plot(predicted.cost, actual.price) # vs.
> par(new=TRUE, col="red") # : ,
> dependency <- lm(predicted.cost, actual.price) # ,
> abline(dependency) #

, — . — . , . , . .
.
> sorted <- sort(predicted.cost / actual.price, decreasing = TRUE) > sorted[1:10] 343 233 15 485 326 81 384 279 1.182516 1.154181 1.145964 1.144113 1.132918 1.132496 1.132098 1.129221 385 175 1.126982 1.115920
, 343- ( ) 20% ( $10k, ), 233 — 15% .. , ?
: , , , .
, , 8 . : , , , . , . . -, , . -, , . , -, .
. . , ?..
:
1. . flatparser.jar ( , View Raw) README.
2. Coursera, , , .