はじめに
Godオブジェクトのようなアーキテクチャ上のアンチパターンがプロジェクトコードの効果的なメンテナンスを妨げることは秘密ではありません。 ただし、それはまだ企業部門のレガシーシステムにあります。 時間が経つにつれて、コードは非常に複雑になるため、単体テストを使用しても機能を変更することは大きな問題になります。 そのようなシステムをサポートしたい人はいません。誰もが何かを改善することを恐れており、トラッカーの問題の数は一定に保たれていますが、それは成長する可能性があります。 原則として、チームは落ち込んだ気分になり、最終的にスーツケースになります。誰もがダンプしたいです。

そのような場合には、一般的な管理者は危険なステップを踏むことがあります。古いシステムのサポートを停止することなく(給与を支払う必要があります)、過去の経験に基づいて新しいシステムの設計と開発を開始します。 ある会社のアーキテクトとしての仕事の過程で、私は自分の前に書かれたシステムに噛みつき、研究し、パターン、ビジネスルールを把握し、変更が費用対効果の高いものになるようにしなければなりませんでした。
コードの詳細
分析されるシステムはデータベースアクセスレイヤーであり、多数のメソッドを含むインターフェイスを持つクラスです。 各メソッドには、行形式のデータベースへのSQLクエリと、パラメーターの置換、データの読み取りおよび書き込みの操作を実行するヘルパークラスの呼び出しが含まれます。 この層は、個々のメソッドを呼び出すアプリケーションのWebパーツで使用されます。 この単純な方法は長年使用されてきました。 開発者側で緊急の問題を解決しようとする試みがいくつかありましたが、成功しませんでした。必要な機能がコードベースの改善プロセスをかき消しました。 最終的に、ほぼ十数年前に開始されたプロジェクトでは、大規模な修理が必要になり始めました。
プロジェクトのコードベースを短時間でカテゴリー的かつ効果的な改訂に向けて準備する必要がありました。それを理解可能な部分に分割し、初歩を取り除くことです。 最終的には、1つのGodObjectからデータアクセスクラスを取得します。各GodObjectは、システム全体ではなく、システムの特定の部分のみを担当します。 可能であれば、そのようなクラスを各テーブルに割り当てることは素晴らしいことです。
作業計画
この問題はいくつかの段階で解決されました。
- データアクセス層コードの定量的情報の収集。
- メソッドで使用されるテーブルの数の分析。
- テーブルを使用したメソッドの数の分析。
- 使用するテーブルに基づいたクラスタリング方法。
- サブジェクト領域のエンティティのタイプ別にクラスターをグループ化します。
- 計算されたクラスクラスタへのメソッド転送の自動リファクタリング。
- 特殊なケースの手動修正。
この記事で説明されている太字の強調表示された項目。 残りは次です。
行こう!
定量的情報収集
タスクの最終段階は取得したデータのクラスタリングであるため、メソッドとテーブルの関係を反映するのに便利な形式でデータを収集する必要があります。 私の意見では、そのような形式は行列であり、その行はメソッドを反映し、列はテーブルを表し、セルは2つの値を取ることができます:0(メソッドはテーブルを使用しません)と1(メソッドはテーブルを使用します):
| 表1 | 表2 | |
| 方法1 | 1 | 1 |
| 方法2 | 0 | 1 |
コードでそのようなデータを収集するだけです。 データアクセスレイヤーはC#で記述されているため、このタスクが多少簡単になります。 NRefactoryのようなプロジェクトがあります。 これはパーサーであり、SharpDevelopや(最近)MonoDevelopなどの狭いサークルのIDEで広く知られているC#コードコンバーターです。 現在のバージョンの健全なドキュメントを見つけることはできませんでしたが、ライブラリを操作する基本原則が明確な優れたデモがあります。 数時間、情報収集者
分析
目的のマトリックスを受け取った後、行と列を合計した後にデータを降順に並べ替えた場合、メソッドごとのテーブル数とテーブルごとのメソッド数のグラフがどのように見えるか興味がありました。 結果を図1および2に示します。

図1

図2
両方のグラフで、3つの領域を区別できます。
1.急上昇の領域(グラフの先頭)。
2.スムーズな下降の領域(グラフの最後)。
3.「グラフの中央にある」「下降しているように見えますが」という形式の領域。
いくつかの値を求めて3番目の領域のコリドーを決定することもできますが、クイックグーグルでは正常な結果は得られず、平均に基づいて独自のインジケーターを開発することも望みませんでした-とにかく、ゲームはプレイされます。 したがって、 DeductorソフトウェアのKohonen マップアルゴリズムを使用して、両方のグラフを3つのクラスターに分割しました 。 テーブルごとのメソッド数の場合の結果の例を図3に示します。
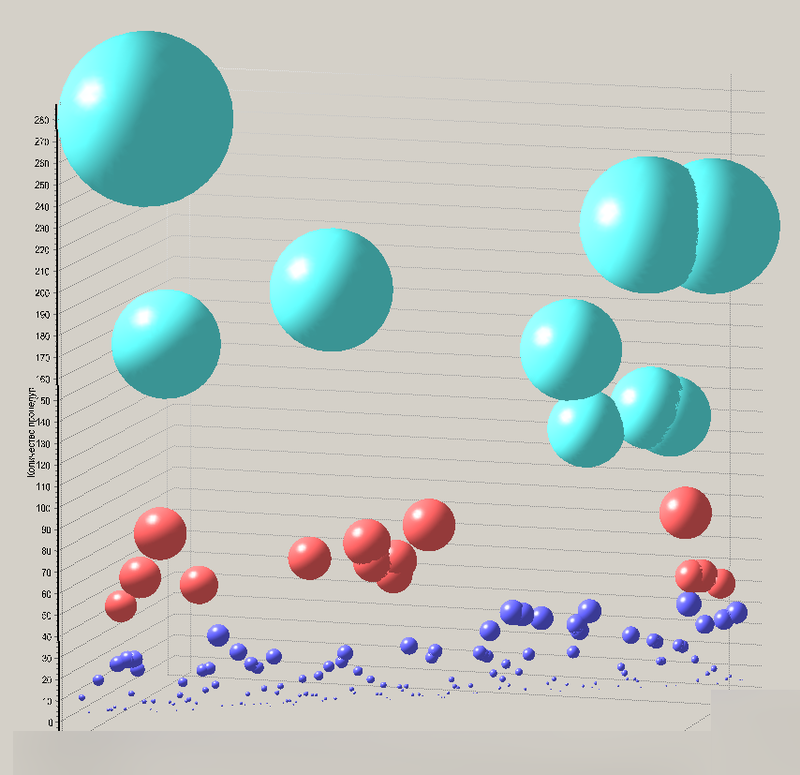
図3.テーブルをクラスタリングした結果の図。 テーブルはボールとして表示され、ボールの色はクラスターの数によって決まり、その半径はこのテーブルを使用するメソッドの数によって決まります。
図3の図をさらに詳細に検討してみましょう。多数のメソッドに含まれるこのようなテーブルがあることが明確にわかります。 これらの表で表されるエンティティは、基本、基本、「集約」(DDDの用語)であると想定しています。これらはほとんどすべてのビジネスオペレーションで使用されています。 赤でマークされた次の安定したグループは、個々のサービスおよびシステムモジュールの最も特徴的な代表であるエンティティです。 これは、将来の主な行動分野です。 青でマークされた最後のグループは、サービス内でローカルに重要である可能性が高い小さなエンティティを表します。 したがって、システムの大まかなプレゼンテーションは、一連のサービス、単純なエンティティ、および集約のルートの形式で取得されました。
次のステップは図2と同じ分析ですが、この場合、識別された3つのグループ(および別の特定のケース)は次のように仮定できます。
- 非常に複雑な方法。自動モードでのクラスタリングは成功しそうにありません。 これらは、巨大なSQLクエリの断片を1つの悪魔のような全体に収集し、結果をユーザーにシャッフルするひどいスパゲッティコードです。 手作りのみ、ハードコアのみ。
- まだ希望がある複雑な方法。 それらはまだあなたの手でリファクタリングする必要がありますが、クラスタリングを試すことができます。
- 6つ以下のテーブルを含む単純なメソッド。 クラスタリングの結果は非常に良いはずです。
- 特別な場合として、1つのテーブルのみで動作するメソッドを区別できます;それらの場合、クラスタリングは必要ありません。ここではすべてが明確です。 つまり クライマックスに到達することすらできておらず、ほぼ25%の作業がすでに完了しています。
まとめ
結果の一部を要約しますが、記事はかなり大きくなりましたが、まだ先です。 問題を長距離から見て、主題領域のいくつかの特徴を見つけることができました。 どのオブジェクトがキーであり、どのオブジェクトがセカンダリであるかはすでに明らかです。 さらに、単一のテーブルで動作する選択したメソッドに基づいて、いくつかのクラスを区別することはすでに可能です。 そのような方法の25%があることを考慮すると、分析サブタスクはすでに4分の1で完了しています。
次は?
次のパート(パート?):分析の完了、クラスタリング結果に基づくクラスの自動選択、Resharper SDKに基づくツールの作成により、手動モードでクラスとメソッドをより細かく選択できます。
- NRefactoryに関する記事を読むのは面白いですか?
- Resharperでリファクタリングを書くことについて別の記事を書くべきですか?
- 誰かが似たようなことをしましたか? 結果は非常に興味深いです、グーグルの何かが役に立たない。
- そして、これらのチャートはどのように見えますか?