1.文字列を大文字または小文字に変換しても、Unicode文字の数は変わりません。
いや テキストでは、大文字の1文字に対応しない小文字の合字が表示される場合があります。 たとえば、大文字に転送する場合:fi(U + FB00)-> FI(U + 0046、U + 0049)
2.リガチャー-倒錯、誰も使用しません。 それらが考慮されない場合、私は正しいです。
いや 別のケースでは、発音区別符号付きの一部の文字は完全に一致しないため、結合文字を使用する必要があります。 アフリカーンス語には、letter(U + 0149)という文字があるとします。 大文字では、2つの文字の組み合わせに対応します。
 (U + 02BC、U + 004E)。 アラビア語のテキストの音訳に出会った場合、
(U + 02BC、U + 004E)。 アラビア語のテキストの音訳に出会った場合、  (U + 1E96)、これも大文字の1文字の一致がないため、次のように置き換える必要があります。
(U + 1E96)、これも大文字の1文字の一致がないため、次のように置き換える必要があります。  (U + 0048、U + 0331)。 ワハン語の手紙があります
(U + 0048、U + 0331)。 ワハン語の手紙があります  (U + 01F0)同様の問題。 これはエキゾチックであると主張するかもしれませんが、Wikipediaにはアフリカーンス語に関する23,000の記事があります。
(U + 01F0)同様の問題。 これはエキゾチックであると主張するかもしれませんが、Wikipediaにはアフリカーンス語に関する23,000の記事があります。
3.わかりました。ただし、結合されたシンボル(コードポイントの変更または結合を含む)を1つのシンボルとして考えてみましょう。 その後、長さは保持されます。
いや たとえば、ドイツ語では「escet」ß(U + 00DF)という文字があります。 大文字に変換すると、2つのSS文字(U + 0053、U + 0053)に変わります。
4.わかりました、わかりました、わかりました。 Unicode文字の数は増加する可能性がありますが、2倍以下であると想定しています。
いや 特定のギリシャ文字があります。たとえば、
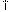 (U + 0390)、3つのUnicode文字に変換します
(U + 0390)、3つのUnicode文字に変換します  (U + 0399、U + 0308、U + 0301)
(U + 0399、U + 0308、U + 0301)
5.タイトルケースについて話しましょう。 ここではすべてが簡単です。単語の最初の文字を大文字に変換し、それをすべて大文字に変換して、後続の文字をすべて小文字に変換しました。
いや 同じ合字を思い出してください。 小文字の単語がfl(U + FB02)で始まる場合、大文字では合字はFL(U + 0046、U + 004C)になりますが、タイトルケースでは-Fl(U + 0046、U + 006C)になります。 ßでも同じですが、理論的には言葉で始めることはできません。
6.再びこれらの合字! 単語の最初の文字を取り出して大文字に変換し、複数の文字が見つかった場合は、最初の文字と残りを小文字に戻します。 その後、それは間違いなく動作します。
動作しません。 たとえば、有向グラフdz(U + 01F3)があり、ポーランド語、スロバキア語、マケドニア語、またはハンガリー語のテキストで使用できます。 大文字では有向グラフdi(U + 01F1)に、タイトルケースでは有向グラフDz(U + 01F2)に対応します。 別の有向グラフもあります。 一方 、ギリシャ語は、 ハイポ グラマーやプログラマーからのジョークであなたを喜ばせます( 残念なことに 、これは現代のテキストではめったに見つかりません)。 一般に、文字の大文字とタイトルケースのオプションは異なる場合がありますが、それらについては、Unicode標準に個別のエントリがあります。
7.良いですが、少なくとも文字の大文字小文字を大文字または小文字に変換した結果は、単語内の位置に依存しません。
いや たとえば、ギリシャ語の大文字シグマΣ(U + 03A3)は単語の末尾にあり、小文字のς(U + 03C2)になり、中間に-σ(U + 03C3)になります。
8.ああ、まあ、ギリシャのシグマを個別に処理します。 ただし、いずれにしても、テキスト内の同じ位置にある同じ文字は等しく変換されます。
いや たとえば、ほとんどのラテン言語では、I(U + 0049)の小文字バージョンはi(U + 0069)ですが、トルコ語とアゼルバイジャン語ではそうではありません。 そこでは、Iの小文字バージョンはı(U + 0131)であり、iの大文字バージョンはı(U + 0130)です。 トルコでは、このため、さまざまなソフトウェアで魅力的なバグが時々観察されます。 そして、アクセント付きのリトアニア語のテキストに出会った場合、たとえば、大文字のÌ(U + 00CC)は、,(U + 00EC)ではなく、
 (U + 0069、U + 0307、U + 0300)。 一般的に、変換の結果は言語にも依存します。 ここでは、最も複雑なケースについて説明します 。
(U + 0069、U + 0307、U + 0300)。 一般的に、変換の結果は言語にも依存します。 ここでは、最も複雑なケースについて説明します 。
9.なんて恐ろしいことでしょう! さて、大文字と小文字に正しく変換してみましょう。 2つの単語の比較では大文字と小文字は区別されません。小文字に変換して比較します。
上記から生じる多くの落とし穴もあります。 たとえば、ドイツの路線とSTRASSEでは機能しません(最初の路線は変更されず、2つ目は路線になります)。 上記の他の多くの文字には問題があります。
10.うーん...たぶんすべてが大文字になっていますか?
そして、これは常に機能するとは限りません(もっと頻繁に)。 しかし、STRAレコードに出会ったとしましょう
 E(はい、大きなエスセットもドイツ語とユニコードです)、straßeと一致しません。 比較のために、文字は特別なUnicodeテーブル-CaseFoldingに従って変換されるため、ßとSSの両方がssに変わります。
E(はい、大きなエスセットもドイツ語とユニコードです)、straßeと一致しません。 比較のために、文字は特別なUnicodeテーブル-CaseFoldingに従って変換されるため、ßとSSの両方がssに変わります。
11.ああ、これはある種のカペットです!
ここで同意します。
誰かが文字を表示しない場合は、私に個人的なメッセージを書いて、写真に置き換えます。