はじめに
この記事では、以前の投稿で始まったトピックを続けたいと思います(以下を参照-約Per。)。 私が答えようとする質問は、2つ以上のスレッドから単純なデータ型の変数にアクセスするための最も効率的で安全な方法は何かということです。 つまり、値に違反することなく変数を2つのスレッドから同時に変更する方法です。
最初の投稿( 「intを保護するためにmutexが必要か」 )で、2つ以上のスレッドから変数の値を変更することで、変数の値を簡単にゴミに変えることができることを示しました。 2番目の記事( 「pthreadスピンロック」 )では、スピンロック(スピンロック-およその期間 )、 pthreadライブラリへの最新の追加について説明しました。 スピンロックは本当に問題の解決に役立ちます。 ただし、小さなデータ構造の保護には、 intやlongなどの単純なデータ型よりも適しています。 一方、原子変数はこれらのタスクに最適です。
アトミック変数の重要なポイントは、誰かが変数の読み取りまたは書き込みを開始するとすぐに、プロセスを中断して途中で発生するものがないことです。 つまり、アトミック変数にアクセスするプロセスを2つの部分に分けることはできません。 したがって、それらはそのように命名されています。
実際には、アトミック変数は、2つ以上のスレッドから単純な変数に同時にアクセスするという問題に対する最適なソリューションです。
アトミック変数の仕組み
実際、非常に簡単です。 Intel x86およびx86_64プロセッサのアーキテクチャ(他の大部分の最新のプロセッサアーキテクチャと同様)には、メモリアクセス操作中にFSBをブロックする命令があります。 FSBは、フロントサイドバスの略です。 これは、プロセッサがRAMと通信するために使用するバスです。 つまり、FSBをブロックすると、他のプロセッサ(コア)およびこのプロセッサで実行されているプロセスがRAMにアクセスできなくなります。 そしてこれはまさにアトミック変数を実装するために必要なものです。
アトミック変数はLinuxカーネルで広く使用されていますが、何らかの理由でヒューマンユーザーモード用にそれらを実装することを誰も気にしませんでした。 GCC 4.1.2より前。
原子変数のサイズ制限
実用的な理由から、Intelの達人は考えられるすべてのメモリアクセスでFSBロックを実装しませんでした。 たとえば、時間を節約するために、Intelプロセッサでは、単一のプロセッサ命令でmemcpy()およびmemcmp()を実装できます。 ただし、大きなメモリバッファをコピーしている間にFSBをロックすると、コストがかかりすぎる可能性があります。
実際には、1、2、4、および8バイト長の整数にアクセスするときにFSBをブロックできます。 GCCでは、 int 、 long、およびlong long (およびそれらの符号なしの同等物)を使用して、アトミック操作をほぼ透過的に実行できます。
アプリケーションオプション
他の誰もその値を傷つけないことを知って、変数を増やします-これは良いですが、十分ではありません。 次の擬似コードを検討してください。
decrement_atomic_value(); if (atomic_value() == 0) fire_a_gun();
アトミック変数の値が1であるとします。2つのスレッドが擬似Cのこの部分を同時に実行しようとするとどうなりますか?
モデリングに戻りましょう。 スレッド1が1行目を実行して停止し、スレッド2が1行目を実行して2行目の実行を継続する可能性があります。後で、スレッド1が起動して2行目を実行します。
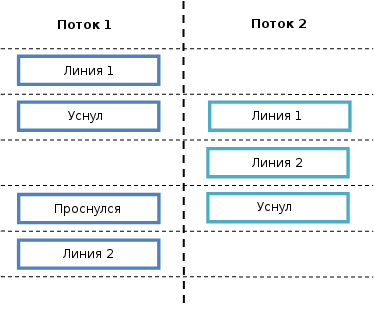
この場合、 どのスレッドもfire_a_gun()プロシージャを開始しません( 3行目)。 明らかに、これは間違った動作であり、ミューテックスまたはスピンロックを使用してコードのこの部分を保護した場合、これは起こりませんでした。
このようなことが起こる可能性に興味がある場合は、必ず確認してください-これは非常に可能性が高いです。 最初にマルチスレッドプログラミングの作業を始めたとき、先ほど説明したシナリオはありそうにないという直感に基づいているにもかかわらず、非常に頻繁に起こることを知って驚きました。
先ほど言ったように、アトミック変数を拒否し、代わりにスピンロックまたはミューテックスを使用することで、この問題を解決できました。 幸いにも、アトミック変数を使用できます。 GCC開発者は、私たちのニーズとこの特定の問題について考え、解決策を提案しました。 アトミック変数を操作する実際の手順を見てみましょう。
実際には...
この機能を実現する簡単な機能がいくつかあります。 まず、アトミックな加算、置換、論理アトミックor、and、xor、nandを実行する関数が12個(はい、12〜12個)あります。 操作ごとに2つの機能があります。 変更前の変数の値を返すものと、変更後の変数の値を返すもの。
実際の機能は次のとおりです。
type __sync_fetch_and_add (type *ptr, type value); type __sync_fetch_and_sub (type *ptr, type value); type __sync_fetch_and_or (type *ptr, type value); type __sync_fetch_and_and (type *ptr, type value); type __sync_fetch_and_xor (type *ptr, type value); type __sync_fetch_and_nand (type *ptr, type value);
これらは、変更する前に変数の値を返す関数です。 一方、次の関数は、変数を変更した後、変数の値を返します。
type __sync_add_and_fetch (type *ptr, type value); type __sync_sub_and_fetch (type *ptr, type value); type __sync_or_and_fetch (type *ptr, type value); type __sync_and_and_fetch (type *ptr, type value); type __sync_xor_and_fetch (type *ptr, type value); type __sync_nand_and_fetch (type *ptr, type value);
各式のタイプは次のいずれかです。
int unsigned int long unsigned long long long unsigned long long
これらは、いわゆる組み込み関数です。つまり、これらを使用するためにヘッダーファイルを含める必要はありません。
それが実際に動作するのを見る時です
前述の最初の投稿で始めた例に戻ります。
これはいくつかのスレッドを開く小さなプログラムであることを思い出させてください。 スレッドの数は、コンピューター内のプロセッサーの数と同じです。 次に、各スレッドをプロセッサの1つにバインドします。 最後に、各スレッドはループを開始し、グローバル整数を100万回インクリメントします。
ソースコード
#include <stdio.h> #include <pthread.h> #include <unistd.h> #include <stdlib.h> #include <sched.h> #include <linux/unistd.h> #include <sys/syscall.h> #include <errno.h> #define INC_TO 1000000 // ... int global_int = 0; pid_t gettid( void ) { return syscall( __NR_gettid ); } void *thread_routine( void *arg ) { int i; int proc_num = (int)(long)arg; cpu_set_t set; CPU_ZERO( &set ); CPU_SET( proc_num, &set ); if (sched_setaffinity( gettid(), sizeof( cpu_set_t ), &set )) { perror( "sched_setaffinity" ); return NULL; } for (i = 0; i < INC_TO; i++) { // global_int++; __sync_fetch_and_add( &global_int, 1 ); } return NULL; } int main() { int procs = 0; int i; pthread_t *thrs; // procs = (int)sysconf( _SC_NPROCESSORS_ONLN ); if (procs < 0) { perror( "sysconf" ); return -1; } thrs = malloc( sizeof( pthread_t ) * procs ); if (thrs == NULL) { perror( "malloc" ); return -1; } printf( "Starting %d threads...\n", procs ); for (i = 0; i < procs; i++) { if (pthread_create( &thrs[i], NULL, thread_routine, (void *)(long)i )) { perror( "pthread_create" ); procs = i; break; } } for (i = 0; i < procs; i++) pthread_join( thrs[i], NULL ); free( thrs ); printf( " , global_int value : %d\n", global_int ); printf( " : %d\n", INC_TO * procs ); return 0; }
36行目と37行目に注意してください。変数を増やすだけでなく、組み込み関数__ sync_fetch_and_add()を使用します。 このコードを実行すると、明らかに期待どおりの結果が得られます。つまり、予想どおりglobal_int値は4,000,000です(マシンのプロセッサ数に100万を掛けたもの-私の場合はクアッドコアマシンです)。 行36をそのままにしてこのコードを実行したとき 、結果は予想どおり4,000,000ではなく1,908,090であったことを思い出してください。
注意事項
アトミック変数を使用する場合、いくつかの追加の予防措置を講じる必要があります。 GCCでアトミック変数を実装する際の重大な問題の1つは、通常の変数でアトミック操作を実行できることです。 つまり、アトミック変数と通常の変数の間には明確な区別はありません。 先ほど説明したように、 __ sync_fetch_and_add()を使用してアトミック変数の値を増やすことを妨げるものはありません。その後、コードでは通常の++演算子で同じことを行います。
明らかに、これは深刻な問題になる可能性があります。 原則として物事は忘れられる傾向があり、プロジェクトの誰かまたはあなた自身がGCCが提供するアトミック関数の代わりに通常の演算子を使用して変数の値を変更し始めるまでは時間の問題です。
この問題を解決するには、CでADT(Abstract Data Type-約Per。)を使用するか、C ++クラスを使用して、アトミック関数と変数をラップすることを強くお勧めします。
おわりに
この記事は、Linuxのマルチスレッドプログラミングの世界における最新のテクノロジーを調査および研究する一連の記事と投稿を締めくくります。 これらの投稿や投稿が役立つことを願っています。 いつものように、追加の質問がある場合は、私に電子メールを書くことをためらわないでください(オリジナルで示されている-約。)
翻訳者のメモ
著者のこの記事およびその他の記事は、トピックに関する資料を網羅しているとは主張していませんが、入門的なプレゼンテーションスタイルが優れています。
現時点ではアトミック変数に注意してください:
- 標準C11(p。7.17)およびC ++ 11(p。29 )で説明されています-ほとんどの場合、それらの実装は利用可能です(ただし、C11にはまだ問題があります)。
- Boost.AtomicとしてBoostに対して記述および実装されています (ただし、この実装はboost 1.50に含まれていませんでした)。
- Intel Threading Building Blocksに実装されています。