多くの場合、クエリに{“ name”:“ Charlie”}などの等価条件が含まれている場合、上記の原則は非常に役立ちます。 しかし、彼については次の例で言えます。
: db.drivers.find({"country": {"$in": ["A", "G"]}).sort({"carsOwned": 1}) : {"country": 1, "carsOwned": 1}
このバンドルは効果的ではありませんが、原則は尊重されます。 この原則があなたを導くことができるtrapがあるからです。
以下に、このトラップが発生する理由を検討し、記事の終わりまでに、インデックス作成に役立つ新しいルールを作成します。
MongoDBのドキュメントから基本を思い出してみましょう。
*「早期インデックス」
インデックスは、設計の開始時に考慮に値します。 歴史的に、データアクセスレベルでの効率はデータベース管理者にシフトし、設計後に最適化レイヤーが作成されました。
ドキュメント指向のデータベースを使用すると、これを回避できます。
*「頻繁にインデックスを作成する」
インデックス付きクエリは、小さなデータであっても数桁優れた機能を発揮します。 インデックスがない場合、クエリには10秒かかることがありますが、対応するインデックスでは同じクエリに0ミリ秒かかることがあります。
*「インデックスを完全に」
クエリは左から右にインデックスを使用します。 クエリがインデックス内のすべてのフィールドをギャップなしで使用する場合にのみ、インデックスを使用できます。
*「インデックスの並べ替え」
クエリに並べ替えが含まれる場合は、並べ替えられたフィールドをインデックスに追加します。
*「チーム」
.explain()は、この要求に使用されるインデックスを示します。
.ensureIndex()はインデックスを作成します。
.getIndexes()および.getIndexKeys()は、どのインデックスがあるかを示します。
質問に戻りましょう。 次のクエリのインデックス作成の基本を考えると:
db.collection.find({"country": "A"}).sort({"carsOwned": 1})
次のようなインデックスを作成する必要があります。
db.collection.ensureIndex({"country": 1, "carsOwned": 1})
条件内のほとんどのクエリが比較ではなく範囲選択を使用する場合はどうなりますか? このように:
db.collection.find({"country": {"$in": ["A", "G"]}}).sort({"carsOwned": 1})
ここでは$ in演算子を使用しましたが、それ以外にも$ gt、$ ltなどもあります。
同様のクエリを使用すると、基本は覚えているものの、効果的ではないことがわかります。.explain()を実行し、どのインデックスがどのように使用されているかを確認する必要があります。
.explain()実行の結果、{scanAndOrder:true}が表示されます。これは、MongoDBがソート操作を実行することを意味します。これは、 MongoDBはメモリ内のドキュメントをソートします。 したがって、大きなデータセットは避けてください。 時間がかかり、リソースを大量に消費します。
scanAndOrderが遅い理由、MongoDBが既にソート付きのインデックスを持っているのに結果をソートする理由を忘れないでください。 答えは簡単です。適切なインデックスがありません。
なんで? 理由は簡単です。ポイントは、作成したインデックスの構造です。 上記の例では、{“ country”:“ A”}を持つドキュメントと{“ country”:“ G”}を持つドキュメントは、インデックス内で{“ carsOwned”:1}でソートされます。
しかし、それらは互いに独立してソートされます。 それらは一緒にソートされません! 以下のチャートを検討してください。
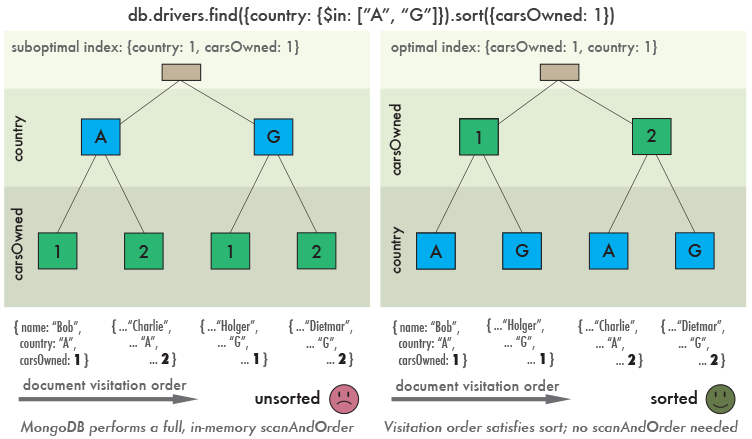
左の図は、作成したインデックスによるドキュメントのクロール順序を示しています。 すべてのドキュメントが見つかったら、並べ替える必要があります。
右の図では、代替インデックスは{“ carsOwned”:1、“ country”:1}です。 この場合、見つかったドキュメントは既にソートされています。
この効率の微妙な点により、インデックス作成に関する次のルールが作成されました。
フィールドの順序は次のとおりです。
1.最初に、正確な値によって選択されるフィールド。
2.次に、ソートの対象となるフィールド。
3.そして、範囲フィルターのフィールドの最後に。
終了
妥協点はありますか? はい 要求はいくつかのインデックスノードによってアクセスされますが、これは技術的な理由です。 ソートされた部分は、フィルタリングの前に走査されます。
したがって、新しいルールは多くのクエリに対して純粋なネットですが、データの複雑さが異なる結果につながる可能性があることを忘れないでください。
このガイドがお役に立てば幸いです。 がんばって。