問題
まず、問題が何であるかを考えてみましょう。なぜユークリッド距離を他のメトリックで置き換えないのですか。 k-meansアルゴリズムには、クラスタリング用のデータと、データを分割する必要があるクラスターの数という2つのパラメーターが入力されます。 このアルゴリズムは、次の手順で構成されています。
- 何らかの方法でクラスター重心の初期初期化(たとえば、データが定義されているスペースからランダムに選択されたポイントによって初期値を設定できます。入力データ配列からランダムなポイントを選択できます)。
- Eステップ( 予想 ):データ要素とクラスターの間に関連があり、それらは中心(重心)の形で表されます。
- Mステップ( 最大化 ):クラスターの中心は、対応するクラスターに含まれていたデータからの平均値として再計算されます(つまり、モデルパラメーターは、要素が選択されたクラスターに入る確率を最大化するように変更されます)。 手順2の後のクラスターが空であることが判明した場合、他の何らかの方法で再初期化が行われます。
- 収束するまで、またはアルゴリズムを停止するための別の基準に達するまで(たとえば、一定の反復回数を超える場合)、手順2〜3が繰り返されます。
この単純なアルゴリズムの背後にある数学を理解するには、 ベイジアンクラスタリングと期待値最大化アルゴリズムに関する記事を読むことをお勧めします。
ユークリッド距離を別のメトリックで置き換える問題は、Mステップです。 たとえば、テキストデータがあり、 レーベンシュタイン距離がメトリックとして使用される場合、平均値を見つけることは完全に簡単な作業ではありません。 私にとっては、マハラノビスの平均を見つけることでさえ、すぐに解決される問題ではありませんでしたが、幸運にも「重心」を選択する非常に簡単な方法を説明する記事に出会いました 。 引用符では、重心の正確な値は検索されませんが、その記事ではクラスターイドと呼ばれるおおよその値が選択されるため(または、 k-medoidとの類推により、ハニーイドと呼ばれることもあります)。 したがって、最大化ステップは次のアルゴリズムに置き換えられます。
- Mステップ:重心に割り当てられたすべてのデータ要素のうち、クラスタの他のすべての要素までの距離の合計が最小になる要素が選択されます。 この要素はクラスターの新しい中心になります。
ところで、私にとって収束の問題はまだ開かれていますが、いくつかの準最適なソリューションでアルゴリズムを停止する多くの方法があります。 この実装では、コスト関数が大きくなり始めたらアルゴリズムを停止します。
現在のパーティションのコスト式では、次の式が使用されます。
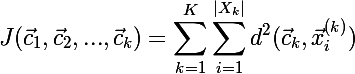 ここで、Kはクラスターの数、
ここで、Kはクラスターの数、 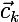 -クラスターの現在の中心、
-クラスターの現在の中心、  クラスターkに割り当てられた要素のセットであり、
クラスターkに割り当てられた要素のセットであり、  クラスターkのi番目の要素です。
クラスターkのi番目の要素です。
平均距離の検索に関しては、メトリック関数が連続的かつ微分可能であれば、クラスターイドを検索するために、勾配降下アルゴリズムを使用して次のコスト関数を最小化できることに注意する価値があります。
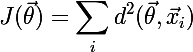 ここで、xは現在のクラスターに割り当てられた要素です。 次の記事でこのオプションを検討する予定ですが、現時点では実装の際に、いくつかのメトリックに対してメトリック/クラスタイド検索メソッドがすぐに追加されることを考慮します。
ここで、xは現在のクラスターに割り当てられた要素です。 次の記事でこのオプションを検討する予定ですが、現時点では実装の際に、いくつかのメトリックに対してメトリック/クラスタイド検索メソッドがすぐに追加されることを考慮します。
指標
まず、メトリックの一般的なビューを作成してから、一般的なロジックといくつかのメトリックの具体的な実装を実装しましょう。
public interface IMetrics<T> { double Calculate(T[] v1, T[] v2); T[] GetCentroid(IList<T[]> data); }
したがって、メトリックはデータ型から抽象化され、数値ベクトル間のユークリッド距離および行と文間のレーベンシュタイン距離として実装できます。
次に、上記の簡単な方法でclusteroid検索関数を実装するメトリックの基本クラスを作成します。
public abstract class MetricsBase<T> : IMetrics<T> { public abstract double Calculate(T[] v1, T[] v2); public virtual T[] GetCentroid(IList<T[]> data) { if (data == null) { throw new ArgumentException("Data is null"); } if (data.Count == 0) { throw new ArgumentException("Data is empty"); } double[][] dist = new double[data.Count][]; for (int i = 0; i < data.Count - 1; i++) { dist[i] = new double[data.Count]; for (int j = i; j < data.Count; j++) { if (i == j) { dist[i][j] = 0; } else { dist[i][j] = Math.Pow(Calculate(data[i], data[j]), 2); if (dist[j] == null) { dist[j] = new double[data.Count]; } dist[j][i] = dist[i][j]; } } } double minSum = Double.PositiveInfinity; int bestIdx = -1; for (int i = 0; i < data.Count; i++) { double dSum = 0; for (int j = 0; j < data.Count; j++) { dSum += dist[i][j]; } if (dSum < minSum) { minSum = dSum; bestIdx = i; } } return data[bestIdx]; } }
GetCentroidメソッドでは、残りのデータ要素までの距離の2乗の合計が最小になる要素を探します。 まず、要素が対応するデータ要素間の距離を含む対称行列を作成します。 メトリックスのプロパティを使用して:d(x、x)= 0およびd(x、y)= d(y、x)、対角線を安全にゼロで満たし、主対角線に沿って行列を反映できます。 次に、線を合計して最小値を探します。
たとえば、マハラノビスとユークリッドの距離の実装を作成しましょう。
internal class MahalanobisDistanse : MetricsBase<double> { private double[][] _covMatrixInv = null; internal MahalanobisDistanse(double[][] covMatrix, bool isInversed) { if (!isInversed) { _covMatrixInv = LinearAlgebra.InverseMatrixGJ(covMatrix); } else { _covMatrixInv = covMatrix; } } public override double Calculate(double[] v1, double[] v2) { if (v1.Length != v2.Length) { throw new ArgumentException("Vectors dimensions are not same"); } if (v1.Length == 0 || v2.Length == 0) { throw new ArgumentException("Vector dimension can't be 0"); } if (v1.Length != _covMatrixInv.Length) { throw new ArgumentException("CovMatrix and vectors have different size"); } double[] delta = new double[v1.Length]; for (int i = 0; i < v1.Length; i++) { delta[i] = v1[i] - v2[i]; } double[] deltaS = new double[v1.Length]; for (int i = 0; i < deltaS.Length; i++) { deltaS[i] = 0; for (int j = 0; j < v1.Length; j++) { deltaS[i] += delta[j]*_covMatrixInv[j][i]; } } double d = 0; for (int i = 0; i < v1.Length; i++) { d += deltaS[i]*delta[i]; } d = Math.Sqrt(d); return d; } }
コードからわかるように、GetCentroidメソッドはオーバーライドされませんが、次の記事では勾配降下アルゴリズムを使用してこのメソッドをオーバーライドしようとします。
internal class EuclideanDistance : MetricsBase<double> { internal EuclideanDistance() { } #region IMetrics Members public override double Calculate(double[] v1, double[] v2) { if (v1.Length != v2.Length) { throw new ArgumentException("Vectors dimensions are not same"); } if (v1.Length == 0 || v2.Length == 0) { throw new ArgumentException("Vector dimension can't be 0"); } double d = 0; for (int i = 0; i < v1.Length; i++) { d += (v1[i] - v2[i]) * (v1[i] - v2[i]); } return Math.Sqrt(d); } public override double[] GetCentroid(IList<double[]> data) { if (data.Count == 0) { throw new ArgumentException("Data is empty"); } double[] mean = new double[data.First().Length]; for (int i = 0; i < mean.Length; i++) { mean[i] = 0; } foreach (double[] item in data) { for (int i = 0; i < item.Length; i++) { mean[i] += item[i]; } } for (int i = 0; i < mean.Length; i++) { mean[i] = mean[i]/data.Count; } return mean; } #endregion }
ユークリッド距離の実装では、GetCentroidメソッドがオーバーライドされ、正確な重心値が検索されます。各座標の平均値が計算されます。
クラスタリング
クラスタリングアルゴリズムの実装に移りましょう。 繰り返しますが、最初にクラスタリングアルゴリズムのインターフェイスを作成します。
public interface IClusterization<T> { ClusterizationResult<T> MakeClusterization(IList<DataItem<T>> data); }
クラスタリングの結果は次のとおりです。
public class ClusterizationResult<T> { public IList<T[]> Centroids { get; set; } public IDictionary<T[], IList<DataItem<T>>> Clusterization { get; set; } public double Cost { get; set; } }
そして、データ要素クラス:
public class DataItem<T> { private T[] _input = null; private T[] _output = null; public DataItem(T[] input, T[] output) { _input = input; _output = output; } public T[] Input { get { return _input; } } public T[] Output { get { return _output; } set { _output = value; } } }
Inputプロパティにのみ関心があります。なぜなら これは教師なしのトレーニングです。
上記のインターフェースを使用したk-meansアルゴリズムの実装に移りましょう。
internal class KMeans : IClusterization<double>
次のデータがクラスタリングアルゴリズムの入力に供給されます(初期重心の初期化方法に
IClusterization):
clusterCount - IMetrics metrics -
れないようにコードを少しカットしました。ランダムポイント初期化を使用します
IClusterization):
clusterCount - IMetrics metrics -
数値データをクラスタリングしているため、ここで余裕があります
IClusterization):
clusterCount - IMetrics metrics -
IClusterization):
clusterCount - IMetrics metrics -
-
IClusterization):
clusterCount
-IMetrics metrics -
-
IClusterization):
clusterCount
-IMetrics metrics -