ところで、記事と研究は興味深い世論調査によって生み出されたものであり、「出版物へのアクセスが閉鎖されている」という不満はあなたを困らせますか? およびdotneterユーザースクリプト-habrahabr.ru/post/146070/#comment_4914947によるコメント。
もちろん、より高品質のサービスが必要です。したがって、現在の控えめな機能(Googleキャッシュおよびいくつかのコピーサイトで見つかる可能性)の説明に加えて、記事でクラウドソーシングの問題を提起します。さらに、このソリューションは、コンテンツコピーサービスを利用しているユーザーに近いようです。 しかし、すべてを順番に話しましょう。現在提案されているすべてのソリューションを検討してください。
Googleキャッシュ
Yandexのキャッシュとは異なり、リンクを介して直接アクセスできるため、ユーザーに「[コピー]ボタンをクリックして」と尋ねる必要はありません。 ただし、よく知られているarchive.orgのようなすべてのキャッシュには、多くの不要な機能があります。
1)表示されるリンクを即座に繰り返しコピーする時間がない。 人気のあるサイトに頻繁にアクセスし、2時間以上は新しいページをキャッシュするという事実に敬意を表します。 期限内にそれぞれ。
2)さらに、「アクセスは閉じられています」と言って、空白のページを少し後でキャッシュできるとんでもない機能があります。
3)したがって、キャッシュの結果は非常に幸運です。 本当に必要な場合は、このようなキャッシュリンクをすべてバイパスできますが、すぐに消えるか、空白ページの「より関連性のある」意味のないコピーに置き換えられる可能性があるため、そこから情報をコピーする必要があります。
キャッシュarchive.org
それは検索エンジンの能力よりも少ない能力でインターネット全体で動作するので、遠くのロシア語サイトのページにアクセスすることはめったにありません。 頻度はここで見ることができます: wayback.archive.org/web/20120801000000*/http : //habrahabr.ru
また、このサイトの目的は、各サイトのすべてのイベントではなく、Webの履歴の断片をキャプチャすることです。 したがって、有用な情報が得られることはほとんどありません。
Yandexキャッシュ
直接リンクはないので、(最も簡単な)ユーザーに検索ページの「コピー」リンクをクリックするように依頼する必要があります。このページでは、この記事だけが表示されます(Yandexに表示する時間があった場合)。
経験によれば、記事が数時間ハングし、作成者によって閉じられた記事は、検索エンジンのキャッシュに正常に保存されます。 その後、ほとんどの場合、すぐに空のものに置き換えられます。 もちろん、これらすべては、当然のことながら、Webユーザーに適したものではありません。Webユーザーは、当然のことながら、取得した情報を保存する必要があります。
Yahooパイプ
pipes.yahoo.com/pipes/search?q=habrahabr+full&x=0&y=0など。
かなり興味深いソリューション。 それらの設定方法を知っている人は、RSSのアーカイブの問題を完全に解決できるかもしれません。 既存のものから、その番号で記事を検索するパイプが見つからなかったため、そのような保存された記事全体への直接リンクはありません。 (彼と一緒に仕事をする方法を知っている人-スクリプトのそのようなリンクを作成してください。)
多数のクローン
それらはすべて、記事へのリンクをその番号で提供せず、記事の全文を提供せず、一部は一般に「強化」または「怠け者」に限定されるという事実に苦しんでいます。いつも。 ただし、少なくとも1人のコピーライター作成者がエンジンを微調整して、完全かつ最新のコンテンツを保持する場合、彼は貴重なサービスをインターネットに提供し、そのサービスがHabrAjaxスクリプトの主要な位置を占めます。
生きているうちに、私はこれまでに4を見つけました。長い間存在していた(itgator)のいくつかは現在動作していません。 一般に、これまでのところほとんど役に立たないのは、ユーザーが閉じたページにアクセスしたアドレスではなく、名前またはキーワードで記事を検索するように強制するためです(単語によると、1つのサイトだけでなくYandexを完全に検索します)。 いくつかの有用な情報については、スクリプトにリストされています。
挑戦する
コミュニティは、サイトのオーガナイザーを煩わせることなく、情報を失わない品質のリソースに製品を提供するというタスクに直面しています。 そのためには、調査へのコメントに正しく記載されているように、 関連する本格的な記事のアーカイバが必要です(同時にそれらへのコメントも必要です)。
現在、上記の不完全なソリューションは次のようになっています。
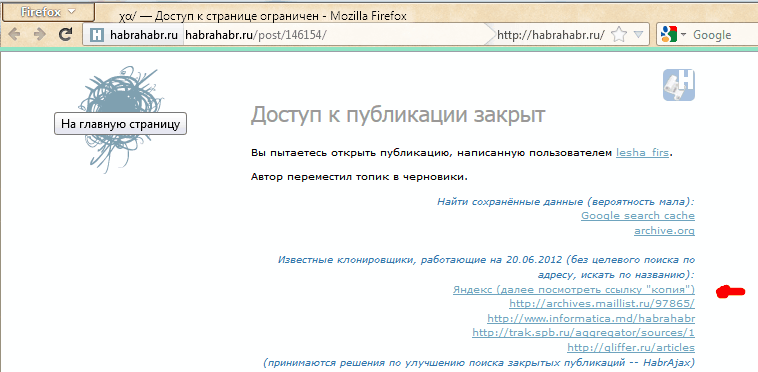
Yandexで検索すると、選択したアドレスには単一のリンクが表示されます(または何も表示されません)。

「コピー」リンクをクリックすると、保存されたコピーが表示されます(運がよければ)(現在の例でのみページが選択されています):
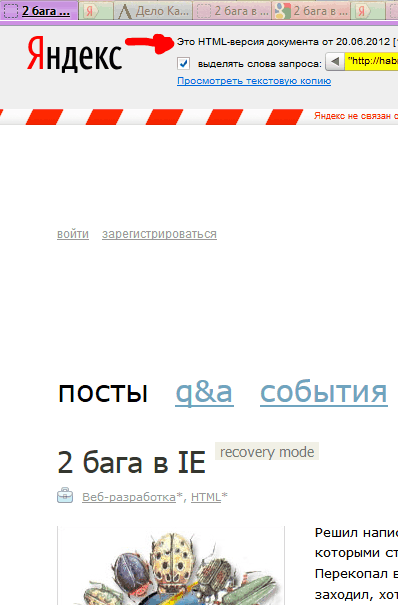
Googleでは、少し簡単です。幸運にもすぐにコピーを取得できます。Googleは、不足しているページを取得せずに、必要なものを正確に保存できました。
この場合、スクリプトが「代替サービスの選択」を提供するのは面白いことです(「予防作業」)。

サービスとコピーリスト(または少なくともプロジェクト)の追加に関する提案を待っています(許可されていないユーザー向け-有名なGoogleリソースのspmbt0メールに、便利な形式を選択します)。
UPD 23:00:経験的にmail.ruの場合、キャッシュへの直接リンクの構造が判明しました。
'http://hl.mailru.su/gcached?q=cache:'+ window.location
スクリプト更新(habrAjax) (0.861)に電子メールおよびVKリンクを追加しました。現在、さらに2行あります。