私たちの最愛のアンドリューNgによって具体的に公開されたこの事実の新しい実験的確認を提案します。
著者たちは、いかなる方法でもマークされていない膨大な数の画像に基づいて、人間の顔の検出器を構築するために大規模な実験を行いました。 9層のニューラルネットワークは、局所受容フィールドを持つスパースオートエンコーダーの構造で構築されました。 ニューラルネットワークは、それぞれが16コアである1000台のコンピューターのクラスターに実装され、ニューロン間の10億の接続を含みます。 ネットワークをトレーニングするために、YouTubeビデオからランダムに取得した200x200ピクセルの1,000万フレームを使用しました。 非同期勾配降下トレーニングには3日かかりました。
教師とは関係なく、直感に反して、マークされていないサンプルでトレーニングを行った結果、ネットワークの出力層でニューロンが選択されました。ニューロンは画像内の顔の存在に選択的に反応します。 制御実験により、この分類器は画像フィールド上の顔の変位だけでなく、スケーリングや画像平面外の3D回転に対しても耐性があることが示されました! このニューラルネットワークは、人物や猫などのさまざまな高レベルの概念を認識することを学習できることが判明しました。
記事の全文は、 リンクを参照してください 、ここで簡単に言い直します。
コンセプト
神経生物学では、人間の顔などの特定の一般化されたカテゴリに対して選択的な脳内の個々のニューロンを区別できると考えられています。 それらは「祖母のニューロン」とも呼ばれます。
人工ニューラルネットワークでは、標準的なアプローチは教師とのトレーニングです。たとえば、人間の顔の分類子を構築するには、顔のセットと、顔を含まない画像のセットを取得します。各画像は「顔」-「顔ではない」とラベル付けされます。 ラベル付けされたトレーニングデータの大規模なコレクションの必要性は、大きな技術的問題です。
この論文では、著者は2つの質問に答えようとしました:ラベル付けされていないデータから顔を認識するようにニューラルネットワークをトレーニングすることは可能か、ラベル付けされていないデータで「祖母のニューロン」の自己トレーニングの可能性を実験的に確認できるかどうか これは、原則として、教師の介入なしに、乳児が同様の画像(たとえば、顔)をグループ化するために独立して訓練されるという仮説を確認します。
トレーニングデータ
トレーニングセットは、1000万のYouTubeビデオの1つのフレームをランダムにサンプリングしてコンパイルされました。 サンプル内の重複を避けるため、各ビデオから1つのフレームのみが取得されました。 各フレームは200x200ピクセルのサイズにスケーリングされました(これは、説明された実験を、通常32x32フレームなどで動作するほとんどの認識作業と区別します)。トレーニングセットの典型的な画像を次に示します。
アルゴリズム
実験の基礎は、スパース自動エンコーダー(ハブで説明 )です。 浅い深さの自動エンコーダーを使用した初期の実験では、ガボールフィルターに類似した低レベルの特徴(セグメント、境界など)の分類器を取得することができました。
説明されているアルゴリズムは、多層自動エンコーダーといくつかの重要な特徴的な機能を使用しています。
- 局所受容野
- プーリングフレーム
- コントラストの局所正規化。
局所受容野は、大きな画像のニューラルネットワークをスケーリングします。 フレームをプールし、コントラストをローカライズすることにより、動きの不変性と局所的な変形が可能になります。
使用される自動エンコーダーは3つの繰り返しレイヤーで構成され、各レイヤーは同じサブレベルを使用します:ローカルフィルタリング、ローカルプーリング、コントラストのローカル正規化。
この構造の最も重要な特徴は、ニューロン間のローカル接続です。 最初のサブレベルでは18x18ピクセルの受容フィールドを使用し、2番目のサブレベルでは5x5の隣接する領域のフレームを組み合わせます。 ローカル受容フィールドは畳み込みを使用しないことに注意してください。 各再帰フィールドのパラメーターは繰り返されず、一意です。 このアプローチは生物学的プロトタイプにより近いものであり、より多くの不変条件を学ぶこともできます。
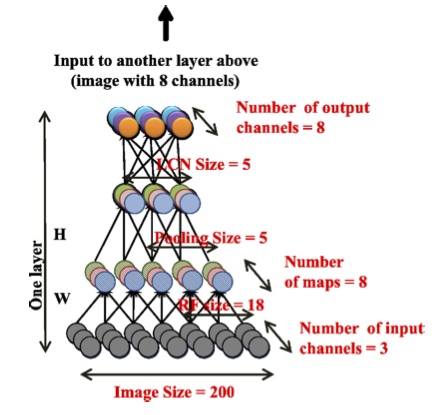
コントラストの局所的な正規化も、生体視路のプロセスを模倣します。 各ニューロンの活性化から、隣接するニューロンの活性化の加重平均値(ガウスの重み)が減算されます。 次に、近隣のニューロンの活性化のローカルrms値に従って正規化が実行されます。これは、ガウスで重み付けされています。
ネットワークをトレーニングするときの目的関数は、スパースオートエンコーダーによって元の画像を再現する際のエラーの値を最小化します。 最適化は、非同期勾配降下(非同期SGD)を使用して、管理対象のすべてのネットワークパラメーター(10億を超えるパラメーター)に対してグローバルに実行されます。 このような大規模な問題を解決するために、ニューラルネットワークの局所的な重みがさまざまなマシンに分散されるという事実からなるモデルの並列性が実装されました。 モデルの1つのインスタンスは、それぞれ16個のプロセッサコアを備えた169台のコンピューターに分散されています。
学習プロセスをさらに並列化するために、モデルの複数のインスタンスを使用した非同期勾配降下が実装されています。 説明した実験では、トレーニングサンプルは5つの部分に分割され、各部分はモデルの個別のコピーでトレーニングされました。 モデルは、更新されたパラメーター値を中央の「パラメーターサーバー」(256サーバー)に送信します。 簡略化されたプレゼンテーションでは、100シリーズのミニシリーズを処理する前に、モデルはパラメーターサーバーにパラメーターを要求し、学習(パラメーターの更新)して、パラメーターグラデーションをパラメーターサーバーに転送します。
このような非同期勾配降下は、個々のネットワークノードの障害に対して耐性があります。
この実験を行うために、DistBeliefフレームワークが開発されました。これは、パラメーターサーバーへの要求のディスパッチを含む、クラスター内の並列コンピューター間のすべての通信問題を解決します。 学習プロセスは3日間続きました。
実験結果
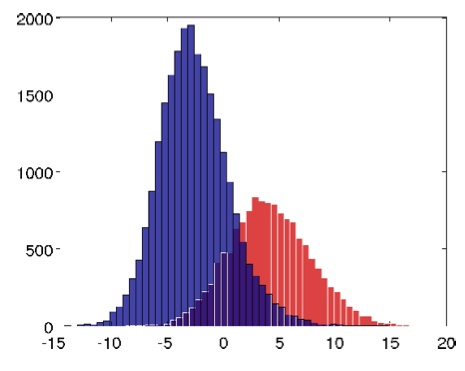
驚くべきことに、学習過程でニューロンが形成され、その最良のものは顔認識の81.7%の精度を示しました。 活性化レベルのヒストグラム(ゼロのしきい値に対する)は、テストサンプル内の画像が「祖母ニューロン」の1つまたは別の活性化を引き起こした数を示します。 青色は顔を含まない画像(ランダム画像)を示し、赤色は顔を示します。
分類器が顔認識専用に訓練されていることを確認するために、2つの方法を使用して訓練されたネットワークを視覚化しました。
最初の方法は、分類器ニューロンの最大の活性化を引き起こしたテスト画像の選択です。

2番目のアプローチは、最適な刺激を得るための数値最適化です。 勾配降下法を使用して、ニューラルネットワークの指定されたパラメーターの分類器の出力アクティベーションの値を最大化する入力パターンが取得されました。

実験の結果に関するより詳細な定量的推定と結論については、元の記事を参照してください。 私自身、大規模な計算実験により、教師なしでニューラルネットワークを自己学習できる可能性が証明されたこと、およびこのネットワークのパラメーター(特に、層と相互接続の数)が生物学的値にほぼ対応していることに注目したいと思います。