Javaを使用した主要な圧縮アルゴリズムの短いレビューとテスト結果を投稿します。
それが面白い人に私はキャットの下で尋ねます、誰にではありません-マイナスにしないで、主題がhabrの価値がないと言う要求-私はドラフトコピーで削除します。
だから:
- SteriaLZHはlzhアルゴリズムの実装です。このアルゴリズムは、現在会社が取り組んでいるプロジェクトに関連しており、そのために最適な代替案を見つけるタスクがありました。
- 見つかったすべてのアルゴリズムがテストされたわけではありません(ファイル圧縮、データの実装)。 たとえば、JCraftのJZipなど、テストしたすべてのものがタブレットに表示されます。
- 圧縮のみがテストされ、解凍はテストされていません。
- テスト中に、圧縮率、最小時間[ms]、平均時間[ms]、中央時間[ms]、最大時間[ms]の5つのパラメーターが計算されました。
- 優れたコンプレッサーは、10回ではなく、1000回ファイルを実行しました。以下は、何が、どれだけ、なぜかというプレートです。
- stream-実装(アルゴリズム):ファイル名を受け入れ、それに応じてInputStreamでファイルを読み取り、OutputStreamを使用して作成(保存)します。
- ブロック-実装(アルゴリズム):ファイルをバイト[]として受け入れ、圧縮し、圧縮されたバイト[]を取得します。
- ストリーム圧縮中、圧縮ファイルは再作成される前に削除されました。
- 動作中のLenovo Thinkpad T420(Intel Core i5-2540M、CPU 2.6GHz、4 GR RAM)、WinXP:SP3でテスト済み。
プレート、何を何回実行したか:
Steria.LZH 100
java.util.zip.GZIP(ストリーム)1000
java.util.zip.Deflater.BEST_COMPRESSION(ブロック)1000
java.util.zip.Deflater.BEST_SPEED(ブロック)1000
java.util.zip.Deflater.HUFFMAN_ONLY(ブロック)1000
apache.commons.compress.BZIP2(ストリーム)10
apache.commons.compress.GZIP(ストリーム)1000
apache.commons.compress.XZ(ストリーム)10
com.ning.LZF(ブロック)1000
com.ning.LZF(ストリーム)10
QuickLZ(ブロック)1000
org.xerial.snappy.Snappy(ブロック)1000
これが測定の方法です。
コードは私が作成したもので、それぞれに独自のスタイルがあります。 ですから、CORRECTNESSにはあまり議論しないようお願いします。
time:個々のアルゴリズム(実装)ごとに、呼び出したパブリック関数を使用してクラスを作成し、引数またはファイルまたはバイト[]へのパスとして渡します。
start = System.nanoTime(); byte[] compressedArray = compressor.compressing(arrayToCompress); end = System.nanoTime(); resultTime = end - start; start = System.nanoTime(); compressor.compressing(fileToCompress); end = System.nanoTime(); resultTime = end - start;
測定最小時間[ms]、平均時間[ms]、中央時間[ms]、最大時間[ms]:ArrayListでは、特定のファイルのすべての測定時間値を取得しました。
private void minMaxMedianAverCalculation(int element) { ResultsSaver resultsSaver = (ResultsSaver) compressorsResults.get(activeTest); ArrayList<Long> elementsList = new ArrayList<Long>(); for (int i = 0; i < TEST_COUNT; i++) { long timeElement = resultsSaver.getNanoSecondsTime(i, element); elementsList.add(timeElement); } Collections.sort(elementsList); this.min = (elementsList.get(0)) / 1000000; this.max = (elementsList.get(elementsList.size() - 1)) / 1000000; int elementsListLength = elementsList.size(); if (elementsListLength % 2 == 0) { int m1 = (elementsListLength - 1) / 2; int m2 = m1 + 1; this.median = ((elementsList.get(m1) + elementsList.get(m2)) / 2) / 1000000; } else { int m = elementsListLength / 2; this.median = elementsList.get(m) / 1000000; } long totalTime = 0; for (int i = 0; i < elementsListLength; i++) { totalTime += elementsList.get(i); } this.average = (totalTime / TEST_COUNT)/1000000; }
ストリーム圧縮率の測定:
private void setStreamCompressionRatio(String toCompressFileName, String compressedFileName) { ResultsSaver resultsSaver = (ResultsSaver) compressorsResults.get(activeTest); File fileToCompress = new File(toCompressFileName); long fileToCompressSize = fileToCompress.length(); File compressedFile = new File(compressedFileName); long compressedFileSize = compressedFile.length(); double compressPercent = Math.round(((double) compressedFileSize * 100) / fileToCompressSize * 100) / 100.0d; resultsSaver.setCompressionRatio(compressPercent); }
ブロック圧縮率の測定:
private void setBlockCompressionRatio(byte[] arrayToCompress, byte[] compressedArray) { ResultsSaver resultsSaver = (ResultsSaver) compressorsResults.get(activeTest); long arrayToCompressSize = arrayToCompress.length; long compressedArraySize = compressedArray.length; double compressPercent = Math.round(((double) compressedArraySize * 100) / arrayToCompressSize * 100) / 100.0d; resultsSaver.setCompressionRatio(compressPercent); }
圧縮されたもの:
TextDat_1Kb.txtは、Wikipediaの記事のプレーンテキストです。
TextDat_100Kb.txt-いくつかのウィキペディアの記事の簡単なテキスト。
TextDat_1000Kb.txt-いくつかのウィキペディアの記事の簡単なテキスト(英語、ドイツ語、スペイン語..)。
PdfDat_200Kb.pdf-* .docと同じだけが変換されてフィットします。
PdfDat_1000Kb.pdf-* .docと同じだけが変換され、適合します。
PdfDat_2000Kb.pdf-* .docと同じ。変換および調整されたサイズのみ。
HtmlDat_10Kb.htm-タグ付きの写真を含まない一部のドキュメントのテキスト、次にフォーマットされたhtml。
HtmlDat_100Kb.htm-タグ付きの写真を含まない一部のドキュメントのテキスト。その後、HTMLをフォーマットします。
HtmlDat_1000Kb.htm-タグ付きの写真を含まない一部のドキュメントのテキスト、次にhtmlのフォーマット。
ExcelDat_200Kb.xls-excel関数random()により0から1までの乱数が詰め込まれています。
ExcelDat_1000Kb.xls-0から1までの乱数でパックされ、Excel関数random()。
ExcelDat_2000Kb.xls-excel関数random()によって0から1までの乱数が詰め込まれています。
DocDat_500Kb.doc-ウィキペディアの記事のテキストといくつかの図面(英語、ドイツ語、スペイン語..)。
DocDat_1000Kb.doc-Wikipediaの記事のテキストといくつかの図面(英語、ドイツ語、スペイン語..)。
DocDat_2000Kb.doc-Wikipediaの記事のテキストといくつかの図面(英語、ドイツ語、スペイン語..)。
HtmDat_30000Kb.htm-フォーマットされたテキストと数字付きのテーブル。
III、結果:habrastorage.org-このような写真を発行し、フルサイズの1800 * 615、クリックで増加させる方法を誰もが知ることができますか?


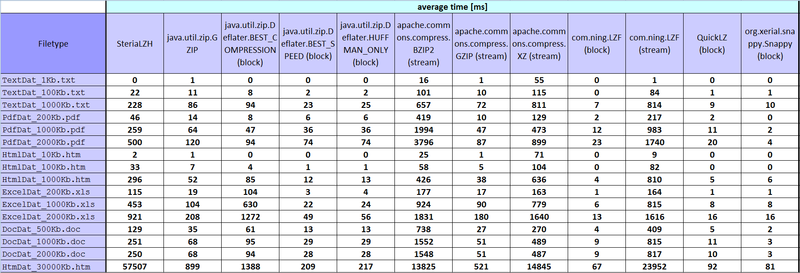


...
私はそれを正しくしましたが、正しくありませんでした。 アイデアを持っている人なら誰でも批判する準備ができています! スプレッド-誰かが役に立つかもしれません。
結果のいくつかは私にとって奇妙ですが、そのような数字は最終的に判明し、タブレットに入力されました。
Excelテーブルを慎重に挿入できるかどうかわからないので、写真を投げます。 誰かがExcelファイルを必要とする場合、問題なくアップロードします。
PSご清聴ありがとうございました。最後までお読みいただきありがとうございます。 :)