この記事では、IBM WebSphere Application Server 7アプリケーションサーバーインフラストラクチャのフォールトトレランスとスケーラビリティを確保するために利用可能なアプローチを説明します。
まず、使用する小さな用語:
高可用性は、一定期間にわたって高レベルのシステム可用性を実現できるシステム設計手法です。
ビジネスシステムの場合、高可用性とは、重要なビジネスシステムに冗長性を作成することです。 ルーター、ネットワークカード、またはロルグラムコンポーネントのいずれの障害であっても、1つのコンポーネントの障害はアプリケーションをクラッシュさせません。
可用性は、主に割合または「9」として表されます。
A = MTBF /(MTBF + MTTR)。
90%(「one nine」)-1週間あたり16.8時間のダウンタイム
99%(「ツーナイン」)-週1.7時間のダウンタイム
99.9%(「スリーナイン」)-年間8.8時間のダウンタイム
99.99%(「フォーナイン」)-年間53分のダウンタイム
MTBF (英語の平均故障間隔 )-停止間の平均作業時間。つまり、1つの故障の平均稼働時間を示します。
MTTR (英語の復元までの平均時間)-障害発生後に通常の操作を復元するのに必要な平均時間。
SPOF (英語の単一障害点 )-システムの一部。障害が発生するとシステムにアクセスできなくなります。
WAS -IBMのJ2EEアプリケーションサーバー。 いくつかの配信オプションがあります。
0. Community Edition-Apache Geronimoに基づくオープンソースプロジェクト。
1. Express-1ノード/ 1アプリケーションサーバー。
2.ベース-1ノード/ nアプリケーションサーバー。
3. Network Deployment(ND)-多数のアプリケーションサーバーからスケーラブルでフォールトトレラントなインフラストラクチャを構築するためのコンポーネントセットが含まれています。
4.その他の特定のオプション(z / OS、Hypervisor Edition、Extended Deploymentの場合)。
さらに、Network Deployment 7(WAS ND)のバージョンに関連するすべてを検討します。 現時点では、バージョン8.0および8.5はすでに存在しますが、記事で説明されているアプローチはそれらに適用できます。
Network Deploymentトポロジに関連する主な用語:
セル -展開マネージャー(展開マネージャー)と複数のノード(ノード)を含む組織単位。 Deployment Managerは、ノードエージェントを介してノードを管理します。
ノードは、すでに理解しているように、管理に使用されるノードエージェントと、1つ以上のアプリケーションサーバー(アプリケーションサーバー)で構成されます。
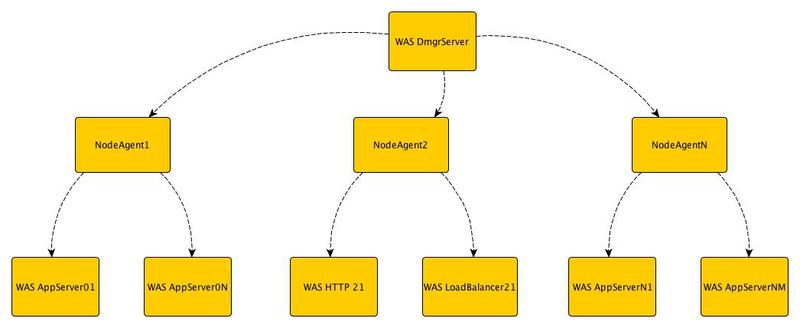
このような階層(セル/ノード/サーバー)は、サーバーのセット全体を整理し、機能と可用性の要件に従ってグループ化するのに役立ちます。
Application Server -JVM 5th Java EE仕様(WASバージョン8および8.5はJava EE 6仕様に準拠)
プロファイル -起動時に適用されるアプリケーションサーバー設定のセット。 JVMインスタンスの開始時に、その環境の設定がプロファイルから読み取られ、アプリケーションサーバーが実行する機能はそのタイプによって異なります。 デプロイメントマネージャー、ノードエージェント、アプリケーションサーバーは、プロファイルのプライベートな例です。 記事の後半で、異なるプロファイルを使用する理由とタイミング、それらが相互に作用する方法、およびそれらが達成できることを検討します。
スタンドアロンプロファイルはフェデレーションプロファイルとは異なり、複数のスタンドアロンプロファイルは異なる管理コンソールから管理され、フェデレーションプロファイルは単一ポイントから管理されるため、はるかに便利で高速です。
問題の声明
そのため、アプリケーションサーバーのインフラストラクチャで実行されている特定のビジネスシステムの高可用性を確保するタスクに基づいて、これらの要件を確実に満たすようなインフラストラクチャを構築する必要があります。
レベルI
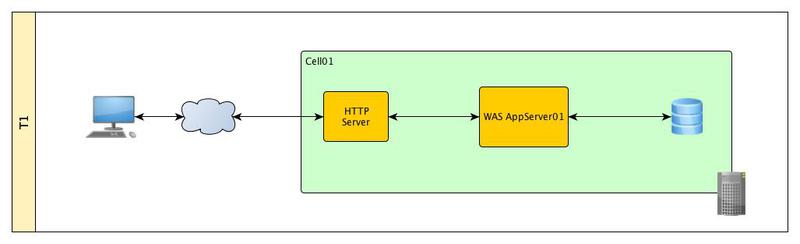
標準の3レベルアーキテクチャ。 管理コンソール、DBMS、およびHTTPサーバーとともに、スタンドアロンのWASプロファイルが配置されている1つの物理/仮想サーバーがあります。
この構成に存在する障害ポイントをリストし、レベルごとにそれらを排除しようとします。
1. HTTPサーバー。
2.アプリケーションサーバー。
3.データベース。
4.サーバーとソフトウェアインフラストラクチャの他のコンポーネント(ファイアウォール、LDAPなど)との相互作用を保証するすべてのソフトウェアコンポーネント
5.ハードウェア。
レベルII
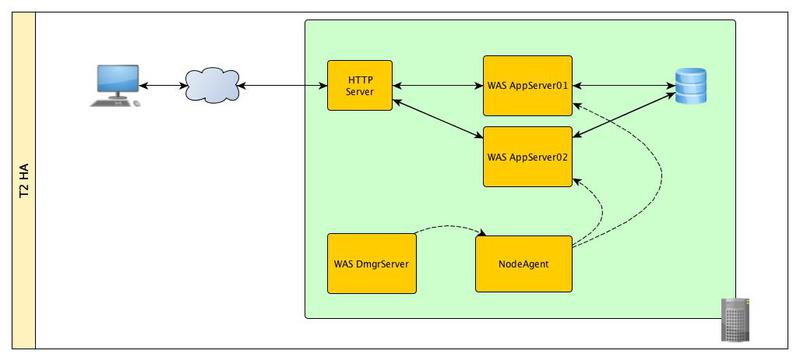
このレベルでは、唯一の障害点であるアプリケーションサーバーを排除します。 これを行うには、2つのアプリケーションサーバーのクラスターを作成し、それらを管理するために、さらに2つのコンポーネントが必要になります。
a)展開マネージャー。
b)管理エージェント。
展開マネージャーは、実際に、その制御下にあるすべてのアプリケーションサーバーの管理コンソールを統合する機能を実行します。 1つまたは複数のサーバーの構成を変更すると、設定はデプロイメントマネージャーから管理エージェントを介してサーバーに「下降」します。
いずれかのアプリケーションサーバーに障害が発生した場合、HAManagerは2番目のサーバー上のすべてのデータを自動的に回復します。
レベルIII

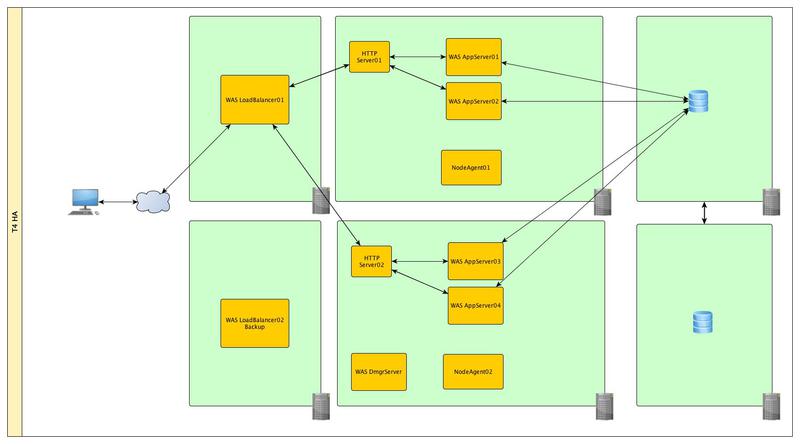
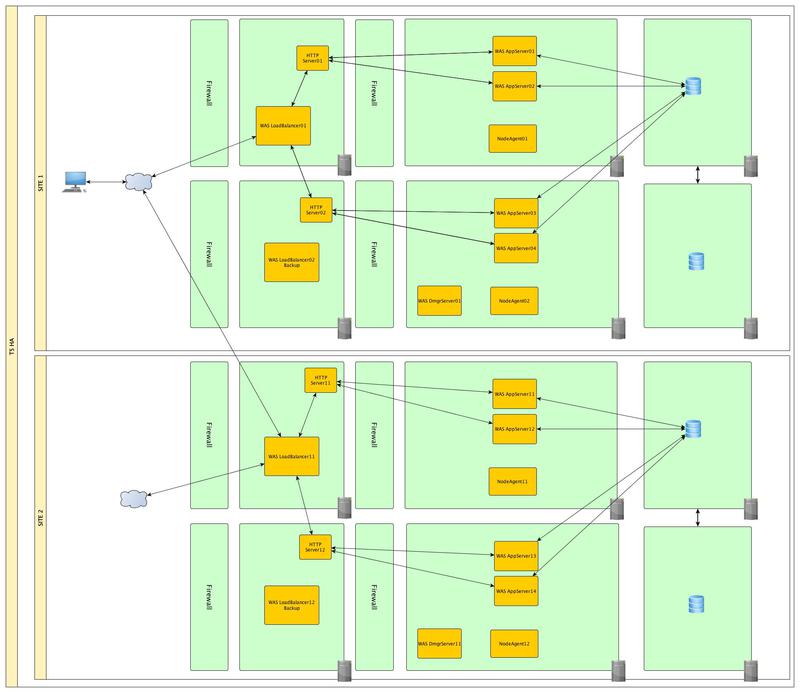
このレベルでは、複数の障害ポイント(HTTPサーバーと、アプリケーションサーバーが実行されている物理サーバー)を一度に閉じることができます。 これを行うには、データベースを物理サーバーの外部に移動します。 すでに2つのサーバーに2つのノードを展開し、それぞれに1組のアプリケーションサーバーを作成します。 そして、すべてのサーバーを単一のクラスターに統合します。 物理サーバーの1つに障害が発生すると、データとアプリケーションの状態が2番目のシステムに復元されます。 これに加えて、ロードバランサー(別の種類のプロファイル)を使用して、システム間で着信要求を分散できるため、負荷を分散し、アプリケーションのパフォーマンスを向上させることができます。 このトポロジを使用すると、新たに発生する可能性のある障害点-ロードバランサーを取得できます。
Tier VI
レベルIIIをバックアップロードバランサーで補完し、これに加えて、データベースの信頼性を確保します。 データベースのクラスタ化メカニズムを詳細に検討しません。 彼ら自身が別の記事に値する。
レベルv
そして最後の和音では、データセンターがあふれた場合に備えて、インフラストラクチャ全体を複製して移動します
これに加えて、フロントエンドサーバーをDMZゾーンに配置するのが適切でない場合があります。
合計
ご覧のとおり、重要なビジネスシステムの継続的な運用は非常にコストがかかるため、ソリューションの構築を開始する前に、すべてのリスクと実装の準備を評価する必要があります。
ご清聴ありがとうございました。