
こんにちは親愛なる読者!
特定の話者認識方法に関する興味深く有益な記事に注目します。 ほんの数か月前に、音声認識にチョークケプストラム係数を使用するという記事に出会いました。 彼女はおそらく構造の欠如のために応答を見つけませんでしたが、その中の資料は非常に興味深いものでした。 私はこの資料をアクセシブルな形で伝え、Habréでの音声認識のトピックを継続する責任を負います。
カットの下で、音声の録音と処理から音声で人を識別するプロセス全体について説明し、話者の身元を直接判断します。
録音
私たちの話は、マイクを使用して外部ソースからのアナログ信号を録音することから始まります。 このような操作の結果として、時間の経過に伴う音の振幅の変化に対応する一連の値を取得します。 このコーディング原理は、別名PCM(パルス符号変調)と呼ばれます。 ご想像のとおり、オーディオストリームから受信した生データは、この目的にはまだ適していません。 最初のステップは、いたずらなビットを意味のある値のセット、つまり信号振幅に変換することです。 [1、p。 31]入力として、サンプリング周波数16 kHzの非圧縮16ビット署名(PCM署名)wavファイルを使用します。
double[] readAmplitudeValues(bool isBigEndian) { int MSB, LSB; // byte[] buffer = ReadDataFromExternalSource(); // - double[] data = new double[buffer.length / 2]; for (int i = 0; i < buffer.length; i += 2) { if(isBigEndian) // { // MSB MSB = buffer[2 * i]; // LSB LSB = buffer[2 * i + 1]; } else { // LSB = buffer[2 * i]; MSB = buffer[2 * i + 1]; } // , 16- // - 2^15 data[i] = ((MSB << 8) || LSB) / 32768; } return data; }
ウィキペディアでバイト順に関する知識を更新できます。
音声処理
取得された振幅の値は、外部ノイズ、入力信号のボリュームの違い、およびその他の要因により、2つの同一レコードでも一致しない場合があります。 ノーマライゼーションは 、サウンドを「共通の分母」にするために使用されます。 ピークの正規化の考え方は単純です:すべての振幅を最大値(特定のサウンドファイル内)で除算します。 したがって、異なるボリュームで録音された音声サンプルをイコライズし、すべてを-1から1のスケールにしました。このような変換の後、音が指定された間隔を完全に満たすことが重要です。
私の意見では、正規化は最も簡単で効果的なサウンド前処理アルゴリズムです。 他にも多くの機能があります。特定の周波数を上回るまたは下回る周波数の「カットオフ」、スムージングなど。
分割して征服する
十分な最小サンプリング周波数(16 kHz)でサウンドを操作する場合でも、サウンドの2番目のサンプルのユニークな特性のサイズは非常に大きく、16,000の振幅値です。 このような大量のデータに対して複雑な操作を実行することはできません。 また、オブジェクトを異なる数のユニークな機能と比較する方法は完全には明確ではありません。
まず、問題を複雑さの低いサブタスクに分割することで、問題の計算の複雑さを軽減します。 サブタスクのサイズを固定し、すべてのタスクの計算結果を平均化することにより、事前に指定された数の分類の兆候を取得するため、この動きで1石で2羽の鳥を殺します。
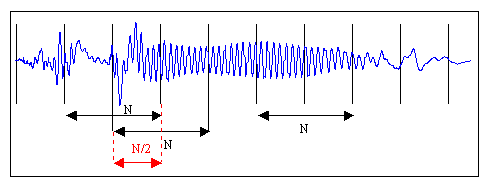
この図は、オーディオ信号を半分のオーバーラップで長さNのフレームに「カット」することを示しています。 オーバーラップの必要性は、フレームが近くにある場合の音の歪みが原因です。 実際には、この手法はコンピューティングリソースを節約するためにしばしば無視されますが。 推奨事項[1、p。 28]、精度(長いフレーム)と速度(短いフレーム)の間の妥協点として、128 msのフレーム長を選択します。 フレーム全体を占有しない音声の残りの部分は、ゼロで埋めて目的のサイズにするか、単に破棄することができます。
フレームをさらに処理する際に不要な影響を排除するために、フレームの各要素に特別な重み関数(「ウィンドウ」)を掛けます。 その結果、フレームの中央部分が選択され、エッジの振幅が滑らかに減衰されます。 これは、フーリエ変換を実行する際により良い結果を得るために必要です。なぜなら、それは無限に繰り返される信号に焦点を合わせているからです。 したがって、フレームはできるだけスムーズにドッキングする必要があります。 非常に多くのウィンドウがあります。 ハミングウィンドウを使用します。
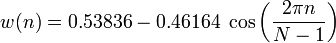
nは、新しい振幅値が計算されるフレーム内の要素のシリアル番号です
N-前と同様、フレームの長さ(一定期間に測定された信号値の数)
離散フーリエ変換
次のステップは、各フレームの短期スペクトログラムを個別に取得することです。 これらの目的のために、 離散フーリエ変換を使用します。

N-前と同様、フレームの長さ(一定期間に測定された信号値の数)
x nは、n番目の信号の振幅です。
X k-元の信号を構成する正弦波信号のN複素振幅
さらに、さらに対数を得るために各X k値を二乗します。
チョークスケールに行く
これまでのところ、最も成功しているのは、補聴器の構造に関する知識を使用する音声認識システムです。 Habréにはこれについていくつかの言葉があります。 要するに、耳は音を線形に解釈するのではなく、対数スケールで解釈します。 これまで、すべての操作を「ヘルツ」で実行してきましたが、「チョーク」に進みます。 グラフィックは依存関係を視覚化するのに役立ちます。

ご覧のように、チョークスケールは最大1000 Hzまで直線的に動作し、その後、対数的性質を示します。 新しいスケールへの移行は、単純な依存症によって説明されます。

m-チョークの頻度
f-ヘルツ単位の周波数
特徴ベクトルの取得
今、私たちはこれまで以上に目標に近づいています。 特徴ベクトルは、同じケプストラル係数で構成されます。 式[2]に従って計算します
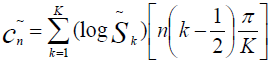
c n-チョークケプストラム係数n
S k-チョークのフレーム内のk番目の値の振幅
K-チョークケプストラム係数の所定の数
n∈[1、K]
原則として、数Kは 20に選択され、係数c 0は実際には入力信号の振幅を平均化するため、スピーカーに関する情報をほとんど伝えないため、1からカウントを開始します。 [2]
誰が同じことを言ったのですか?
最後の段階は、話者の分類です。 分類は、試行データと既知のデータとの類似性の尺度を計算することにより実行されます。 類似性の尺度は、テスト信号の特徴のベクトルから既に分類された特徴のベクトルまでの距離で表されます。 最も簡単なソリューション、つまり都市ブロックの距離に興味があります 。

このソリューションは、ユークリッド距離とは対照的に、離散的な性質のベクトルにより適しています。
気配りのある読者は、おそらく記事の冒頭の著者が音声フレームの特性の平均化について述べたことを覚えているでしょう。 そこで、このギャップを埋めて、いくつかのフレームといくつかの音声パターンの平均化された特徴ベクトルを見つけるためのアルゴリズムの説明で記事を完成させます。
クラスタリング
1つのサンプルの特徴ベクトルを見つけることは難しくありません。そのようなベクトルは、個々の音声フレームを特徴付けるベクトルの算術平均として表されます。 認識精度を高めるには、フレーム間で結果を平均するだけでなく、いくつかの音声サンプルのパフォーマンスも考慮する必要があります。 複数の音声録音があるため、指標を1つのベクトルに平均化するのではなく、たとえばk- means法を使用してクラスタリングを実行するのが妥当です。
まとめ
したがって、音声で人を識別するためのシンプルだが効果的なシステムについて話しました。 要約すると、認識プロセスは次のように構築されます。
- 音声のトレーニングサンプルをいくつか収集するほど、より良い結果が得られます。
- それぞれに特徴的な特徴ベクトルを見つけます。
- 著名な著者によるサンプルの場合、1つのセンター(平均化)または複数のセンターでクラスタリングを実行します。 許容できる結果は、各スピーカーに4つのセンターを使用することから始まります。 [2]
- 認識モードでは、テストベクトルからトレーニング中に学習したクラスター中心までの距離を見つけます。 どのクラスターテストスピーチがより近いか-そのようなスピーカーに、サンプルを帰属させます。
- 一定の信頼区間(試験サンプルがクラスターの中心から到達できる最大距離)を実験的に確立することもできます。 この値を超えた場合、サンプルを不明として分類します。
素材の改善に関する有益なコメントをいただければ幸いです。 ご清聴ありがとうございました。