タスクの説明
自転車を発明するのではなく、労働者の生活をデジタルに変換するだけです。 どの企業にもディレクターがいます-ディレクターが動いている場所を決定します。 ディレクターをシステムのユーザーのままにしておきましょう。 人事部門-彼らの仕事は、従業員の監視、解雇、雇用、人事記録の保持です。 このために特別なエージェントを選び、労働者を雇って解雇させます。 エージェントコーディネーターは、トップマネージャー、ディレクター、従業員の間の仲介者であり、これらのマネージャーもエージェントになります。
私たちが生産するものを理解することだけが残っています。 解決する必要がある問題は、ディレクターが正しい決定を下せるようにすることであり、おそらく、それらのいくつかを独立して実装することです。 そして、私たちと一緒にいるディレクターがアーカイブを管理し、次のいずれかのルールに基づいて、ドキュメントをリポジトリに配布します。 労働者の仕事は、これらのルールを保存、理解、適応、および適用することです。 したがって、一定量のドキュメントを最初に入力する際、従業員はアーカイブ内の新しいドキュメントを個別に配布する必要があります。 そして、ここにマルチエージェントシステムがありますか? 原則として、1つの事実ではないにしても、それとは何の関係もありません。 文書はまず、すべての机、引き出し、電話から世界中で収集する必要があります。次に、タイプごとにソートします。その後、おそらく主なことは分析と適合であり、その後リポジトリに送信します。 結局のところ、ソリューションの分析と適応を正しく行う方法はまだわかっていないため、先例に基づいた意思決定の理論を採用します。 そして、いくつかのパラメーターを取得します-誰が、いつ、誰に、何を転送し、作成したか。 「what」パラメータもそれほど明確ではないため、ここでも仮定を使用します。テキストでの使用頻度を考慮して、テキストから名詞のみを表現します。
その後、新しいドキュメントとリポジトリ内の既存のドキュメントの類似性を判断します。
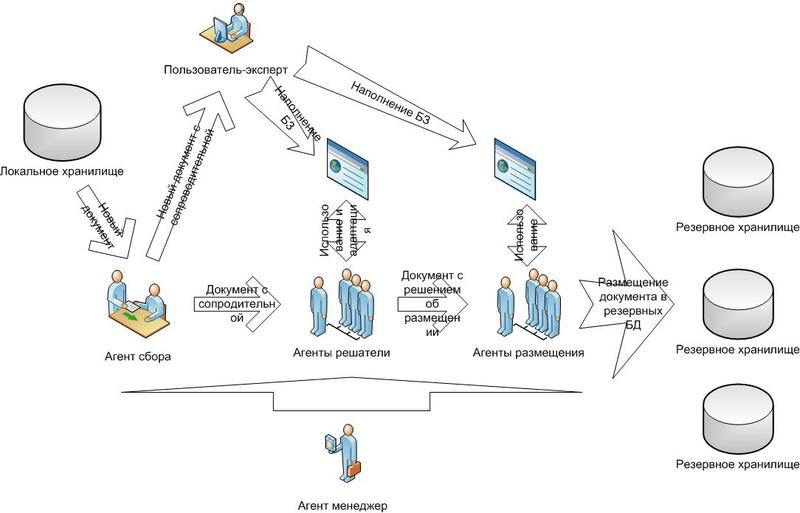
全体として、プロセスの次の参加者を強調しました。
1)収集エージェント。
2)エージェント、アナライザー、ソルバー。
3)スーパーユーザー-エキスパートとそのエージェント。
4)ストレージを担当するエージェント。
5)調整剤
なぜこの問題を解決するために正確にマルチエージェントアーキテクチャなのですか?
1)オブジェクト指向プログラミングのパラダイムからエージェント指向プログラミングのパラダイム(.NET、JADE、その他)に移行できるシンプルなソフトウェア設計ツールがあります。
2)クロスプラットフォームアプリケーションを作成する必要はなく、プラットフォームごとに独自のエージェントを作成するだけです。
3)大企業のすべてのプロセスの大規模な情報化、コンテンツ管理システム、文書管理システム、およびその他の情報処理システムの導入により、情報の一般化に困難が生じます。 エージェントシステムは互いに独立して動作します。 1つのエージェントのアクティビティは、システム全体のアクティビティに直接依存しません。 同じタスクの実行を複数のエージェントに同時に割り当てることができます。 この冗長性により、結果の保証が大きくなります。
4)タスクのソリューションを複数のエージェントに配布すると、さまざまなソースからの情報の処理を並列化できます。