これは何のためですか:
- テスト目的
- 共同開発用
- このデータを操作する一部のソフトウェアアルゴリズムの場合
また、作業中のドラフトのデータの信頼できる更新の問題は、モデルの更新と同様に深刻です。
このシステムでは、データの整合性を制御し、ダウンロードして更新し、リポジトリにデータを保存すると同時に、迅速かつ確実に動作できるアプローチを採用しています。
このようなストレージシステムはどのような要件を満たす必要がありますか?
最初に、データはバージョン管理されている必要があります。
第二に、保存されたデータは、たとえばバージョンを比較するために、人間が読めるものでなければなりません。
第三に、保存されたデータは動作中のシステムに簡単にロードされるべきです。
したがって、相互接続された数百のエンティティ、継承、階層ディレクトリなどを備えた典型的なERPシステムを検討してください。
経験の浅い開発者はどのソリューションを使用しますか? そうです、ベースダンプを作成して保存します。 私はそれを自分でやった:)
そのようなソリューションの欠点は何ですか:
1.バイナリバックアップは難しく、VCSに非効率的に保存されます
2.バックアップが大きくてテキストの場合-何が変わったのか把握するのが難しい
3.人が何かを読んで検索するのは難しい
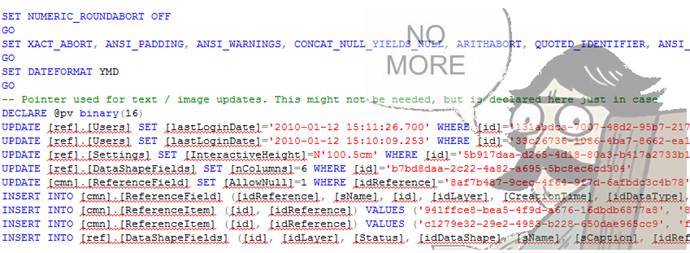
一般に、ダンプ/バックアップ/ SQLスクリプトは保存するのが不便であり、それらを理解することはさらに不便です。
XMLなどの構造化されたテキストにデータを保存する方がはるかに正確で便利です。 そのため、読みやすく、比較しやすく、VCSに保存されます。 データは 、新しいレコードを作成し、既存のレコードを更新するのと同じ方法で保存されます。
さらに、MS SQL / Postgresql / OracleはXMLをネイティブに解析でき、MS SQLはXMLをテーブルに直接ロードすることもできます。 概して、これは、ストレージ形式を選択する際のXMLの主な利点の1つでした。
ところで、これがAraxis Merge diffがXMLファイルに対して表示する方法です
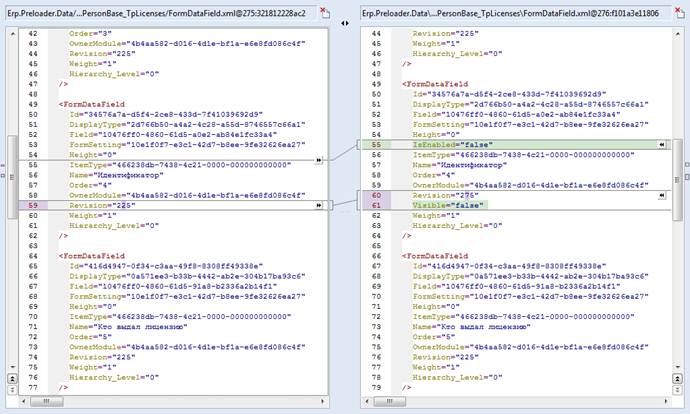
発生する唯一の質問は、依存関係、外部キー、および関係を考慮してロードすることはどのように幸せですか?
まあ...あなたはそれを最も簡単な方法で行うことができます: すべての外部キーを削除し、データをロードしてから、すべてのキーをその場所に戻します 繰り返しますが、この段階は私の人生で過ぎました:)
決定の短所:
1.キーを削除/作成するための複雑なロジック
2.データベース構造が複雑な場合、またはデータボリュームが大きい場合、キーの作成/削除プロセスに時間がかかることがあります
3.そして最も重要なこと:キーを復元する場合、 すべてのデータがロードされた後にのみエラーが表示されるため、エラーの場所を特定する方法はありません。
キーの削除/作成をなくし、可能であればロードの非常に早い段階でエラーを取得するにはどうすればよいですか?
このトピックを振り返ると、ダウンロードのために外部キーと制限を削除する必要はないという結論に達しました。 エンティティデータを正しい順序で読み込むだけです。
この場合、以下を考慮してください。
1.外部キー(これらはエンティティ参照でもあります)
2.エンティティの継承
3.階層エンティティ
4.可能なサイクル
これらの問題を解決するために、一連のエンティティをグラフ形式で提示し、 トポロジカルソートを適用しました。 その助けを借りて、すべての必要なデータが要素の読み込み時にすでに存在するように、読み込まれたすべてのエンティティをソートしました。
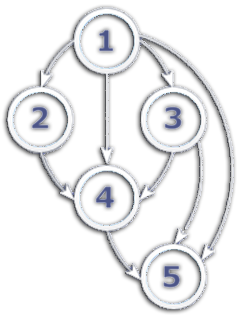
ネットワークにはこのアルゴリズムの実装が多数ありますが、使用されるORMに付属しているものを使用しました。 入力では、オブジェクトとそれらを接続するメソッドの列挙を受け取り、出力では、ソートされたリスト+ループがある場合は出力パラメーターを受け取ります。
次のようになります。
public static List<TNodeItem> Sort<TNodeItem>(IEnumerable<TNodeItem> items, Predicate<TNodeItem, TNodeItem> connector, out List<NodeConnection<TNodeItem, object>> removedEdges) {}
このアルゴリズムが機能するための主なことは、エンティティグラフとその関係を正しく表すことです。
私の場合、接続コネクタは次のようになります。
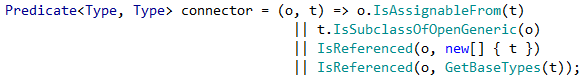
古代モルダヴィア語からの翻訳では、次の場合、タイプT はタイプOに依存します (方向付けられた接続を持っています)。
1. O 相続人
2. Tは、オープンジェネリックタイプOの継承またはクローズジェネリックタイプです。
3. TにはOにリンクフィールドがあります
4. Tの基本クラスには、Oを参照するフィールドがあります
最初の2つの条件が非常に明白な場合、リンクではすべてがそれほど単純ではありません。 サイクリックボンドを考慮する必要があります。 実際のシステムでは、エンティティ間のサイクルは珍しくなく、最も明らかな例は従業員-部署です。 従業員は部門に属しますが、部門には従業員でもあるヘッドがいます。
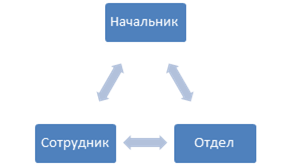
そのような接続は、ソートが機能するように強制的に切断する必要があります。 この例では、属性がEmployeeの「Department」フィールドに配置されています。これは、エンティティの関係を構築するときにこのフィールドが考慮されないことを示します。 ただし、このようなギャップが生じた後は、自動ロード中に入力できないフィールドに正しく入力するための小さなコードを作成する必要があります。
したがって、データを便利な形式で保存することができました。変更の表示と制御が簡単であり、必要に応じてデータベースにデータを正確かつ迅速にロードできます。 私もあなたにお願いします。