水平スケーリングはデータ共有に大きく依存しており、Windows Azureも例外ではありません。 プラットフォームのコンポーネントの1つは、無制限に成長するNoSQLデータベースであるAzure Storage Tableです。 しかし、多くの開発者は、使い慣れたSQLを支持してこれを無視しています。 同時に、Azure SQLを使用するよりもAzure Storage Tableを使用する方がはるかに効率的にタスクを解決できます。
ここでは、Azure Storage Tablesの実践と使用例を紹介します。
一般にAzureテーブルストレージについて
最も一般的な使用例はリストの保存です。 Azure Storage Tablesアーキテクチャに完全に適合します。 リストは大きく異なる可能性がありますが、最も一般的に使用されるのは日付ごとのレコードです。
作業中に最初に注意する必要があるのは、テーブルから値を選択する方法です。 いくつかの機能があります。
- 値は1000個以下の値で選択されます。
- パーティションキー(PartitionKey)なしのパーティション化は非常に遅いです。
- キーによって値の範囲を選択すると、条件「以下」が正しくトリガーされます。
Table Storageは任意の数のレコードと継続トークンを返すことができるため、サンプリングは常に部分的に行う必要があります。 ほとんどの場合、これは1000を超えるレコードがある場合に発生しますが、SDKにはこれを自動的に処理できるメカニズムがあるため、あまり心配する必要はありません。 各リクエストは追加のトランザクションであることを覚えておく必要があります。 サンプルに2001レコードがある場合、リポジトリへのアクセスが少なくとも3回あります。
また、PartitionKeyを覚えておく必要があります。 これは、データをセクションに分割する非常に重要なキーです。 リクエストで指定しない場合、クラウドストレージはすべてのセクションをポーリングし、1つのセットでデータを収集する必要があります。 さらに、異なるセクションを異なるサーバーに配置できます。 そして、これはあなたのリクエストにパフォーマンスを追加しません。 さらに、リポジトリへのトランザクションの数が増加します。
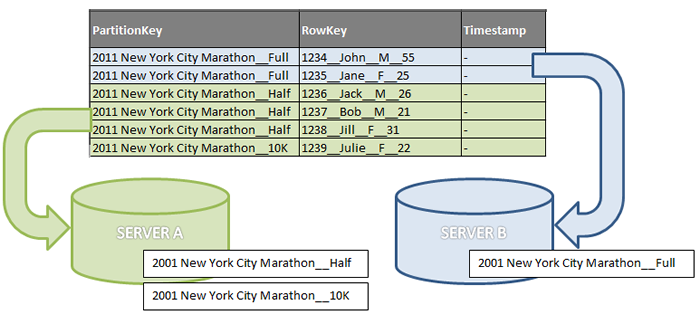
最後に、最も目立たない機能は、条件によるレコードの選択です。 RowKeyに条件「より小さい」または「以下」を指定すると、選択された値は最小値から条件を満足する値に変わることが実験的に判明しました。 この場合、返されるレコードの順序は小さい順になります。 つまり、条件を満たすレコードが10,000件あり、RowKeyが特定の値より小さい最初の100レコードのみが必要な場合、ストアはRowKeyの最小値から100レコードを選択します。
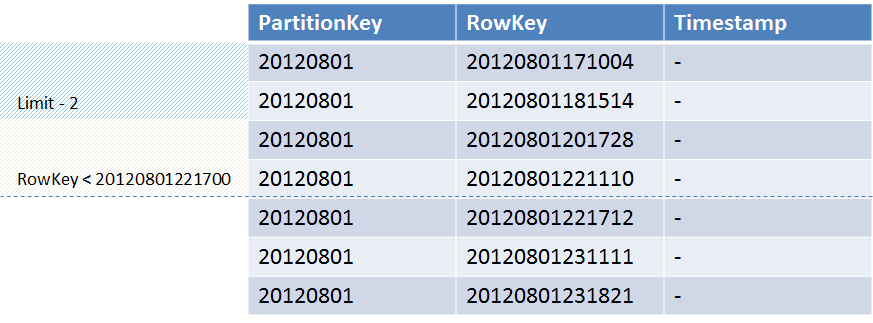
例として、日付のキーRowKeyを持つ複数のレコードが含まれるテーブルを考えます。 また、RowKeyが20120801221700未満の2つのレコードを選択する必要があります。ストアは、キー「20120801221110」および「20120801201728」を持つレコードを返すと予想されます。 ただし、ソート順に従って、ストアは値「20120801171004」および「20120801181514」を返します。
逆キーを使用すると、これを克服できます。 したがって、日付の場合、これはDateTime.MaxValue-CurrentDateTimeです。 次に、サンプリング時に反対の条件が使用され、正常に機能します。
パーティションキーの選択方法
アプリケーションを設計するときは、Microsoftがストレージテーブルに関して提供する推奨事項( http://msdn.microsoft.com/en-us/library/windowsazure/hh508997.aspx )に注目する必要があります。 これらの推奨事項の意味は非常に簡単です。 パーティションのキーが多すぎず、少なすぎないようにアプリケーションを設計します。 また、各セクションにエントリが多すぎないようにします。 セクション全体に均等に分散することをお勧めします。 パーティションの負荷を予測できる場合は、より高い負荷で適合するパーティションをより少ないエントリで埋める必要があります。 ストレージテーブルアーキテクチャに基づいて、負荷が高いパーティションは自動的に複製されます。 また、パーティションサイズが小さいほど、レプリケーションが高速になります。
開発中に、ユーザーの識別と認証のためにデータが保存されているテーブルのパーティションキーを選択する問題に直面しました。 まずユーザーを電子メールで識別するため、ユーザーをセクションに分割するシステムを選択する必要がありました。 少し実験を行った結果、MD5ハッシュとパーティション番号を決定するためのハッシュからのビットの一部のその後の割り当てが、良好な均一分布によって得られることがわかりました。
この単純なコードにより、MD5ハッシュから必要なビット数を取得し、セクション番号としてfromを使用できます。
using System.Security.Cryptography; using System.Text; public static string GetHashMD5Binary(string Input, int BitCount = 128) { if (Input == null) return null; byte[] MD5Bytes = MD5.Create().ComputeHash( Encoding.Default.GetBytes(Input)); int Len = MD5Bytes.Length; string Result = ""; int HasBits = 0; for (int i = 0; i < Len; i++) { Result += Convert.ToString(MD5Bytes[i], 2).PadLeft(8, '0'); HasBits += 8; if (HasBits >= BitCount) break; } if (BitCount < 1 || BitCount >= 128) return Result; return Result.Substring(0, BitCount); }
他の多くのメソッドと同様に、このメソッドはCPlaseEngineの一部として利用できます。CPlaseEngineへのリンクは記事の最後にあります。
その後、このプラクティスをシステムの他の部分に拡張し、非常に良い側面からそれを示しました。 場合によっては、ユーザーIDでセクションに分割するほうがより有益です。 またはユーザーIDの面で。 これにより、特定のユーザーのデータを選択するクエリを作成できます。 この場合、クエリは1つのセクションから選択する必要があるという意味で効果的です。
レコードのキーを選択する練習
前に見ることができるように、多くの場合、書き込みのキーは何らかの日付に関連付けられています。 ほとんどの場合、作成日。 私たちのシステムでは、これは非常に一般的です。 また、これはエントリに対して非常に効果的であり、後で何らかの日付からリストを取得する必要があります。
当然、レコードキーは一意である必要があります。 この一意性は、「パーティションキー」-「レコードキー」のペアに当てはまります。 したがって、キーを生成するときは、ランダムな文字をいくつか追加するのが最も安全です。
リスト形式のレコードを選択する場合、レコードキーを生成するための一般的な推奨事項は、リストを作成する対象のパラメーターにレコードキーを関連付けることです。 したがって、たとえば、日付ごとに値のリストを作成する場合、キーを生成するときに日付を使用するのが最善です。
配布と一般化
キーのハッシュで除算する方法は、テーブルストレージだけでなく適用できます。 ファイルシステムにも非常によく拡張されます。 エンティティをテーブルストレージからインスタンスのキャッシュにキャッシュする場合、ファイルパスからのハッシュパーティションも使用します。
水平スケーリングはデータ共有と密接に関連しており、データをより効率的に分離するほど、システム全体がより効率的に機能します。 プラットフォームとしてのWindows Azureは、信頼性が高くスケーラブルなフォールトトレラントサービスを構築するための非常に強力なインフラストラクチャを提供します。 ただし、同時に、そのようなサービスを構築するには、内部アーキテクチャが負荷の高いシステムを構築するという原則に準拠する必要があることを忘れないでください。
また、オープンソースプロジェクトCPlaseEngineがCodePlexのオープンアクセスに登場したことを喜んで報告したいと思います。 Windows Azureプラットフォームでより効率的にサービスを開発できるツールが含まれています。 https://cplaseengine.codeplex.com/からダウンロードできます。
シリーズを読む: