
一時停止-一時的な沈黙、音楽作品全体またはその一部、または個々の声の音の中断。
[ウィキペディア]
驚くべきことに、何かを全体としてより速くするためには、もっとゆっくり、または一時停止を伴う必要があることもあります。 たとえば、マルチスレッドコードでアクティブなスピンウェイト待機を実装する場合、一時停止命令を使用することをお勧めします。Intel命令セットリファレンスによれば、これはこの待機を最も効率的にします。 「なんてナンセンスだ!」とあなたは言います。 期待はどのように効果的ですか? マイクロプロセッサ開発者は、一時停止命令によるアクティブな待機により、Pentium 4の時からチップの消費電力が大幅に減ったと主張しています。 以下でそれについて話しましょう。
実際、この投稿では、スピン待機の実装の有効性を比較しません。これはもはや面白くありません。 私が興味深く思えたのは、並列OpenMPアプリケーションのプロファイリングの1つのケースを詳細に分析することです。単純に問題を想像すると、多くのスレッドが1つの共有リソースを奪い合っています。 同時に、このリソースの操作時間は、同期オーバーヘッドに比べて無視できます。 並列アプリケーションでのタスクの実装を設計する際にプログラマがミスを犯したことは明らかです。このようなエラーはしばしば発生し、ISNブロゴスフィア( 例 )で議論の対象となります。 しかし、プロジェクトは簡単ではなく、プロファイリングと分析に時間がかかったため、何が起こっているかをすぐに理解することはそれほど容易ではありませんでした。 問題の理解を促進し、テストを高速化するために、プログラムを単純なテストに減らしました。これを経験豊富な目で見れば、エラー自体がすぐに明らかになります。 しかし、それが私たち全員ができることであり、簡単なテストですぐに問題を見つけます。 私の仕事は、調査の大まかな経過(方法論に達していないため)とプロファイラー機能を示すことです。これにより、コード内の問題について結論を導き、それらを解決する方法を探し続けることができます。
既に述べたように、調査しているコードは、クリティカルセクションによって保護されている変数へのマルチスレッドアクセスを実装していることがわかりました。 Hotspotプロファイリングの結果から、ComputePot関数が最も多くのプロセッサー時間を消費していることがわかります。また、待機コールがあります。libomp5.soライブラリーからの補助関数は、並列OpenMP領域の作成および破棄(fork / join)時に呼び出されます。
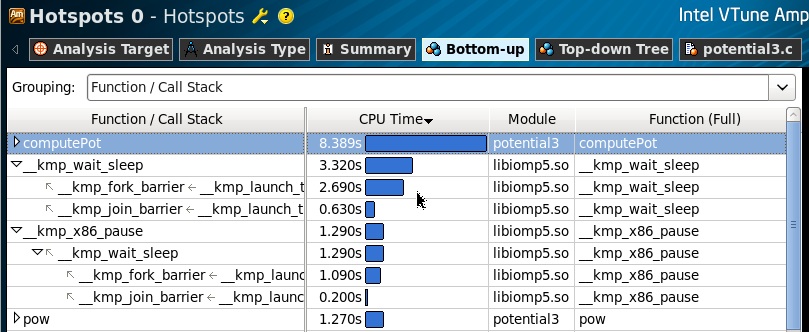
ソースコードの実行時間の分布を見ると、領域の本体の実際の計算関数(pow、sqrt)がcomputePot関数の合計実行時間の無視できる部分を取り去っていることがわかります。 また、パフォーマンスの問題は、OpenMPストリームの変数lPotへのアクセスの同期の面にあります。 マルチコアマシン上の1つのリソースへの多数のスレッドの過剰なアクセスは、決して効果的ではありませんでした。 繰り返しますが、この例は大幅に簡略化されていることを予約します。ローカル変数lPotの観点から、ここではクリティカルセクションは必要ありませんが、そのままにしておきます。そうしないと、例は削減元の実装を反映しません。

次に、同期オーバーヘッドを削減できる可能性がある場所を理解する必要があります。 最初の衝動は、pthreadの実装を書き直し、それによってOpenMPライブラリのオーバーヘッドの可能性を排除することでした。 実際、もっと簡単にできるのは、pthreadsスレッドを作成し、pthread_mutex_lock / unlockを使用して変数へのアクセスを同期することです。 ストリーム間で負荷とデータを共有する多くのコードを作成する必要があるため、実際の例ではリアルタイムでこれを行うことはほとんど不可能であるとすぐに言わなければなりません。 それでは、このマイクロテストを試してみましょう。 結果は予想通りであることがわかりました-生産性の著しい増加は観察されませんでした。 それでは、OpenMPライブラリの調査を続けます(開発者が並んで座っていて、いつでも愚かな質問に答えることができるという理由だけで、libpthreadよりもライブラリを選ぶ方がはるかにいいので、それをお勧めします)。
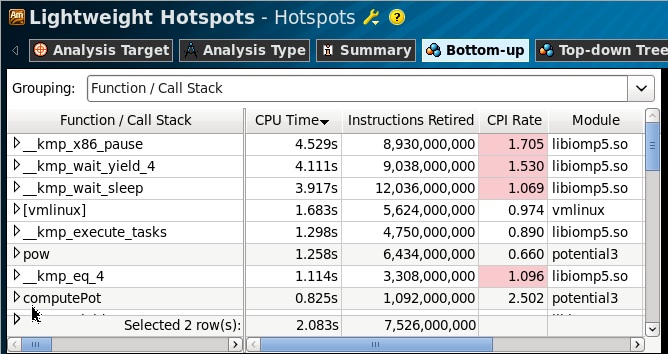
ライブラリコールとシステムコールを分析するには、ハードウェアイベントベースのサンプリング(EBS)テクノロジに基づいており、ユーザーレベルとカーネルレベルの両方ですべてのコールをプロファイリングすることが知られているLightweight Hotspotsプロファイルが必要です。 さらに、この場合、関数を実行するための独自の時間(セルフタイム)のみを測定するため、特別なプロセッサカウンターは必要ありません。
プロファイルからわかるように、ほとんどすべての時間はOpenMPライブラリの待機関数(x86_pause、wait_yield、wait_sleep)、およびLinuxカーネル(カーネルモジュールのシンボルなしではプロファイルできない呼び出し)の一部に費やされました。 この情報から何が得られますか(少なくとも、「コアを破損する」必要はありません)。 EBSテクノロジーによって提供されるプロファイルはフラットであるため、何もありません。 フラット-呼び出しによって集計された(ほとんどの時間で実行される)ほとんどのサンプルを収集した関数のリストがあることを意味します。 つまり、これらの関数は誰でも何度でも呼び出すことができます。 これらの関数がどこから呼び出されたか、誰が待っていたかを理解するには、「凸」プロファイルが必要です。
VTune Amplifier XE 2013 Betaの新しいバージョンには、このような機会があります。 これは、プロセッサのBTR(Branch Target Register)トレースに基づいた完全に新しいテクノロジーであり、カーネルレベルの関数によって作成された場合でも、呼び出しスタックを復元できます。 これは非常に「おいしい」機能です。特に、一部のプロセッサイベント(必ずしも時間ではない)がシステムコールに集中している場合に便利であり、ユーザーコードのどの関数がイニシエーターであるかを調べる必要があります。

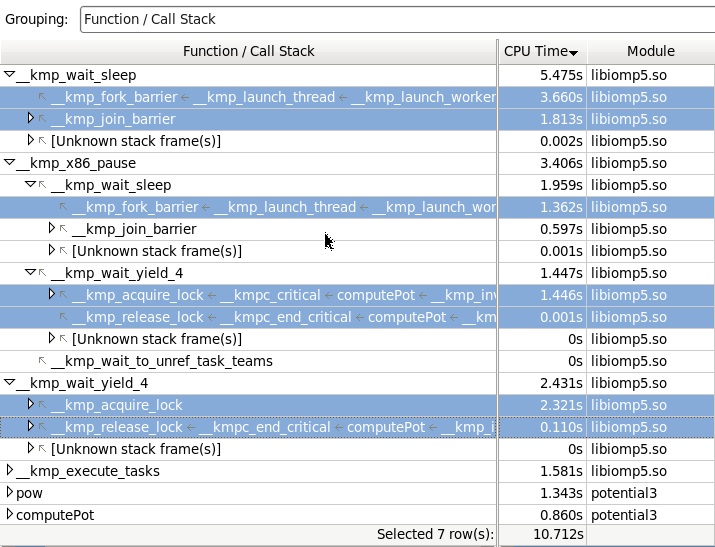
スタックを使用してLightweight Hotspotプロファイルを収集すると、次の図が表示されます。 (ここでは、プロセッサの助けを借りてもスタックを収集するのは多少費用がかかる操作であり、プログラムの実行のオーバーヘッドが考慮されるため、時間パラメータがわずかに変化することを考慮する必要があります)。
ここで見たもの:時間の主な消費者はライブラリ関数wait_yield_4で、これはcomputePot関数のクリティカルセクションエントリのスタックで呼び出され、最終的にx86_pause関数を呼び出します。
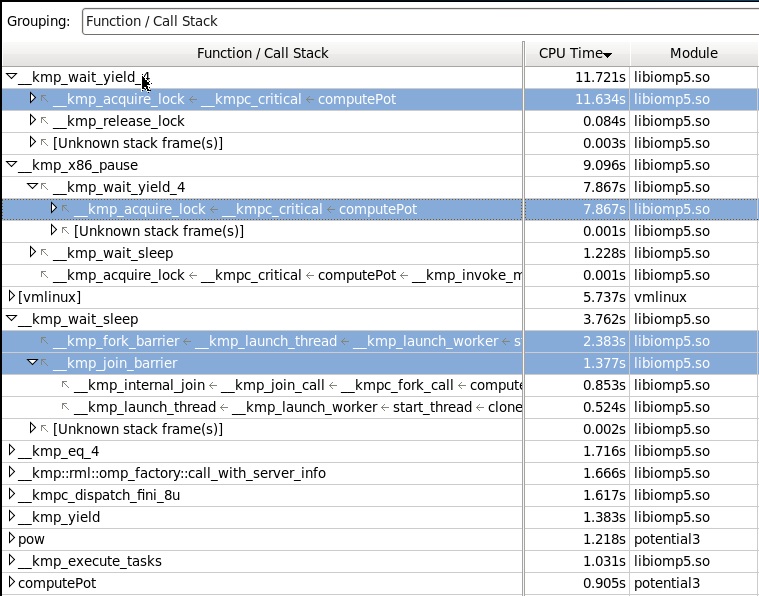
アセンブリビューの一時停止ツールが呼び出されるのは簡単です(アセンブリビューに切り替える)。

wait_sleepについては、x86_pauseも呼び出しますが、並列領域の最初と最後で待機する必要があります。
次に、カーネル呼び出し(ツールで解決できないシンボルのため、モジュールの名前が括弧で囲まれている[vmlinux])を見てみましょう。 ここでは、クリティカルセクションをキャプチャしようとして、yeildライブラリ関数を介して「コアの離脱」の大部分が発生したことがわかります。
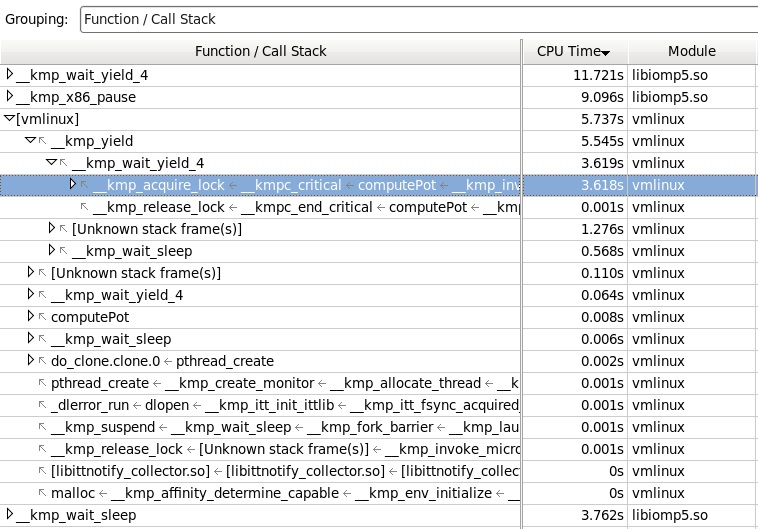
これでこれで遊ぶことができます。 実際、OpenMPでクリティカルセクションをキャプチャしようとして失敗した場合、制御はすぐにカーネルに転送されず、一時停止命令を使用してスピン待機(wait_yield_4)で待機します。 ただし、この待機中(数十ミリ秒)にフラグのチェックでミューテックスがフリーであることが示されなかった場合、次のyield関数が呼び出され、カーネルに制御を移し、カーネルシグナルが起動するまでスレッドを「スリープ」します。 カーネルモードに移行する可能性を減らすために、spin-wait'eのレイテンシを増やすことができます。 OpenMPライブラリのドキュメントを読むと、そこから次のような便利なグローバル設定があることがわかります。
KMP_LIBRARY-実行時実行モード[シリアル| ターンアラウンド| スループット(デフォルト)]
KMP_BLOCKTIME-スリープするまでの待機時間[0 | N(デフォルトは200ミリ秒)| 無限]
OpenMPランタイムを設定して、スレッドが可能な限りアクティブになり、他のスレッドに制御を移さないようにします(これは、スレッドの競合が発生し、スレッドが共有リソースを奪い合う状況で発生します)。 インストール:
KMP_LIBRARY =ターンアラウンド
KMP_BLOCKTIME =無限
プログラムのみが機能するシステム(プロセッサが他のアプリケーションの集中的な実行でビジーではない)では、この設定により同期の速度が最大に向上すると考えられています。 ただし、プログラム内のスレッドの数がプロセッサの数よりもはるかに多く、実行キューに立つ権利のために互いに戦っている場合、反対の設定が最適であることに注意してください : KMP_LIBRARY = Throughput 、 KMP_BLOCKTIME = 0 。
プロファイリングを再開し、結果を調査します。 結果を比較することから始めましょう。 スピンウェイトの待機時間が減少していることがわかります。最も重要なことは、カーネルでの待機がほとんどなくなっていることです(これが目標でした)。 一般に、プログラムは約2倍速く動作しました。

現在、メインの待機時間は、並列領域を作成および破棄するときに呼び出されるwait_sleep関数内にあり、スレッドがセクションをキャプチャする機会を得たという事実により、クリティカルセクション(acquire_lock)のキャプチャからのwait_yield_4による一時停止が減少しました。
この簡単な例では、OpenMPランタイム設定の変更によるパフォーマンスの向上が得られたことをもう一度言及する必要があります。これは、実際、測定を行うのが良い(そして成功を誇る)退化したケースです。 実際のアプリケーションでは、すべてがそれほど単純ではなく、成功は控えめです。 ただし、このアプローチを適用すると、過剰な同期から生じる問題を調査し、何らかの方法でそれらを解決することができます。