エントリー。
まず、ハミングコードとは何か、なぜそれが必要なのかを説明する価値があります。 以下の定義がウィキペディアに記載されています。
ハミングコードは最もよく知られており、おそらく最初の自己チェックコードと自己修正コードです。 これらは、2進数システムを参照して構築されます。
つまり、これは、特定の方法で送信後(ネットワーク経由など)に情報メッセージをエンコードして、このメッセージにエラー(干渉など)があったかどうかを判断し、可能であればこのメッセージを復元できるアルゴリズムです。 今日は、エラーを1つだけ修正できる最も単純なハミングアルゴリズムについて説明します。
また、このアルゴリズムには、より多くのエラーを検出する(可能であれば修正する)より高度な修正が加えられていることにも注意してください。
ハミングコードは2つの部分で構成されていることをすぐに言う価値があります。 最初の部分は、特定の場所に制御ビット(特別な方法で計算)を挿入することにより、元のメッセージをエンコードします。 2番目の部分は着信メッセージを受信し、制御ビットを再計算します(最初の部分と同じアルゴリズムを使用)。 新しく計算されたすべての制御ビットが受信したものと一致する場合、メッセージはエラーなしで受信されます。 それ以外の場合は、エラーメッセージが表示され、可能であればエラーが修正されます。
どのように機能しますか?
このアルゴリズムの動作を理解するために、例を考えてみましょう。
準備する
エラーなしで送信する必要があるhabrメッセージがあるとします。 これを行うには、最初にハミングコードを使用してメッセージをエンコードする必要があります。 バイナリ形式で提示する必要があります。
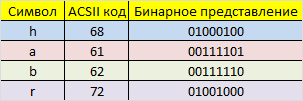
この段階では、いわゆる情報語の長さ、つまりエンコードするゼロと1の文字列の長さを決定する価値があります。 ワード長が16であると仮定します。したがって、元のメッセージ(「habr」)を16ビットのブロックに分割する必要があります。その後、これらを互いに別々にエンコードします。 1文字がメモリの8ビットを占有するため、1つのエンコードされたワードに正確に2つのASCII文字が配置されます。 そのため、16ビットの2つのバイナリ文字列を取得しました。
 そして
そして 
この後、エンコードプロセスが並列化され、メッセージの2つの部分(「ha」と「br」)が互いに独立してエンコードされます。 最初の部分の例を使用して、これがどのように行われるかを考えてみましょう。
まず、制御ビットを挿入する必要があります。 それらは厳密に定義された場所に挿入されます-これらは2のべき乗に等しい数の位置です。 私たちの場合(情報語の長さが16ビット)、これらは位置1、2、4、8、16になります。したがって、5つの制御ビット(赤で強調表示)を得ました。
それは:
次のようになりました:

したがって、メッセージ全体の長さが5ビット増加しました。 制御ビット自体を計算する前に、それらに「0」の値を割り当てました。
制御ビットの計算。
次に、各制御ビットの値を計算する必要があります。 各制御ビットの値は(予想外に)情報ビットの値に依存しますが、すべてにではなく、この制御ビットが制御する値にのみ依存します。 各制御ビットがどのビットを担当するかを理解するには、非常に単純なパターンを理解する必要があります。番号Nの制御ビットは、位置Nから始まるNビットごとに後続のすべてのNビットを制御します。より明確:
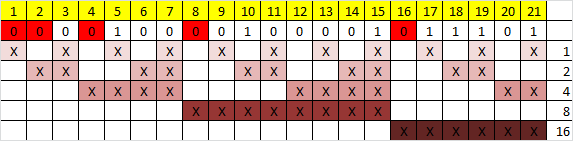
ここで、「X」は制御ビットによって制御されるビットを意味し、その数は右側にあります。 つまり、たとえば、ビット番号12は、番号4と8のビットで制御されます。番号Nのビットが制御されるビットを見つけるには、Nを2のべき乗で拡張するだけです。
しかし、各制御ビットの値を計算する方法は? これは非常に簡単に行われます。各制御ビットを取得し、それによって制御されるビットの中にユニットがいくつあるかを確認し、特定の整数を取得し、偶数の場合はゼロを設定します。 以上です! もちろん、数値が偶数であれば1に設定し、そうでなければ0に設定することもできます。主なことは、アルゴリズムが「コーディング」部分と「デコード」部分で同じであることです。 (最初のオプションを適用します)。
情報ワードの制御ビットを計算すると、次のようになります。

そして、第二部:

以上です! アルゴリズムの最初の部分は完了です。
デコードとエラー修正。
ここで、アルゴリズムの最初の部分でエンコードされたメッセージを受け取ったとしましょうが、エラーが発生しました。 たとえば、次のようになりました(11番目のビットが誤って送信されました)。

アルゴリズムの全体の2番目の部分は、すべての制御ビットを再計算して(最初の部分のように)、それらを受信した制御ビットと比較する必要があるという事実にあります。 したがって、制御ビットを誤った11番目のビットでカウントすると、次の図が得られます。

ご覧のとおり、1、2、8の数字の下にある制御ビットは、受信した同じ制御ビットと一致しません。 不正な制御ビットの位置番号(1 + 2 + 8 = 11)を加算するだけで、誤ったビットの位置を取得できます。 反転して制御ビットを破棄するだけで、元のメッセージが元の形式で取得されます。 メッセージの2番目の部分でもまったく同じことを行います。
おわりに
この例では、情報メッセージの長さを正確に16ビットとしました。これは、この例を検討するのに最適であると思われるためです(長すぎず短すぎません)。もちろん、長さは任意です。 この単純なバージョンのアルゴリズムでは、情報ワードごとに訂正できるエラーは1つだけであることに注意してください。
ご注意
このトピックの執筆に触発されたのは、検索でHabréのこのトピックに関する記事を見つけられなかったからです(非常に驚きました)。 したがって、この状況を部分的に修正し、このアルゴリズムがどのように機能するかをできるだけ詳細に示すことにしました。 例を使用してアルゴリズムのプロセスを自分の言葉で伝えようとするために、私は意図的に単一の式を与えませんでした。
ソース。
1. ウィキペディア
2. ハミングコードの計算