この記事では、パーサーとそのテスト手順を実装する際の技術的なソリューションといくつかのトリックを共有したいと思います。 この記事は、ANTLR v2の使用をより詳細に理解したい人に役立ちます。
発行
ここでは、なぜこのタスクが興味深いのか、どのような困難を解決する必要があるのかを説明しようとします。
1.正式な言語仕様の欠如
これはおそらく、パーサーの開発における主な障害です。この場合、開発自体に加えて、ある意味で文法のリバースエンジニアリングが必要だからです。
2. PHP文法はコンテキストに依存しません
つまり、純粋な形式では、既存の解析アルゴリズム(アルゴリズムのグループLL(k)およびLR(k))は原則として適用できません。 その理由は次のとおりです。
- 実行可能コードを任意のテキストストリームとインターリーブします。
- HEREDOC表記-引用符は任意の文字列です
- 多くの言語キーワードが通常の識別子として機能します。
純粋に技術的な問題のリストは、制御構造の代替構文と公式文書の不完全性に安全に起因する可能性があります。
実装
コードをテキストガベージから分離する
この仕事を始めたとき、私はPHPを知っていると思った。 実際、それが最初に仕様の欠如という事実がまったく気にならなかった理由です。 当初、最も深刻な問題は、認識されるソースコードはセクションにあるものだけを考慮する必要があるという事実を正式な言語でどのように記述するかであるように思われました。
<?php … ?>
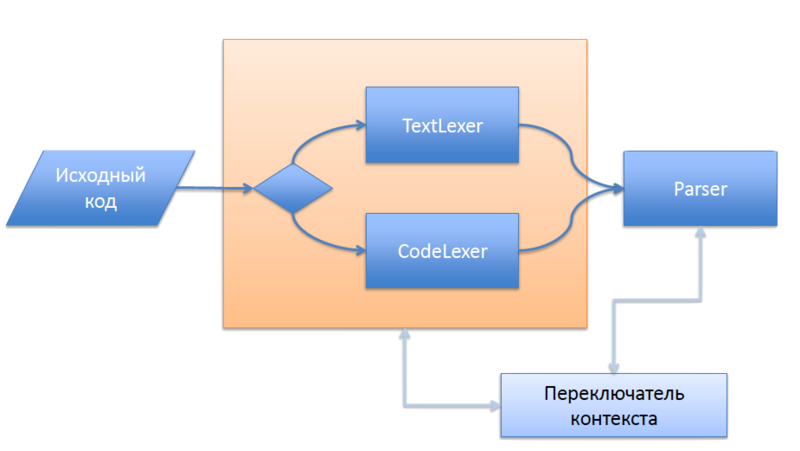
ここで最も簡潔なのは、 トークンの多重化とレクサーのスタックの使用に基づくソリューションでした。 この目的のために、パーサー全体の現在の状態を格納する追加のエンティティが既に必要でした(少なくとも「コードが現在期待されている」状態または「テキストを転送する」状態、 ParsingState.javaを参照)。
そして、もちろん、2つの異なるレクサー文法: phpLexerとphpOutTheCodeです。 コンテキストを切り替えるためのシグナルは、トークン
<?php
、
<?=
And
?>
によって直接提供され
?>
。
概略的に、このアイデアは以下に描かれています。
HEREDOCストリング
HEREDOC表記は複数行の文字列リテラルであり、識別子は引用符として機能します。 そのようなリテラルは、HEREDOCの開始がトークン<<<として発生した後に実行される埋め込みコードによって認識されます。 レクサー文法のこの断片は直接ここで見ることができます 。
識別子としてのキーワード
ANTLRのキーワードは識別子ではありません。 このような場合にANTLRによって生成されるコードを見ると、キーワードは常に通常の識別子として認識され、画像(文字列表現)はキーワードの辞書と照合されます。 この操作はレクサークラス内で実行されます。このクラスは、認識時に次の理由でパーサークラスのコンテキストを認識しません(および認識できません)。
- パーサーは、レクサーからではなく、特別なバッファーから次のトークンを取得します。 LL(k)アルゴリズムの要求に応じて、k個のトークンを先読みできるように、バッファは事前に満たされています。 これは、語彙素が認識された時点で、パーサーはまだこの場所で識別子が期待されているかどうかを知らない可能性があることを意味します。レクサーは予定より進んでいます。
- 構文述語を処理する場合(いわゆる制御されたバックトラッキング)、パーサーはトークンフローに沿って「ロールバック」を実行でき、外部からの述語によってロールバック/ドッキングの状況をキャッチすることは困難です。
幸いなことに、ソリューションも非常に簡単です。パーサーレベルでルールを識別子として宣言し、「正直な」識別子に加えてキーワードトークンをリストします。 ただし、ここには別の危険があります。たとえば、キャスト操作など、パーサールールのレベルにあいまいさがあります。
(typeName) expression
として解釈することができます
(expression) expression
、たとえば、
int
の理由により、
int
キーワードが
expression
入力トークンになるためです(識別子であるため)。 この設計は意味をなさないため、認識エラーが発生します。
この問題は、追加の構文述語を使用して解決されました( php.gを参照)。
typeCastExpression[boolean allowComma]: (LPAREN typeName RPAREN expression[false, false]) => (LPAREN^ typeName RPAREN { #LPAREN.setType(TYPE_CAST) ;} typeCastExpression[allowComma] ) | (LNOT^ typeCastExpression[allowComma]) | (DOG^ typeCastExpression[allowComma]) | (BW_NOT^ typeCastExpression[allowComma] ) | (MINUS^ {#MINUS.setType(UNARY_MINUS);} typeCastExpression[allowComma]) | (PLUS^ {#PLUS.setType(UNARY_PLUS);} typeCastExpression[allowComma]) | incrementExpression[allowComma] ;
優先運用およびその他の技術的な問題
多くの努力が、操作の優先順位の把握と「揺れ」に費やされました。 公式文書は不完全です。 そのため、演算子にはカンマがありますが、PHPにはありません。
興味深いことに、PHPでは、三項演算子の内部で代入の使用が許可されています( 説明については mark_ablovに感謝します )。 つまり、フォームの構築
a = test() ? b = c : d = e;
C / C ++ではコンパイルされませんが、PHPでコンパイルされます(そのような例はphpBB3コードで見つかりました)。
もう1つの興味深い点は、式の
echo
(これは関数、つまり式ではない)によって、オペランドをコンマで区切って列挙できることです。 これは出力の連結のように機能しますが、phpMyAdminソースコードのおかげで、同様の別の構造が見つかりました-printはechoに似ていますが、コンマを許可しなくなりました。
トークン
?>
は、セミコロンと同等であることが判明しました。
<?=
演算子は
echo
(上記のコンマのコメントを含む)と同等
<?=
。
ドル記号は多くの場合演算子のように見えますが(先ほどこのトピックについて質問しました)、そうではありません:数ドルを連続して「適用」する可能性がレクサーによって認識され、それでも1つの語彙素のように見えます-これは公式コンパイラーで行われます。
テスト中
言語のこれらの微妙な点はすべて、テスト中に原則として発見されました。 この場合、実際のプロジェクトのソースをテストすることで、文法が多くの言語を最も完全にカバーしていることを確認できました。 さらに、回帰を追跡することは非常に重要です。文法の1つの小さな編集が、すべてを完全に破壊する可能性があります。
これらの目的で使用するテストの意味は非常に単純です。単純なコンソールラッパーがライブラリの周りに作成され、phpファイルを入力として受け取ります。 パーサーが問題なくファイルを認識した場合、ラッパーは何もしません。問題があります-関連情報を出力します。
ラッパープログラムは、ファイルへの出力を伴うfindコマンドによって起動されます。
このようなもの:
$ (find ~/Documents/distr/phpBB3/ -name '*.php' -print -exec java -jar bin/jar/parse-php-test.jar -f {} \; ) &>./out-phpbb.txt
出力ファイル(この場合はout-phpbb.txt)を保存し、新しい結果と比較できます。 結果は改善または悪化しています-ファイルの行数で理解できます:
$ wc -l ./out-koh.txt* 498 ./out-koh.txt 502 ./out-koh.txt.old
おわりに
パーサープロジェクトは、現在、学問的な関心が高い可能性があります。 たとえば、 CheckStyleの機能を拡張したり、独自のphp美化機能を実装したりするための基礎として使用できます。
ご覧のように、パーサーは言語のバージョン5.2向けに設計されていますが、私の意見では、文法をレベル5.3にするのに基本的な問題はありません(バージョン5.4はより複雑です:文法検証のテストベースは実際にはありません)。 現時点では、パーサーはソースZF 1.11、Yii Framework 1.1.10、phpBB 3.0.10のソースセット全体を正常に解析しています。
この作品が面白く、そして/または誰かに役立つように思えたら、私はうれしいです。 あなたのコメントと批判も役に立ちます。
ご清聴ありがとうございました!