この記事では、遺伝的アルゴリズムによって問題を解決するためのJavaフレームワークであるEvoJに専念するシリーズを続けます。
前回の記事では、Havoの読者にEvoJの基本的な動作原理を紹介しました。
今日は、EvoJがどのようにコンテナ内のパッケージングの問題を解決できるかを見ていきます。
問題の声明
一言で言えば、コンテナに梱包するタスクは次のようになります:特定のボリュームのコンテナのセットと、これらのコンテナにパックする必要があるオブジェクトのセットがあります(最も単純な場合、空間の向きは無視されます)。 目標は、できるだけ少ないコンテナを使用して、すべてのアイテムを積み重ねることです。
ソリューションの説明方法の選択
EvoJを使用するには、Javaインターフェイスの形式で問題の解決策を構成する変数を何らかの形で記述する必要があります。
最初のオプションは、各コンテナーをそれに含まれるアイテムのリストとして記述することです。
public interface Solution { List<List<Integer>> getContainers(); }
実際、これはコンテナのリストであり、各コンテナはその中に含まれるパーツのリストによって記述されます。
EvoJではこの方法でソリューションを記述することができますが、このアプローチでは、同じアイテムが複数のコンテナに分類された場合、競合する決定を排除するための追加の努力が必要になります。
より単純なアプローチでは、特定の各アイテムがどのコンテナに落ちたかを説明します。
public interface Solution { @ListParams(length = "itemsCount", elementRange = @Range(strict = "true", min = "0", max = "lastBinIndex"), elementMutationRange = @MutationRange(value = "100%")) List<Integer> getBinIndices(); }
ここでは、ソリューションはリストとして表示され、その各要素は、対応するアイテムがどのコンテナに落ちたかを示します。
このインターフェイスは、EvoJのトリックもいくつか示しています。 まず、リストの長さ、およびその要素の最大値は、特定の数値ではなく、変数の名前によって設定されます。 これにより、コンパイル時に特定の値に縛られることがなくなります。
次に、このタスクで重要な要素は
MutationRange=100%
表示です。 リストにはコンテナ番号が含まれていることを思い出してください。デフォルトのミューテーション半径をそのままにすると、ミューテーション中、オブジェクトは近くにあるコンテナ間でしか移動できなくなり、進化の効率が大幅に低下します。
フィットネス機能の選択
自然なフィットネス関数は占有されるコンテナの数になりますが、このアプローチはあまり効果的ではありません。 その理由を説明します。
解決策1
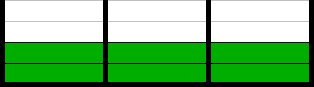
決定2

どちらのソリューションも3つのコンテナーを使用します。 しかし、明らかに、2つのコンテナーが占有される前に1つの突然変異だけが必要なので、2番目の解決策が望ましいです。 もちろん、突然変異の結果としての最初の解決策から、2つのコンテナのみが占有されている解決策を取得できますが、この可能性ははるかに低くなります。
したがって、占有されているコンテナの数では、ソリューションの「適合性」を完全に評価するには不十分です。 状況を改善するために、追加のインジケータを導入します-コンテナ内の空き領域の平方の合計(両方の場合の空き領域の単純な量は同じです)。
コンテナの一部が過負荷になっている場合があります。 私たちの観点からすると、そのような決定は有効ではなく、それらを
null
評価することにより、遺伝子プールのそのようなメンバーを取り除くことが可能です。 一方、混雑は小さいかもしれませんが、ソリューションは多くのコンテナを占有せず、突然変異または交差の成功の結果、過負荷が消える可能性があります。
解を評価するための3番目のインジケーター、つまり過負荷の2乗の合計を導入します。
したがって、ソリューションを適切に評価するには、3つの数値が必要です。 それらを特定の整数指標に減らすことは可能ですが、EvoJでは、フィットネス関数から任意の
Comparable
値を返すことができます。 これには独自のクラスがあります。
public class PackRating implements Comparable { private int binsUsed; private int score; private int overflow; public PackRating(int binsUsed, int score, int overflow) { this.binsUsed = binsUsed; this.score = score; this.overflow = overflow; } public int compareTo(Object o) { PackRating other = (PackRating) o; if (this.overflow != other.overflow) { return other.overflow - this.overflow; } if (this.binsUsed != other.binsUsed) { return other.binsUsed - this.binsUsed; } return this.score - other.score; } public int getBinsUsed() { return binsUsed; } public int getOverflow() { return overflow; } public int getScore() { return score; } }
ここで、
binsUsed
フィールドは使用されているコンテナの数です。
score
フィールドは、コンテナ内の空き領域の平方の合計です。 最後に、オーバーフローフィールドは、コンテナオーバーロードの平方の合計です。
比較手順では、混雑のないソリューションが混雑のあるソリューションよりも優れていると見なします。混雑が等しい場合、ビジーなコンテナーが考慮され始め(より少ない)、最後に、同じ数のコンテナーが占有されている場合、
score
フィールド(より良い)が考慮されます。
フィットネス機能を実装することは残っています。 これは、 前回の記事の例のように、AbstractSimpleRatingクラスを展開することで行います。
public class BinPackRatingCalculator extends AbstractSimpleRating<Solution> { private int[] items; private int[] bins; public BinPackRatingCalculator(int[] items, int[] bins) { this.items = items; this.bins = bins; } @Override protected Comparable doCalcRating(Solution solution) { int[] tmpBins = new int[bins.length]; int score = 0; int overflow = 0; int binsUsed = 0; final List<Integer> indicex = solution.getBinIndices(); for (int item = 0; item < indicex.size(); item++) { Integer binIndex = indicex.get(item); tmpBins[binIndex] += items[item]; } for (int bin = 0; bin < tmpBins.length; bin++) { int dl = bins[bin] - tmpBins[bin]; final int dl2 = dl * dl; if (dl < 0) { overflow += dl2; } else { score += dl2; } if (tmpBins[bin] > 0) { binsUsed++; } } return new PackRating(binsUsed, score, overflow); } }
このコードを詳細に分析するのではなく、単にフィットネスインジケーターを計算し、
PackRating
クラスのインスタンスとして返します。
すべてを機能させる
main
メソッドを使用して新しいクラスを作成します。
public static void main(String[] args) { int[] items = {3, 2, 4, 4, 5, 3, 4, 5, 6}; int[] bins = {8, 8, 8, 8, 8, 4, 12, 12, 8, 6}; Map<String, String> context = new HashMap<String, String>(); context.put("itemsCount", Integer.toString(items.length)); context.put("lastBinIndex", Integer.toString(bins.length - 1)); DefaultPoolFactory factory = new DefaultPoolFactory(); GenePool<Solution> pool = factory.createPool(200, Solution.class, context); DefaultHandler handler = new DefaultHandler(new BinPackRatingCalculator(items, bins), null, null, null); handler.iterate(pool, 40); Solution bestSolution = pool.getBestSolution(); showSolution(bestSolution, bins, items); }
ここで、
items
配列には、
items
の条件付きサイズが含まれています。
bins
配列は、使用可能なコンテナーの条件付き容量です。 上記のコードの特徴は、変数を持つコンテキストを使用して、
Solution
インターフェイスからリストの長さを示し、可能な値を制限することです。 残りについては、コードは前の記事で示したものを繰り返します :母集団のファクトリーの作成、200人の母集団の作成、ハンドラーの作成、および40回の反復の実行。
母集団のサイズと反復回数は実験的に選択されます。
上記のコードは非常に高速であり、4年前のラップトップで200のソリューションを対象に1000回の反復を行っても、約2秒かかります。
あとがき
古典的なNP複雑な問題の1つの解決策に遺伝的アルゴリズムを適用する方法を検討しました。 遺伝的アルゴリズムは最適なソリューションを見つけることを保証するものではありませんが、ほとんどの場合はそれで十分です。
興味のある方のために、検討された例のソースコードはMavenプロジェクトの形式でレイアウトされています。
ご清聴ありがとうございました。