すぐに明らかになった主な問題は、計画アルゴリズムを構築するための数学モデルの選択でした。 明らかに、共有リソース共有アプローチは、共通の物理空間を共有するためのネットワークプロトコルと同様に考えることができます。
インスピレーションのために、IPv4アドレス指定アルゴリズムと動的ルーティングプロトコル(RIP1 \ 2、OSPF)が考慮されました
したがって、アルゴリズム自体:
IPアドレッシングと同様に、フローと計画プロセスを番号とマスク(サブネットとして)で説明し、グループ自体を番号のみ(ターゲットポイント)で説明します。 プロセスの実装に応じて、グループプランナー間でプロセス、その実行時間、優先度などに関するデータを転送します。 私の例では、アドレスバイト/マスクバイトのアドレス指定を使用しています。 合計で最大255個のプロセスグループと、グループを制御する最大8個のスケジューラを実行する機能、合計で最大510個のスケジューラプロセス。
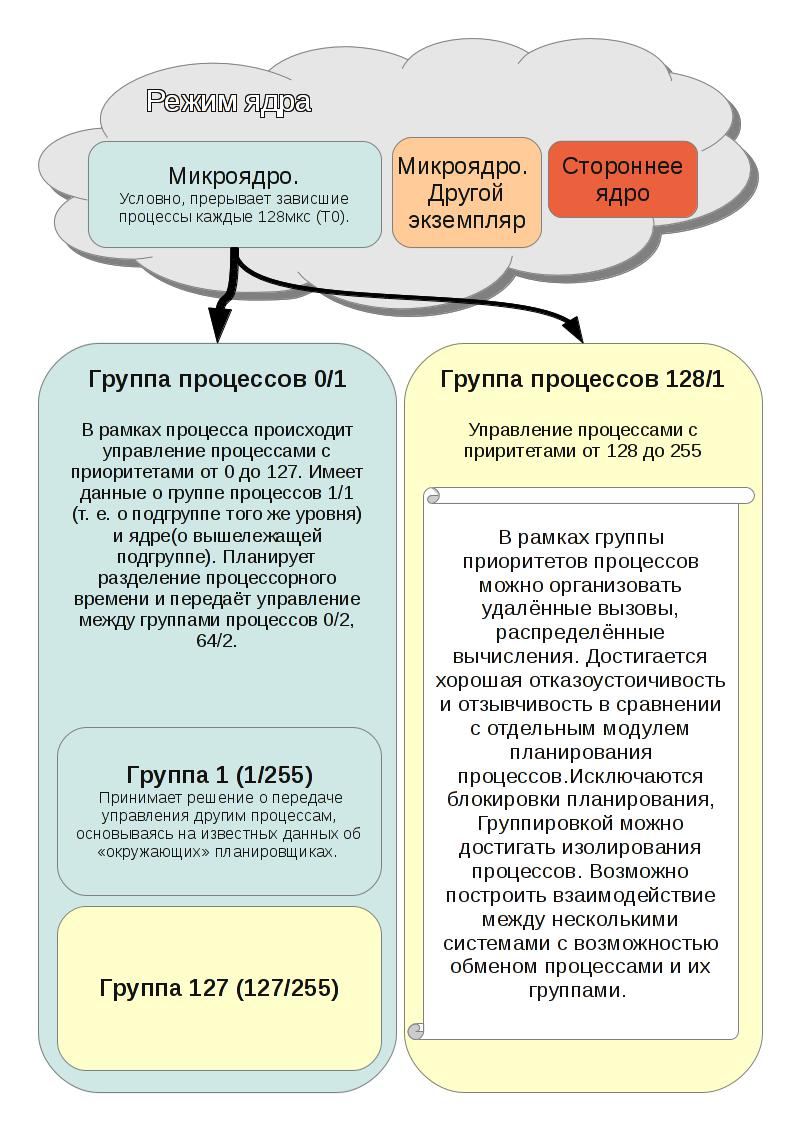
スケッチアルゴリズム
私はこのアイデアをリアルタイムOS向けに開発しているため、すべてのアプリケーションのアイデアはフォールトトレランスと予測可能性に関連しています。
スケッチから、アプリケーションの主要なアイデアを理解できます。
1)スケジューラー間のプロセスの転送。 たとえば、wathcdogがトリガーされると、プロセスをソフトリアルタイムからハードモードに移行したり、あるプロセスがループしたときに別のプロセスに置き換えたりできます。
2)スケジューラーを停止せずにマイクロカーネルを再起動する機能。 たとえば、すべてのプロセスを別の物理デバイスに転送して、機器を交換できます。
3)スケジューラーは、別々のプロセッサー/コントローラーで実行できます。 産業用機器にとっては非常に重要であり、多くの場合、宇宙に分散させる必要があります。
4)3番目から、システムコールのレベルでRPCを実装する可能性が続きます。 追加のミドルウェアを使用する必要はありません。
5)並行して動作するいくつかのスケジューリングアルゴリズムを実装することが可能です。 特定のアルゴリズム用に準備された既存のプロジェクトを簡単に転送できます。
6)スケジューラにエラーがある場合、新しいスケジューラでプロセスグループを再起動するだけで十分です。 他のスケジューラーからの情報に従って、グループの状態に関する情報を障害に復元することができます。
アプリケーションには多くのアイデアがありますが、システムライブラリを使用してOSカーネルをゼロから作成するリソースがないため、minix3カーネルを選択します。 何が実装され、何が問題にならないか。 誰かがこのアルゴリズムのアイデアが役に立つことを願っています。 Linuxでの実装の可能性についてまだ考えています|| * bsd; GNU \ Hurdの方が簡単です。 アドレスを16ビットに増やすという考えはまだあり、それによりPPIDとアドレスを明確に比較することが可能になります(グループの代わりにプロセス自体が存在します)が、そのようなスキームにふさわしいアプリケーションはまだありません。 ここでソースとニュースを投稿します(ホームコンピューターのサイトは常に利用できるとは限りません )。
アルゴリズムを完了するために、グラフの頂点の値を設定するためのルールを決定し、ダイクストラアルゴリズムを使用してグラフのパスを計算する必要があることを忘れました。
グラフ値の正規分布でモデル化し、移植できる最も一般的なパッケージでテストを実施します。