そのような問題の1つは、データベース内のレコードの削除です。 ほとんどのプログラマーによると、この操作はデータベースの処理を高速化し、データベースをよりコンパクトにします。 秘Theは、これは真実ではないということです。 また、リレーショナルデータベースでこれが部分的にしか当てはまらない場合、NoSQLでは完全に嘘になる可能性があります。
この問題については、後でApache CouchDBで説明します。
トピックの図:
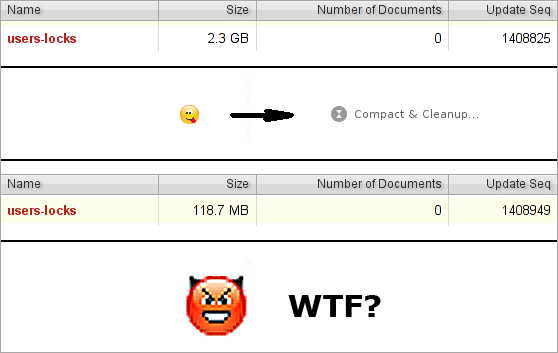
データの保存方法
データベース内のデータは、ファイルシステムの原則に基づいて保存されます。データ配置マップと、それらが直接配置されるファイルがあります。 SQLの場合、これは通常テーブルであり、NoSQLの場合、通常はツリーです。
ファイルシステムの場合のようにデータを削除する場合、データベースは、削除するレコードなしでマップファイルとデータファイルを再作成する時間を無駄にしません。 彼女は、マップ上でエントリを削除済みとしてマークするだけです。 これは簡単に確認できます。MyISAMを使用してMySQLに簡単なテーブルを作成し、そこにレコードを1つ追加してから、統計を削除して表示します。

これを最適化するには、マップファイルとデータファイルを再作成する必要があります。 実行:
OPTIMIZE TABLE guest;
取得:

興味深いことに、最適化されていないバージョンのテーブルは、奇妙なことに、最適化されたバージョンとほぼ同じ速度で動作します。 これは、通常、リレーショナルデータを保存するという原則が非常にシンプルで、削除されたレコードをスキップするために必要なシークの量を簡単に計算できるためです。 上記はもちろん、オーバーヘッドを無視できるという意味ではありませんが、スケジュールに従ってデータを最適化する単純なbashスクリプトを記述するだけで十分であり、プログラムコードで追加の作業を行う必要はありません。
上記は、さらに微妙な違いがあるInnoDBに完全に適しているわけではありませんが、今日はMySQLについてではなく、CouchDBについての記事があります。
CouchDBでの削除の仕組み
簡単なドキュメントを受け取ります:
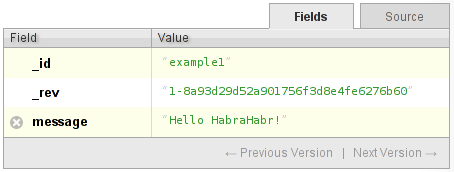
それを削除します。 何が起こっているの? データベースは、ドキュメントを削除済みとしてマークします。 彼女はどうやってこれをしますか? ドキュメントを読み取り、すべてのフィールドを削除し、追加の_deleted:trueプロパティを挿入し、ドキュメントを新しいリビジョンの下に書き込みます。 例:

これで、ドキュメントの最新バージョンを取得しようとすると、ドキュメントが削除されたことを示す404エラーが表示されます。 ただし、ドキュメントの最初のリビジョンに目を向けると、利用可能になります。
次に、 compactを実行します。 削除されたドキュメントの場合、データベースは、ドキュメントが削除されたことを示すリビジョンを除くすべてのリビジョンを自動的に削除します。 これは、複製中にこれについて別のデータベースに通知するために行われます。 このリビジョンはデータベースに永久に残り、削除できません。 (確かに、_purgeを使用できますが、これは多くのマイナス効果を持つ松葉杖であり、生産にはお勧めしません。)
仕事にどのように影響しますか?
CouchDBでは、データはB +ツリーとして保存されます 。 削除されたドキュメントは、それがダミーであっても、ツリーの一部のままです。 これは、このデッドレコードが考慮されることを意味します。 また、インデックスを作成するときだけでなく、ドキュメントの通常の挿入時にも考慮されます。ドキュメントを挿入すると、ツリーが再構築され、レコードが多いほどプロセスが遅くなるためです。
コントロールヘッド
最後に、Erlangの速さを理解する必要があります。 ここで、 総合テストを行うと、ErlangのパフォーマンスがPHPに近いことがわかります。 つまり、B +ツリーは最速の言語によって操作されません。
実際にはどのように減速しますか
WRITEが最もまれな操作ではなく、数百万のドキュメントがツリーにある場合、データベースの速度が大幅に低下し始めていることが突然(そして予期せず)発見される場合があります。 たとえば、CouchDBを使用して、平均余命の短いドキュメント(セッション、ロックファイル、キュー)を保存します。 実際の生産でチャートを見てみましょう:
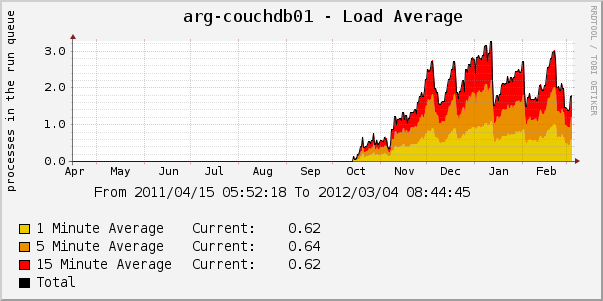
グラフは、ピークが非常にシャープであることを示しています。 ピークの急激な増加は常に予測できるとは限りません。 約200万のデータベース更新(ツリー内に約100万のドキュメント)がある場合がありますが、それでも十分に機能しますが、さらに10万が表示され、パフォーマンスがパイプにクラッシュします。 ピークが急激に低下するのは、ベースを再作成し、数週間のパフォーマンスが許容可能になるためです。
結論
- CouchDBはすべてのドキュメントをB +ツリーに保存し、定期的に再構築します。 Erlangはこのための最速の言語ではありません。 寿命の短いドキュメントにはCouchDBを使用しないでください。ドキュメントが削除されないため、ツリーが大きくなりすぎます。
- 文書を削除しなくても、数百万のレコードがある場合、新しい文書を追加するのに遅れが生じます。
- CouchDBを操作するための記事16の実用的なヒントに注意することをお勧めします。
- CouchDBの作成者であるDamien KatzがCouchBaseをフォークしてCでコアを書き直すことにした理由が明らかになります。 ちなみに、CouchBaseにはmemcachedが組み込まれているため、寿命が短いドキュメントを別の領域に保存できます。