Need to create java CLI programm that searchs for specific files matched some pattern. Need to use multi-threading approach without using util.concurrent package and to provide good performance on parallel controllers.
翻訳
, - . , util.concurrent. .
一般に、このアイデアは原則として複雑ではありませんでした。 なぜなら 条件によっては、util.concurrentを使用できないため、独自のスレッドプールを実装し、このスレッドプールでスピンするタスクをいくつか記述する必要があります。
また、IOをマルチスレッドで使用すると、生産性が向上するかどうかわかりませんでした。
目標はタスクを完了することではなく、問題を調査することであったため、すべてのコードが美しいわけではないことをすぐに言わなければなりません。
原則として、アルゴリズムは再帰的なツリートラバーサルに似ています。たとえば、単純な実装リンク
import java.io.File; public class MainEntry { public static void main(String[] args) { walkin(new File("/home/user")); //Replace this with a suitable directory } /** * Recursive function to descend into the directory tree and find all the files * that end with ".mp3" * @param dir A file object defining the top directory **/ public static void walkin(File dir) { String pattern = ".mp3"; File listFile[] = dir.listFiles(); if(listFile != null) { for(int i=0; i<listFile.length; i++) { if(listFile[i].isDirectory()) { walkin(listFile[i]); } else { if(listFile[i].getName().endsWith(pattern)) { System.out.println(listFile[i].getPath()); } } } } } }
最初に、シングルスレッド実装の動作速度を確認しましょう。シングルスレッド実装のコードはアーカイブにありません。
結果は次のとおりです。
154531ミリ秒
ここで同じことを試してみましょうが、アルゴリズムのマルチスレッド実装を使用します。
これを行うには、再帰呼び出しの代わりに、実行のためにスレッドプールに与えるタスクを作成します。 また、タスクの結果に応じて、何らかの形で結果を報告する機会があったことが必要です。 さらに、(再帰の代わりに)スレッドプールに新しいタスクを追加する必要があります。
ここでは、新しいスレッドを作成するのではなく、小さなタスクとスレッドプールだけを選択した理由をすぐに停止する必要があります。 たくさんのディレクトリがあり、ディレクトリごとに新しいスレッドを作成するとしますか? OOM(OutOfMemory)を超えるか、OSスレッド間の切り替えによりすべてが大幅に遅くなります(特にシングルコアシステムの場合)。 また、新しいスレッドが作成されるたびに、新しいスレッドの開始に時間を費やします。
まず、将来のスレッドプールで何らかのアクションを実行するクラスを作成する必要があります。
基本的なクラス要件:
-クラスはThreadから継承する必要があります(原則として、Runnableインターフェースのみが可能ですが、より簡単です)
-クラスは、実行のためにRunnableオブジェクトを受け入れる必要があります
-タスクの結果として例外が発生した場合、クラスは該当しません。
-タスクがない場合、スレッドは空では動作しませんが、保留状態になります
-新しいRunnableオブジェクトを追加する手順は非常に高速である必要があります。そうしないと、多数の小さなタスクがある場合、誰かがスレッドの作業をブロックするか、スレッドに新しいタスクを追加する機会を待つことになります
-まあ、それはThreadSafeでなければなりません
コードは次のとおりです。
import java.util.ArrayList; import java.util.List; class BacklogWorker extends Thread { /* */ private final LinkedList<Runnable> backlog = new LinkedList<Runnable>(); private static final int INITIAL_CAPACITY = 100; /* , */ private final List<Runnable> workQueue = new ArrayList<Runnable>(INITIAL_CAPACITY); BacklogWorker(String name) { super(name); } /* */ synchronized void enque(Runnable work) { if (work != null) { backlog.add(work); } notify(); } public void run() { while (!isInterrupted()) { /* , */ synchronized (this) { if (backlog.isEmpty()) { try { wait(); } catch (InterruptedException e) { interrupt(); } } int size = backlog.size(); for (int i = 0; i < INITIAL_CAPACITY && i < size; i++) { workQueue.add(backlog.poll()); } backlog.clear(); } for (Runnable task : workQueue) { try { task.run(); } catch (RuntimeException e) { e.printStackTrace(); } } workQueue.clear(); } } }
次に、スレッド間で作業を分散するThreadPoolを作成する必要があります。
クラスの要件は次のとおりです。
-ThreadSafe
-スケーラブル
-タスクの作業スレッド間の均一な分布
-ブロックされていません
コードは次のとおりです。
import java.util.concurrent.Executor; public class BacklogThreadPool implements Executor/*i don't use anything from concurrent, just only one interface*/ { private final BacklogWorker workers[]; private final int mask; private static volatile int sequence; public BacklogThreadPool(int threadCount, String id) { int tc; for (tc = 1; tc < threadCount; tc <<= 1) ; mask = tc - 1; if (id == null) { id = Integer.toString(getSequence()); } workers = new BacklogWorker[tc]; for (int i = 0; i < tc; i++) { workers[i] = new BacklogWorker((new StringBuilder()).append("thead-pool-worker-").append(id).append(":").append(i).toString()); workers[i].start(); } } private synchronized int getSequence() { return sequence++; } public void shutdown() { for (int i = 0; i < workers.length; i++) workers[i].interrupt(); } @Override public void execute(Runnable command) { workers[command.hashCode() & mask].enque(command); } }
原則として、ここではすべてが明確であり、おそらくコメントする必要はありません。
次に、ThreadPoolで実行されるタスクを作成する必要があります。
残念ながら、最初のバージョンは私にとって失われたので、すぐに書かれたバージョンを再び持ってきました。
import java.io.File; import java.util.ArrayList; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; public class WalkinTask1 implements BacklogTask { private List<File> dirs; private ParseHandler parseHandler; public WalkinTask1(List<File> dirs, ParseHandler parseHandler) { this.parseHandler = parseHandler; //this.parseHandler.taskStart(); this.parseHandler.taskStartUnblock(); this.dirs = dirs; } @Override public void run() { try { List<String> filePaths = new ArrayList<String>(); List<File> dirPaths = new ArrayList<File>(); for (File dir : dirs) { if (!dirPaths.isEmpty()) { dirPaths = new ArrayList<File>(); } if (!filePaths.isEmpty()) { filePaths = new ArrayList<String>(); } File listFile[] = dir.listFiles(); if (listFile != null) { for (File file : listFile) { if (file.isDirectory()) { dirPaths.add(file); } else { filePaths.add(file.getPath()); } } } if (!dirPaths.isEmpty()) { parseHandler.schedule(TaskFactory.createWalking1Task(parseHandler, dirPaths)); } if (!filePaths.isEmpty()) { Pattern pattern = parseHandler.getPattern(); List<String> result = new ArrayList<String>(); for (String path : filePaths) { Matcher matcher = pattern.matcher(path); while (matcher.find()) { String str = matcher.group(); if (!"".equals(str)) { result.add(str); } } } parseHandler.taskComplete(result); } } } finally { //parseHandler.taskFinish(); parseHandler.taskFinishUnblock(); } } @Override public int getTaskType() { return 1; //TODO } }
次に、プロファイラーについて少し話しましょう。 私がそれを必要とする理由、私は説明しません、あなたがそのような獣について何も聞いていないなら、あなたはあなた自身を捜すことができます。 マルチスレッドアプリケーションをプロファイリングする場合、使用状況の監視に最も注意を払う必要があります(各プロファイラーにはそのような機会があります)。 通常、このタイプのプロファイリングは手動で開始する必要があります。 興味深いのは、これらのスレッドまたは他のスレッドがロックを予測してハングする時間です。 たとえば、多数のスレッドを作成できますが、それらはすべて何らかのロックに陥り、システムのパフォーマンスは劇的に低下します。 また、CPUの使用にも注意を払う価値があります。たとえば、CPUが10〜20%を使用している場合、これはスレッドが計算を実行するよりも多くのロックを期待することを意味します(常にそうではありません)。
プロファイラーで結果を見てみましょう:
プログラム実行時間:
合計タスク:78687
55188ms
その結果、作業速度は約3倍に増加しました。
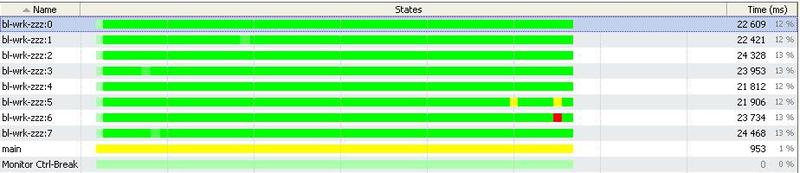
ここでは、スレッドプール内のすべてのスレッドがほぼすべての時間で作業で忙しかったことがわかります。 スレッドロックはほとんどありません。

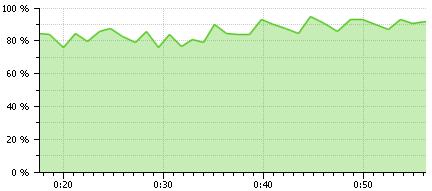
2番目の図では、CPUがほとんどの時間をIOに費やしていることがわかります。

ここでは、CPU使用率が80%を超えていることがわかります。
ここでは、1ミリ秒未満で1つのスレッドロックのみが表示され、78,000タスクが非常に良い結果をもたらしました。
ご覧のように、原則として、すべてのスレッドにほぼ完全に作業がロードされるため、CPUをロードし、ダウンタイムは発生しません。 ロックにはロックがありません。
画像番号2を見ると面白いでしょう。見てわかるように、最も「高価な」操作はjava.io.File.isDirectory()であり、合計時間の約46%がかかります。 この問題についてグーグルで調べたところ、Java7を使用する機能、または依存性のあるOS機能以外には何も見つかりませんでした。 したがって、私が見るように、この部分を最適化する機能はもうありません。 次にパーサー-java.util.regex.Matcher.find()が来ますが、ここではすでに高速化できます。 解析のみを処理する別のタスクを作成できます。 つまり 最も困難な2つの操作を分離します。
1)ファイルシステムを操作する
2)名前解析
3番目の操作もIOです。これも高速化が困難です。
したがって、最初のタスクを少し変更して、新しいタスクを追加します。
import java.io.File; import java.util.ArrayList; import java.util.List; public class WalkinTask implements BacklogTask { private List<File> dirs; private ParseHandler parseHandler; public WalkinTask(List<File> dirs, ParseHandler parseHandler) { this.parseHandler = parseHandler; //this.parseHandler.taskStart(); this.parseHandler.taskStartUnblock(); this.dirs = dirs; } @Override public void run() { try { List<String> filePaths = new ArrayList<String>(); List<File> dirPaths = new ArrayList<File>(); for (File dir : dirs) { if (!dirPaths.isEmpty()) { dirPaths = new ArrayList<File>(); } if (!filePaths.isEmpty()) { filePaths = new ArrayList<String>(); } File listFile[] = dir.listFiles(); if (listFile != null) { for (File file : listFile) { if (file.isDirectory()) { dirPaths.add(file); } else { filePaths.add(file.getPath()); } } } if (!dirPaths.isEmpty()) { parseHandler.schedule(TaskFactory.createWalkingTask(parseHandler, dirPaths)); } if (!filePaths.isEmpty()) { parseHandler.schedule(TaskFactory.createParseTask(parseHandler, filePaths)); } } } finally { //parseHandler.taskFinish(); parseHandler.taskFinishUnblock(); } } @Override public int getTaskType() { return 1; //TODO } }
import java.util.ArrayList; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; public class ParseTask implements BacklogTask { private ParseHandler handler; private List<String> paths; public ParseTask(ParseHandler hander, List<String> paths) { this.handler = hander; this.paths = paths; handler.taskStartUnblock(); } @Override public void run() { try { Pattern pattern = handler.getPattern(); List<String> result = new ArrayList<String>(); for (String path : paths) { Matcher matcher = pattern.matcher(path); while (matcher.find()) { String str = matcher.group(); if (!"".equals(str)) { result.add(str); } } } handler.taskComplete(result); } finally { handler.taskFinishUnblock(); } } @Override public int getTaskType() { return 0; } }
そして再度実行します:
合計タスク:221560
52328

ご覧のとおり、結果は最初の起動時と大差はありませんでしたが、それでも少し高速です。特に、多数のファイルがあるディレクトリがある場合は、ゲインが増加します。 しかし、このアプローチでは、タスクの数をほぼ3倍に増やしました。これは、たとえば、ガベージコレクターに影響を与える可能性があります。 したがって、ここでは、最大のパフォーマンスまたはメモリとリソースの節約という目的を選択する必要があります。
次に、プログラムを終了する方法と、結果を返す方法について考える必要があります。 私たちはたくさんのタスクを作成しましたが、それらすべてがいつ完了するかはわかりません。 タスクの合計数を計算するだけで、カウンターがゼロになるまで待ちます。 このためには、値を蓄積する変数が必要です。 しかし、ここでも、それほど単純ではありません。 たとえば、通常の変数を取得して、タスクの作成時に変数をインクリメントし、タスクの終了時に変数をデクリメントします。 しかし、このアプローチでは、結果は悲惨なものになります。 Javaでは、切望されているvolatile修飾子を指定しても、i ++操作はアトミックではありません。 AtomicItegerを取るのが理想ですが、条件によってはutil.concurrentパッケージを使用できません。 したがって、アトミックを作成する必要があります。 JavaでAtomicがどのように機能するかを詳しく調べてみると、ネイティブメソッドが見つかります。 変数の変更自体のアトミックな性質はプロセッサコマンドとして実装されるため、javaはネイティブOSコマンドを呼び出します。ネイティブOSコマンドはすでにプロセッサコマンドを呼び出しています。
基本的に、通常の同期を使用できます。 しかし、タスクの数が多いと、ロックレースが始まり、生産性が低下します(もちろん重要ではありません)。 CASアルゴリズムを実装するサンプルコードを次に示します(コードはibmのWebサイトで見つかりました)。
public class SimulatedCAS { private volatile int value; public synchronized int getValue() { return value; } public synchronized int compareAndSwap(int expectedValue, int newValue) { int oldValue = value; if (value == expectedValue) value = newValue; return oldValue; } }
public class CasCounter { private SimulatedCAS value = new SimulatedCAS(); public int getValue() { return value.getValue(); } public int increment() { int oldValue = value.getValue(); while (value.compareAndSwap(oldValue, oldValue + 1) != oldValue) oldValue = value.getValue(); return oldValue + 1; } public int decrement() { int oldValue = value.getValue(); while (value.compareAndSwap(oldValue, oldValue - 1) != oldValue) oldValue = value.getValue(); return oldValue - 1; } }
それだけです。
ソース付きアーカイブ: リンク
PS Linuxと4コアプロセッサのWindowsでテストしました。 プール内のスレッドの最適数は実験的に計算されました-16、つまり コアの数* 4、かつてインターネット上でそのような式を見つけましたが、どこにあるか覚えていません。 Windowsには機能があります。初めて起動すると、すべてが非常に長時間動作し、多くの場合すべてがIOでハングしますが、2回目の起動時にはすでにすべてが高速に動作します。これはファイルシステムをキャッシュするOSの機能だと思います。 2回目以降はすべてをテストし、プロファイラーでCPU使用率を調べました。どこかにCPU障害がある場合、このテストは不正確であると考え、統計ではこのテストを使用しませんでした。 プロジェクトフォルダー(すべての大規模プロジェクトとCVSファイル)ですべてをテストしました。
PSSこれはハブに関する私の最初の大きなトピックですので、設計についてはあまり批判しないでください。可能な場合は修正します。