MS SQL Server 2000でストアドプロシージャをコンパイルする場合、ストアドプロシージャはプロシージャキャッシュに配置されます。これは、ストアドプロシージャコードの解析、最適化、およびコンパイルの必要性を排除することにより、実行時のパフォーマンスを向上させるのに役立ちます。
一方、逆の効果をもたらす可能性がある落とし穴は、ストアドプロシージャのコンパイルされたコードのストレージに隠されています。
事実、ストアドプロシージャをコンパイルすると、プロシージャコードを構成する演算子の実行計画がそれぞれコンパイルされ、コンパイルされたストアドプロシージャがキャッシュされると、その実行計画もキャッシュされるため、ストアドプロシージャは特定の状況とクエリパラメーターに対して最適化されません。
これを実証するために小さな実験を実施します。
ステップ1 。 データベースの作成。
実験のために、別のデータベースを作成します。
CREATE DATABASE test_sp_perf
オン(NAME = 'test_data'、FILENAME = 'c:\ temp \ test_data'、SIZE = 1、MAXSIZE = 10、FILEGROWTH = 1Mb)
ログオン(NAME = 'test_log'、FILENAME = 'c:\ temp \ test_log'、SIZE = 1、MAXSIZE = 10、FILEGROWTH = 1Mb)
ステップ2.テーブルを作成します。
CREATE TABLE sp_perf_test(column1 int、column2 char(5000))
ステップ3.テーブルにテスト行を入力します。 重複行は意図的にテーブルに追加されます。 1〜10,000の番号を持つ10,000行、および50,000の番号を持つ10,000行。
DECLARE @i int
SET @ i = 1
一方で(@i <10000)
開始
INSERT INTO sp_perf_test(column1、column2)VALUES(@ i、 'Test string#' + CAST(@i as char(8)))
INSERT INTO sp_perf_test(column1、column2)VALUES(50000、 'Test string#' + CAST(@i as char(8)))
SET @ i = @ i + 1
終了
SELECT COUNT(*)FROM sp_perf_test
行く
ステップ4.非クラスター化インデックスの作成。 実行計画はプロシージャとともにキャッシュされるため、インデックスはすべての呼び出しで同じように使用されます。
sp_perf_testのCL_perf_test ONの非クラスター化インデックスの作成(column1)
行く
ステップ5.ストアドプロシージャの作成。 プロシージャは、条件を使用してSELECTステートメントを実行するだけです。
CREATE PROC proc1(@param int)
として
SELECT column1、column2 FROM sp_perf_test WHERE column1 = @ param
行く
ステップ6.ストアドプロシージャを開始します。 脆弱な手順を開始する場合、選択的なパラメーターが特別に使用されます。 手順の結果、1行が取得されます。 実行計画は、非クラスター化インデックスの使用を次のように示します。 クエリは選択的であり、これが文字列を抽出する最良の方法です。 単一の行をフェッチするために最適化されたプロシージャは、プロシージャキャッシュに格納されます。
EXEC proc1 1234
行く

ステップ7.非選択パラメーターを使用してストアード・プロシージャーを開始します。 パラメーターとして50,000の値が使用されます。このような最初の列の値がそれぞれ約10,000の行は、非クラスター化インデックスを使用し、ブックマークルックアップ操作は非効率的ですが、実行プランを含むコンパイル済みコードは手続き型キャッシュに格納されるため、使用されます。 実行計画には、これと、ブックマークの検索操作が9999行に対して実行されたという事実が示されています。
EXEC proc1 50,000
行く

ステップ8.最初のフィールドが50,000に等しい行をフェッチする別のクエリを実行する場合、クエリは最適化され、最初の列の特定の値でコンパイルされます。 その結果、クエリオプティマイザーはフィールドが何度も複製されていると判断し、テーブルスキャン操作の使用を決定します。この場合、非クラスター化インデックスを使用するよりもはるかに効率的です。
SELECT column1、column2 FROM sp_perf_test WHERE column1 = 50000
行く
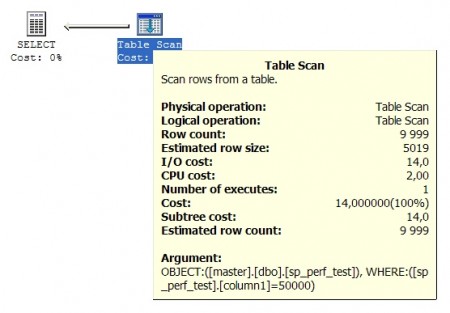
したがって、ストアドプロシージャを使用してもクエリのパフォーマンスが常に向上するとは限りません。 可変数の行で結果を処理し、異なる実行プランを使用するストアドプロシージャについては、十分に注意する必要があります。
スクリプトを使用して、MS SQLサーバーで実験を繰り返すことができます。