ツールキット自体はNDEVと呼ばれます。 必要なコード(それだけでは十分ではありません)とドキュメント(たくさんあります)を入手するには、「協力プログラム」のサイトに登録する必要があります。 ウェブサイト:
dragonmobile.nuancemobiledeveloper.com/public/index.php
アプリケーションのクライアントが50万人未満で、1日20回未満のサービスを使用している場合、これはすべて「hem」です。 登録後すぐに、シルバーメンバーシップが提供され、これらのサービスを無料で使用できます。
開発者には、音声認識および音声合成サービスをiOSアプリケーションに導入するための段階的な手順が提供されます。
Toolkit(SDK)には、クライアントコンポーネントとサーバーコンポーネントの両方が含まれています。 図は、トップレベルでの相互作用を示しています。
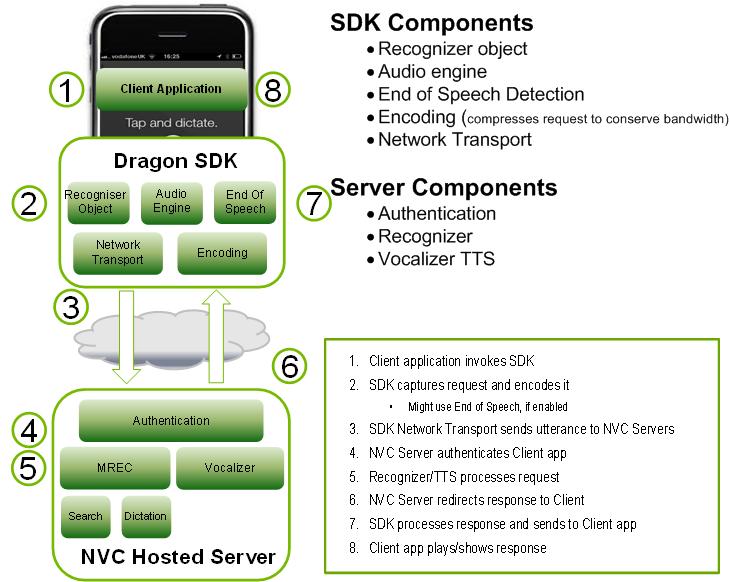
Dragon Mobile SDKは、さまざまなコードサンプルとプロジェクトテンプレート、ドキュメント、および音声サービスのあらゆるアプリケーションへの統合を簡素化するソフトウェアプラットフォーム(フレームワーク)で構成されています。
Speech Kitフレームワークを使用すると、音声認識および合成(TTS、Text-to-Speech)サービスをアプリケーションに簡単かつ迅速に追加できます。 このプラットフォームは、非同期の「クリーンな」ネットワークAPIを介してサーバー上にある音声処理コンポーネントへのアクセスも提供し、オーバーヘッドとリソース消費を最小限に抑えます。
Speech Kitプラットフォームは、すべての低レベルサービスを自動的に管理するフル機能の高レベル「フレームワーク」です。
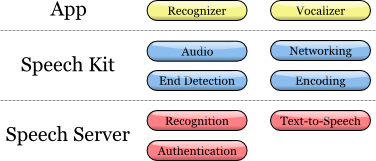
音声キットのアーキテクチャ
本体
開発者は、アプリケーションレベルで、音声認識とテキストからの音声合成という2つの主要なサービスを利用できます。
プラットフォームは、いくつかの調整されたプロセスを実行します。
録音および再生用のオーディオシステムを完全に制御します
ネットワークコンポーネントはサーバーへの接続を管理し、新しいリクエストごとにタイムアウトの期限が切れた接続を自動的に復元します
音声終了検出器は、ユーザーが発言を終了したことを検出し、必要に応じて録音を自動的に停止
エンコードコンポーネントは、ストリーミングオーディオ録音を圧縮および圧縮解除し、帯域幅要件を減らし、平均遅延時間を減らします。
サーバーシステムは、音声処理サイクルに関係するほとんどの操作を担当します。 音声認識または音声合成のプロセスは、サーバー上で完全に実行され、音声ストリームを処理または合成します。 さらに、サーバーは開発者の構成に従って認証します。
この記事では、iOS開発に焦点を当てます。 Speech Kitフレームワークは、FoundationやUIKitなどの標準的なiPhoneソフトウェアプラットフォームと同様に使用できます。 唯一の違いは、Speech Kitは静的フレームワークであり、アプリケーションのコンパイルに完全に含まれていることです。 Speech Kitは、iPhone OSの主要なオペレーティングコンポーネントのいくつかに直接関連しています。これらのコンポーネントは、アプリケーションの実行中に利用できるように、アプリケーションに相互依存として含める必要があります。 Foundationに加えて、XcodeプロジェクトにSystem ConfigurationおよびAudio Toolboxコンポーネントを追加する必要があります。
1.プロジェクト内のソフトウェアグループフレームワークを選択することから始めます
2.次に、「Frameworks」を右クリックして、表示されるメニューをクリックします。追加‣既存のフレームワーク...
3.最後に、必要なフレームワークを選択し、[追加]ボタンをクリックします。 選択したプラットフォームがFrameworksフォルダーに表示されます(上の図を参照)。
SpeechKitソフトウェアプラットフォームの使用を開始するには、新規または既存のプロジェクトに追加します。
1.プロジェクトを開き、Speech Kitプラットフォームを配置するグループを選択します(例:ファイル:フレームワーク)。
2.メニューから、プロジェクト‣プロジェクトに追加...を選択します。
3.次に、Dragon Mobile SDKツールキットを解凍した「SpeechKit.framework」フレームワークを見つけて、[追加]を選択します。
4. Speech Kitがプロジェクト内にあり、元の場所を参照していないことを確認するには、[アイテムのコピー...]を選択してから[追加]を選択します。
5.ご覧のとおり、Speech Kitプラットフォームがプロジェクトに追加されました。これを展開して、パブリックヘッダーにアクセスできます。
Speech Kitに必要なプラットフォーム
Speech Kitフレームワークは、クラスと定数までの完全なアプリケーションプログラミングインターフェイス(API)へのアクセスを提供する1つのトップレベルヘッダーを提供します。 Speech Kitサービスを使用する予定のすべてのソースファイルにSpeech Kitヘッダーをインポートする必要があります。
#import <SpeechKit / SpeechKit.h>
これで、テキストの認識と音声への変換(音声合成)のサービスの使用を開始できます。
Speech Kitプラットフォームはネットワークサービスであり、音声認識または音声合成クラスを使用する前にいくつかの基本設定が必要です。
このインストールは、2つの基本操作を実行します。
最初に、アプリケーションを識別して承認します。
第二に、-音声サーバーとの接続を確立します。-これにより、音声処理を迅速に要求できるため、ユーザーサービスの品質が向上します。
ご注意
指定されたネットワーク接続には、開発者が指定した資格情報とサーバー設定の承認が必要です。 必要な資格情報は、Dragon Mobile SDKポータルdragonmobile.nuancemobiledeveloper.comから提供されます。
インストールキットのセットアップ
SpeechKitApplicationKeyアプリケーションキーは、ソフトウェアプラットフォームによって要求され、開発者がインストールする必要があります。 キーは、音声処理サーバーのアプリケーションのパスワードとして機能し、誤用を防ぐために秘密にしておく必要があります。
開発者ポータルを介して提供されるアプリケーションキーを含む固有の資格情報には、これらの権限を設定するための追加のコード行が必要です。 したがって、プロセスはソースファイルの行のコピーと貼り付けに要約されます。 Speech Kitシステムを初期化する前に、アプリケーションキーをインストールする必要があります。 たとえば、次のようにアプリケーションキーを設定できます。
const unsigned char [] SpeechKitApplicationKey = {0x12、0x34、...、0x89};
インストール方法setupWithID:host:portには、3つのパラメーターが含まれています。
アプリケーションID
サーバーアドレス
ポート
IDパラメーターはアプリケーションを識別し、アプリケーションキーと組み合わせて使用され、音声サーバーへのアクセスの承認を提供します。
ホストとポートのパラメーターは、音声サーバーによって設定されますが、アプリケーションごとに異なる場合があります。 したがって、認証パラメーターで指定された値を常に使用する必要があります。
フレームワークは、次の例を使用して構成されます。
[SpeechKit setupWithID:@ "NMDPTRIAL_Acme20100604154233_aaea77bc5b900dc4005faae89f60a029214d450b"
ホスト:@ "10.0.0.100"
ポート:443];
ご注意
setupWithID:host:portメソッドはクラスメソッドであり、オブジェクト(インスタンス)を生成しません。 このメソッドは、アプリケーションの実行中に1回限りの呼び出し用に設計されており、メインネットワーク接続をセットアップします。 これは、バックグラウンドで実行され、接続を確立し、承認を実行する非同期メソッドです。 このメソッドは、接続/許可エラーを報告しません。 このインストールの成功または失敗は、SKRecognizerクラスとSKVocalizerクラスを使用してわかります。
この時点で、音声サーバーは完全に構成され、プラットフォームは接続の確立を開始します。 この接続はしばらくの間開いたままになり、音声サービスがアクティブに使用されるまで、後続の音声要求が迅速に処理されることが保証されます。 接続がタイムアウトになると、接続は中断されますが、次の音声要求と同時に自動的に復元されます。
アプリケーションが構成され、音声を認識して合成する準備ができました。
音声認識
認識テクノロジーにより、ユーザーは通常テキスト入力が必要な場所で入力する代わりに口述することができます。 音声認識エンジンは、テキスト結果のリストを提供します。 いかなる方法でもユーザーインターフェイス(UI)オブジェクトに関連付けられていないため、最適な結果の選択および代替結果の選択は、各アプリケーションのユーザーインターフェイスの裁量にとどまります。
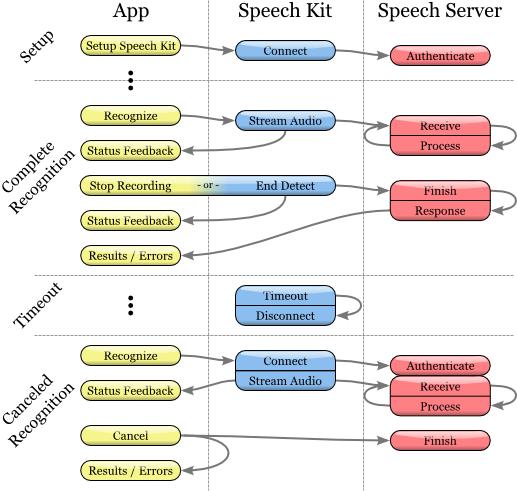
音声認識プロセス
認識開始
1.音声認識サービスを使用する前に、setupWithID:host:portメソッドを使用して元のSpeech Kitプラットフォームを構成したことを確認してください。
2.次に、SKRecognizerオブジェクトを作成して初期化します。
3.認識機能= [[SKRecognizer alloc] initWithType:SKSearchRecognizerType
4.検出:SKShortEndOfSpeechDetection
5.言語:@ "en_US"
6.委任:自己];
7. initWithType:detection:language:デリゲートメソッドは、認識エンジンを初期化し、音声認識プロセスを開始します。
典型的なパラメーターはNSString *です。これは、Speech Kitプラットフォームによって定義され、SKRecognizer.hヘッダーからアクセスできる典型的な認識定数の1つです。 Nuanceは、独自の認識ニーズに合わせて他の値を提供する場合があります。その場合、NSString拡張機能を追加する必要があります。
検出パラメーターは「音声終了検出」モデルを定義し、SKEndOfSpeechDetectionタイプのいずれかと一致する必要があります。
言語パラメーターは、音声の言語をISO 639言語コードの形式の文字列として定義し、その後にアンダースコア「_」、ISO 3166-1形式の国コードが続きます。
ご注意
たとえば、米国で話されている英語には、en_USという指定があります。 サポートされている認識言語の更新されたリストは、FAQで入手できます: dragonmobile.nuancemobiledeveloper.com/faq.php 。
8.デリゲートは、以下で説明するように、認識結果またはエラーメッセージを受け取ります。
認識結果を取得する
認識結果については、委任者の委任方法を参照してください:didFinishWithResults:
-(void)認識機能:(SKRecognizer *)認識機能didFinishWithResults:(SKRecognition *)結果{
[認識自動リリース];
//結果に基づいてアクションを実行します
}
委任方法は、プロセスが正常に完了した場合にのみ適用され、結果のリストには0個以上の結果が含まれます。 最初の結果は、firstResultメソッドを使用して常に見つけることができます。 エラーがなくても、認識結果オブジェクトに存在する音声サーバーからのアドバイス(提案)があります。 このようなアドバイス(提案)は、ユーザーに提示する必要があります。
エラー処理
認識エラーに関する情報を取得するには、委任メソッド認識エンジン:didFinishWithError:suggestion:を使用します。 エラーが発生した場合、このメソッドのみが呼び出されます。 逆に、成功した場合、このメソッドは呼び出されません。 前のセクションで説明したように、エラーに加えて、結果としてアドバイスが表示される場合と表示されない場合があります。
-(void)認識機能:(SKRecognizer *)認識機能didFinishWithError:(NSError *)エラーの提案:(NSString *)提案{
[認識自動リリース];
//エラーとアドバイスについてユーザーに通知します
}
レコーディングステージ管理
認識エンジンがオーディオの録音を開始または停止するタイミングに関する情報を受け取りたい場合は、委任メソッドacknowledgerDidBeginRecording:およびacknowledgerDidFinishRecording:を使用します。 したがって、認識の初期化と記録の実際の開始との間に遅延が生じる場合があり、メッセージacknowledgerDidBeginRecording:は、システムがリッスンする準備ができていることをユーザーに知らせる場合があります。
-(void)認識器DidBeginRecording:(SKRecognizer *)認識器{
// UIを更新して、システムが記録中であることを示します
}
音声認識サーバーが音声ファイルの受信と処理を完了する前、つまり結果が利用可能になる前に、recognizerDidFinishRecording:メッセージが送信されます。
-(void)認識器DidFinishRecording:(SKRecognizer *)認識器{
// UIを更新して、録音が停止し、音声がまだ処理中であることを示します
}
このメッセージは、記録終了検出モデルの存在に関係なく送信されます。 メッセージは、stopRecordingメソッドが呼び出されたときと同じ方法で、記録の終了を検出する信号によって送信されます。
「サウンドアイコン」(信号)のインストール
さらに、「サウンドアイコン」を使用して、録音の前後および録音セッションのキャンセル後に音声信号を再生できます。 SKEarconオブジェクトを作成し、Speech KitプラットフォームのsetEarcon:forType:メソッドを設定する必要があります。 次の例は、サンプルアプリケーションで「サウンドアイコン」を設定する方法を示しています。
-(void)setEarcons {
//「サウンドアイコン」を再生します
SKEarcon * earconStart = [SKEarcon earconWithName:@ "earcon_listening.wav"];
SKEarcon * earconStop = [SKEarcon earconWithName:@ "earcon_done_listening.wav"];
SKEarcon * earconCancel = [SKEarcon earconWithName:@ "earcon_cancel.wav"];
[SpeechKit setEarcon:earconStart forType:SKStartRecordingEarconType];
[SpeechKit setEarcon:earconStop forType:SKStopRecordingEarconType];
[SpeechKit setEarcon:earconCancel forType:SKCancelRecordingEarconType];
}
より高いレベルのコードブロックが呼び出されると(setupWithID:host:portメソッドを使用してSpeech Kitメインソフトウェアプラットフォームを構成した後)、録音プロセスが開始する前にearcon_listening.wavオーディオファイルが再生され、録音が完了するとearcon_done_listening.wavオーディオファイルが再生されます。 録音セッションが拒否された場合、earcon_cancel.wav「ユーザー用のオーディオファイルが再生されます。メソッド `` earconWithName:は、デバイスでサポートされているオーディオファイルに対してのみ機能します。
サウンドレベルディスプレイ
場合によっては、特に長時間ディクテーション中に、ユーザーに自分のスピーチの音響パワーを視覚的に表示すると便利です。 サウンドレコーディングインターフェイスは、録音レベルの相対的なパワーレベルをデシベル単位で返すaudioLevel属性を使用する場合、この機能をサポートします。 この値の範囲は浮動小数点で特徴付けられ、0.0〜-90.0 dBの範囲にあります。0.0は最高のパワーレベルで、-90.0は音響パワーの下限です。 この属性は、記録中、特にメッセージacknowledgerDidBeginRecording:とacknowledgerDidFinishRecordingの受信の間で使用可能である必要があります。 通常、定期的に電力レベルを表示するには、performSelector:withObject:afterDelay:などのタイマーメソッドを使用する必要があります。
テキスト読み上げ
SKVocalizerクラスは、開発者に音声合成ネットワークインターフェイスを提供します。
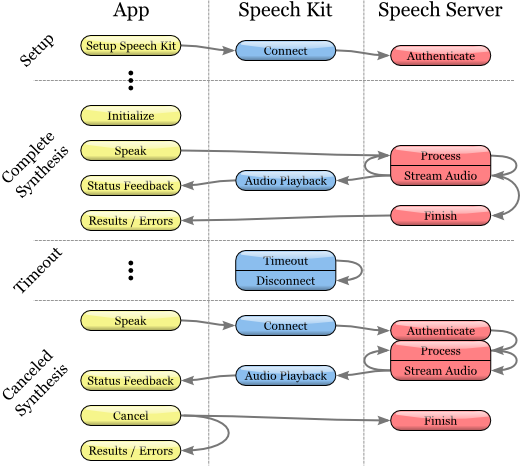
音声合成プロセス
音声合成プロセスの初期化
1.音声合成サービスの使用を開始する前に、setupWithID:host:portメソッドを使用して、音声キットによってメインソフトウェアプラットフォームが構成されていることを確認します。
2.次に、SKVocalizerオブジェクトを作成および初期化して、テキストを音声に変換します。
3. vocalizer = [[SKVocalizer alloc] initWithLanguage:@ "en_US"
4.委任:自己];
5。
1.メソッドinitWithLanguage:デリゲート:音声合成サービスをデフォルト言語で初期化します。
言語パラメーターはNSString *です。これは、ISO 639形式の言語コード、アンダースコア「_」、およびISO 3166-1形式の次の国コードの形式で言語を定義します。 たとえば、米国で使用される英語の形式はen_USです。 サポートされる各言語には、男性または女性の1つ以上の固有の音声があります。
ご注意
音声合成でサポートされる言語の更新されたリストは、 dragonmobile.nuancemobiledeveloper.com / faq.phpで入手できます。 サポートされている言語のリストは、新しい言語がサポートされると更新されます。 新しい言語では、必ずしも既存のDragon Mobile SDKを更新する必要はありません。
委任されたパラメーターは、音声合成装置からステータスメッセージとエラーメッセージを受信するためのオブジェクトを定義します。
2. initWithLanguage:デリゲートメソッド:Nuanceが選択したデフォルトの音声を使用します。 別の音声を選択するには、前の音声の代わりにinitWithVoice:delegate:メソッドを使用します。
音声パラメーターはNSString *であり、サウンドモデルを定義します。 たとえば、英国英語のデフォルトの声はサマンサです。
ご注意
サポートされている言語と比較した、サポートされている投票の更新されたリストは、サイトで入手できます。
dragonmobile.nuancemobiledeveloper.com/faq.php
5.テキストを音声に変換するプロセスを開始するには、speakString:またはspeakMarkupString:メソッドを使用する必要があります。 これらのメソッドは、要求された文字列を音声サーバーに送信し、デバイスでストリーミング処理とオーディオ再生を開始します。
6. [vocalizer speakString:@ "Hello world。"]
ご注意
speakMarkupStringメソッドは、speakStringメソッドとまったく同じ方法で使用されますが、唯一の違いは、NSString *クラスが、合成音声を記述する音声合成マークアップ言語によって実行されることです。 音声合成用のマークアップ言語の最近の議論はこのドキュメントの範囲外ですが、W3Cが提供するこのトピックに関する詳細はwww.w3.org/TR/speech-synthesisで見つけることができます。
音声合成はネットワークサービスであるため、上記のメソッドは非同期です。一般に、エラーメッセージはすぐには表示されません。 エラーはすべて、デリゲートへのメッセージとして表示されます。
音声合成システムのフィードバック制御
合成された音声はすぐには再生されません。 ほとんどの場合、要求が送信されて音声サービスにリダイレクトされる時間にわずかな遅延が生じます。 オプションの委任メソッドvocalizer:willBeginSpeakingString:は、ユーザーインターフェイスを調整するために使用され、サウンドの再生開始時期を示すことを目的としています。
-(void)vocalizer:(SKVocalizer *)vocalizer willBeginSpeakingString:(NSString *)text {
//ユーザーインターフェイスを更新して、音声が開始されるタイミングを示します
}
メッセージ内のNSString *クラスは、speakStringまたはspeakMarkupStringメソッドのいずれかによって実行される元の行へのリンクとして機能し、テキストを音声に変換するための適切な要求が行われたトラックの順次再生中に使用できます。
スピーチの最後に、ボーカライザー:didFinishSpeakingString:withErrorメッセージが送信されます。 このメッセージは、再生プロセスが正常に完了した場合、およびエラーが発生した場合の両方で常に送信されます。 成功すると、エラーは「消えます」。
-(void)vocalizer:(SKVocalizer *)vocalizer didFinishSpeakingString:(NSString *)text withError:(NSError *)error {
if(error){
//ユーザーのエラーダイアログを表示する
} else {
//ユーザーインターフェイスを更新し、再生の完了を示します
}
}
これらの操作の後、適切なサービスをデバッグして使用するだけです。